 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistTGL: Distributed Memory-Based Temporal Graph Neural Network Training
Paper and Code
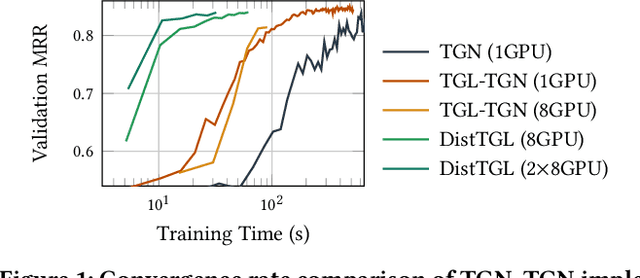



Memory-based Temporal Graph Neural Networks are powerful tools in dynamic graph representation learning and have demonstrated superior performance in many real-world applications. However, their node memory favors smaller batch sizes to capture more dependencies in graph events and needs to be maintained synchronously across all trainers. As a result, existing frameworks suffer from accuracy loss when scaling to multiple GPUs. Evenworse, the tremendous overhead to synchronize the node memory make it impractical to be deployed to distributed GPU clusters. In this work, we propose DistTGL -- an efficient and scalable solution to train memory-based TGNNs on distributed GPU clusters. DistTGL has three improvements over existing solutions: an enhanced TGNN model, a novel training algorithm, and an optimized system. In experiments, DistTGL achieves near-linear convergence speedup, outperforming state-of-the-art single-machine method by 14.5% in accuracy and 10.17x in training throughput.