 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCV2I: Communication-Efficient and High-Performance Collaborative Perception Framework with Low-Resolution LiDAR
Feb 24, 2025Vehicle-to-Infrastructure (V2I) collaborative perception leverages data collected by infrastructure's sensors to enhance vehicle perceptual capabilities. LiDAR, as a commonly used sensor in cooperative perception, is widely equipped in intelligent vehicles and infrastructure. However, its superior performance comes with a correspondingly high cost. To achieve low-cost V2I, reducing the cost of LiDAR is crucial. Therefore, we study adopting low-resolution LiDAR on the vehicle to minimize cost as much as possible. However, simply reducing the resolution of vehicle's LiDAR results in sparse point clouds, making distant small objects even more blurred. Additionally, traditional communication methods have relatively low bandwidth utilization efficiency. These factors pose challenges for us. To balance cost and perceptual accuracy, we propose a new collaborative perception framework, namely LCV2I. LCV2I uses data collected from cameras and low-resolution LiDAR as input. It also employs feature offset correction modules and regional feature enhancement algorithms to improve feature representation. Finally, we use regional difference map and regional score map to assess the value of collaboration content, thereby improving communication bandwidth efficiency. In summary, our approach achieves high perceptual performance while substantially reducing the demand for high-resolution sensors on the vehicle. To evaluate this algorithm, we conduct 3D object detection in the real-world scenario of DAIR-V2X, demonstrating that the performance of LCV2I consistently surpasses currently existing algorithms.
Sensor2Text: Enabling Natural Language Interactions for Daily Activity Tracking Using Wearable Sensors
Oct 26, 2024Visual Question-Answering, a technology that generates textual responses from an image and natural language question, has progressed significantly. Notably, it can aid in tracking and inquiring about daily activities, crucial in healthcare monitoring, especially for elderly patients or those with memory disabilities. However, video poses privacy concerns and has a limited field of view. This paper presents Sensor2Text, a model proficient in tracking daily activities and engaging in conversations using wearable sensors. The approach outlined here tackles several challenges, including low information density in wearable sensor data, insufficiency of single wearable sensors in human activities recognition, and model's limited capacity for Question-Answering and interactive conversations. To resolve these obstacles, transfer learning and student-teacher networks are utilized to leverage knowledge from visual-language models. Additionally, an encoder-decoder neural network model is devised to jointly process language and sensor data for conversational purposes. Furthermore, Large Language Models are also utilized to enable interactive capabilities. The model showcases the ability to identify human activities and engage in Q\&A dialogues using various wearable sensor modalities. It performs comparably to or better than existing visual-language models in both captioning and conversational tasks. To our knowledge, this represents the first model capable of conversing about wearable sensor data, offering an innovative approach to daily activity tracking that addresses privacy and field-of-view limitations associated with current vision-based solutions.
FLEN: Leveraging Field for Scalable CTR Prediction
Nov 12, 2019
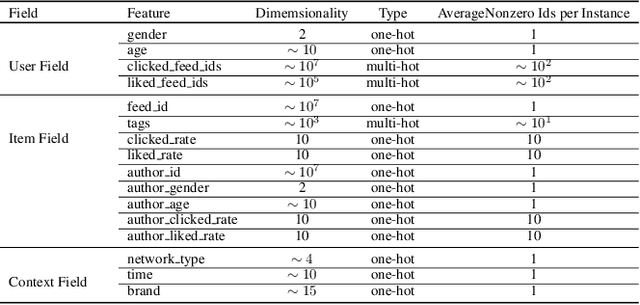
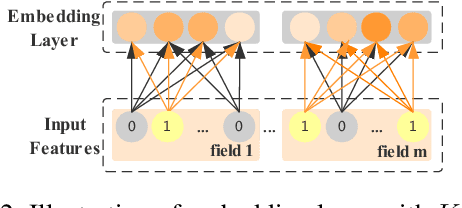

Click-Through Rate (CTR) prediction has been an indispensable component for many industrial applications, such as recommendation systems and online advertising. CTR prediction systems are usually based on multi-field categorical features, i.e., every feature is categorical and belongs to one and only one field. Modeling feature conjunctions is crucial for CTR prediction accuracy. However, it requires a massive number of parameters to explicitly model all feature conjunctions, which is not scalable for real-world production systems. In this paper, we describe a novel Field-Leveraged Embedding Network (FLEN) which has been deployed in the commercial recommender system in Meitu and serves the main traffic. FLEN devises a field-wise bi-interaction pooling technique. By suitably exploiting field information, the field-wise bi-interaction pooling captures both inter-field and intra-field feature conjunctions with a small number of model parameters and an acceptable time complexity for industrial applications. We show that a variety of state-of-the-art CTR models can be expressed under this technique. Furthermore, we develop Dicefactor: a dropout technique to prevent independent latent features from co-adapting. Extensive experiments, including offline evaluations and online A/B testing on real production systems, demonstrate the effectiveness and efficiency of proposed approaches. Notably, FLEN has obtained 5.19% improvement on CTR with 1/6 of memory usage and computation time, compared to last version (i.e. NFM).