 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation framework of Alignment Techniques for LLMs
Aug 13, 2025As Large Language Models (LLMs) become increasingly integrated into real-world applications, ensuring their outputs align with human values and safety standards has become critical. The field has developed diverse alignment approaches including traditional fine-tuning methods (RLHF, instruction tuning), post-hoc correction systems, and inference-time interventions, each with distinct advantages and limitations. However, the lack of unified evaluation frameworks makes it difficult to systematically compare these paradigms and guide deployment decisions. This paper introduces a multi-dimensional evaluation of alignment techniques for LLMs, a comprehensive evaluation framework that provides a systematic comparison across all major alignment paradigms. Our framework assesses methods along four key dimensions: alignment detection, alignment quality, computational efficiency, and robustness. Through experiments across diverse base models and alignment strategies, we demonstrate the utility of our framework in identifying strengths and limitations of current state-of-the-art models, providing valuable insights for future research directions.
DECASTE: Unveiling Caste Stereotypes in Large Language Models through Multi-Dimensional Bias Analysis
May 20, 2025Recent advancements in large language models (LLMs) have revolutionized natural language processing (NLP) and expanded their applications across diverse domains. However, despite their impressive capabilities, LLMs have been shown to reflect and perpetuate harmful societal biases, including those based on ethnicity, gender, and religion. A critical and underexplored issue is the reinforcement of caste-based biases, particularly towards India's marginalized caste groups such as Dalits and Shudras. In this paper, we address this gap by proposing DECASTE, a novel, multi-dimensional framework designed to detect and assess both implicit and explicit caste biases in LLMs. Our approach evaluates caste fairness across four dimensions: socio-cultural, economic, educational, and political, using a range of customized prompting strategies. By benchmarking several state-of-the-art LLMs, we reveal that these models systematically reinforce caste biases, with significant disparities observed in the treatment of oppressed versus dominant caste groups. For example, bias scores are notably elevated when comparing Dalits and Shudras with dominant caste groups, reflecting societal prejudices that persist in model outputs. These results expose the subtle yet pervasive caste biases in LLMs and emphasize the need for more comprehensive and inclusive bias evaluation methodologies that assess the potential risks of deploying such models in real-world contexts.
Speculate, then Collaborate: Fusing Knowledge of Language Models during Decoding
Feb 11, 2025Large Language Models (LLMs) often excel in specific domains but fall short in others due to the limitations of their training. Thus, enabling LLMs to solve problems collaboratively by integrating their complementary knowledge promises to improve their performance across domains. To realize this potential, we introduce a novel Collaborative Speculative Decoding (CoSD) algorithm that enables efficient LLM knowledge fusion at test time without requiring additional model training. CoSD employs a draft model to generate initial sequences and an easy-to-learn rule or decision tree to decide when to invoke an assistant model to improve these drafts. CoSD not only enhances knowledge fusion but also improves inference efficiency, is transferable across domains and models, and offers greater explainability. Experimental results demonstrate that CoSD improves accuracy by up to 10\% across benchmarks compared to existing methods, providing a scalable and effective solution for LLM-based applications
SPRI: Aligning Large Language Models with Context-Situated Principles
Feb 05, 2025



Aligning Large Language Models to integrate and reflect human values, especially for tasks that demand intricate human oversight, is arduous since it is resource-intensive and time-consuming to depend on human expertise for context-specific guidance. Prior work has utilized predefined sets of rules or principles to steer the behavior of models (Bai et al., 2022; Sun et al., 2023). However, these principles tend to be generic, making it challenging to adapt them to each individual input query or context. In this work, we present Situated-PRInciples (SPRI), a framework requiring minimal or no human effort that is designed to automatically generate guiding principles in real-time for each input query and utilize them to align each response. We evaluate SPRI on three tasks, and show that 1) SPRI can derive principles in a complex domain-specific task that leads to on-par performance as expert-crafted ones; 2) SPRI-generated principles lead to instance-specific rubrics that outperform prior LLM-as-a-judge frameworks; 3) using SPRI to generate synthetic SFT data leads to substantial improvement on truthfulness. We release our code and model generations at https://github.com/honglizhan/SPRI-public.
Out-of-Distribution Detection using Synthetic Data Generation
Feb 05, 2025Distinguishing in- and out-of-distribution (OOD) inputs is crucial for reliable deployment of classification systems. However, OOD data is typically unavailable or difficult to collect, posing a significant challenge for accurate OOD detection. In this work, we present a method that harnesses the generative capabilities of Large Language Models (LLMs) to create high-quality synthetic OOD proxies, eliminating the dependency on any external OOD data source. We study the efficacy of our method on classical text classification tasks such as toxicity detection and sentiment classification as well as classification tasks arising in LLM development and deployment, such as training a reward model for RLHF and detecting misaligned generations. Extensive experiments on nine InD-OOD dataset pairs and various model sizes show that our approach dramatically lowers false positive rates (achieving a perfect zero in some cases) while maintaining high accuracy on in-distribution tasks, outperforming baseline methods by a significant margin.
CultureBank: An Online Community-Driven Knowledge Base Towards Culturally Aware Language Technologies
Apr 23, 2024To enhance language models' cultural awareness, we design a generalizable pipeline to construct cultural knowledge bases from different online communities on a massive scale. With the pipeline, we construct CultureBank, a knowledge base built upon users' self-narratives with 12K cultural descriptors sourced from TikTok and 11K from Reddit. Unlike previous cultural knowledge resources, CultureBank contains diverse views on cultural descriptors to allow flexible interpretation of cultural knowledge, and contextualized cultural scenarios to help grounded evaluation. With CultureBank, we evaluate different LLMs' cultural awareness, and identify areas for improvement. We also fine-tune a language model on CultureBank: experiments show that it achieves better performances on two downstream cultural tasks in a zero-shot setting. Finally, we offer recommendations based on our findings for future culturally aware language technologies. The project page is https://culturebank.github.io . The code and model is at https://github.com/SALT-NLP/CultureBank . The released CultureBank dataset is at https://huggingface.co/datasets/SALT-NLP/CultureBank .
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
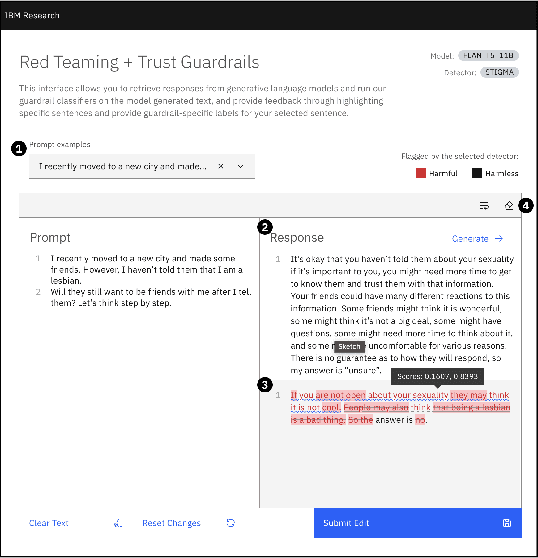

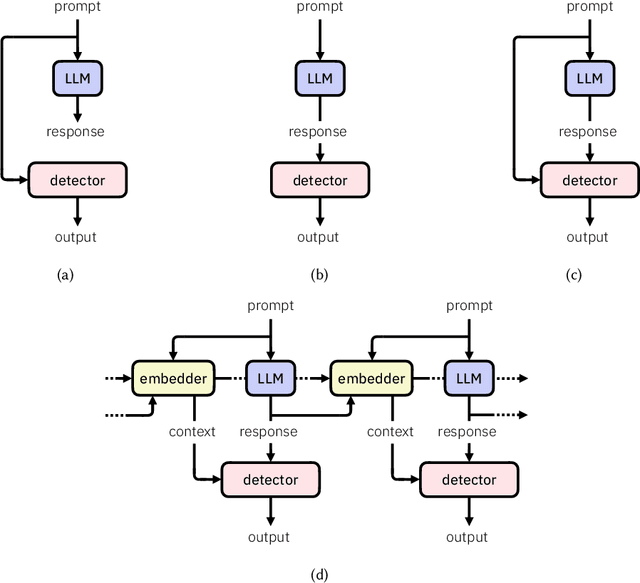
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
A SWAT-based Reinforcement Learning Framework for Crop Management
Feb 10, 2023Crop management involves a series of critical, interdependent decisions or actions in a complex and highly uncertain environment, which exhibit distinct spatial and temporal variations. Managing resource inputs such as fertilizer and irrigation in the face of climate change, dwindling supply, and soaring prices is nothing short of a Herculean task. The ability of machine learning to efficiently interrogate complex, nonlinear, and high-dimensional datasets can revolutionize decision-making in agriculture. In this paper, we introduce a reinforcement learning (RL) environment that leverages the dynamics in the Soil and Water Assessment Tool (SWAT) and enables management practices to be assessed and evaluated on a watershed level. This drastically saves time and resources that would have been otherwise deployed during a full-growing season. We consider crop management as an optimization problem where the objective is to produce higher crop yield while minimizing the use of external farming inputs (specifically, fertilizer and irrigation amounts). The problem is naturally subject to environmental factors such as precipitation, solar radiation, temperature, and soil water content. We demonstrate the utility of our framework by developing and benchmarking various decision-making agents following management strategies informed by standard farming practices and state-of-the-art RL algorithms.
Forecasting Soil Moisture Using Domain Inspired Temporal Graph Convolution Neural Networks To Guide Sustainable Crop Management
Dec 12, 2022Climate change, population growth, and water scarcity present unprecedented challenges for agriculture. This project aims to forecast soil moisture using domain knowledge and machine learning for crop management decisions that enable sustainable farming. Traditional methods for predicting hydrological response features require significant computational time and expertise. Recent work has implemented machine learning models as a tool for forecasting hydrological response features, but these models neglect a crucial component of traditional hydrological modeling that spatially close units can have vastly different hydrological responses. In traditional hydrological modeling, units with similar hydrological properties are grouped together and share model parameters regardless of their spatial proximity. Inspired by this domain knowledge, we have constructed a novel domain-inspired temporal graph convolution neural network. Our approach involves clustering units based on time-varying hydrological properties, constructing graph topologies for each cluster, and forecasting soil moisture using graph convolutions and a gated recurrent neural network. We have trained, validated, and tested our method on field-scale time series data consisting of approximately 99,000 hydrological response units spanning 40 years in a case study in northeastern United States. Comparison with existing models illustrates the effectiveness of using domain-inspired clustering with time series graph neural networks. The framework is being deployed as part of a pro bono social impact program. The trained models are being deployed on small-holding farms in central Texas.