 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Free Adversarial Transfer via Undertrained Surrogates
Paper and Code
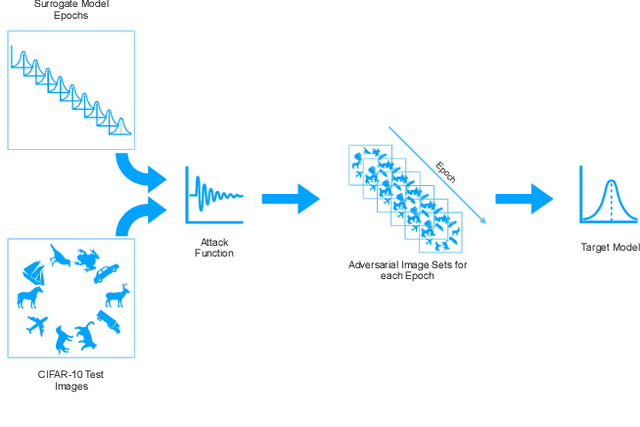
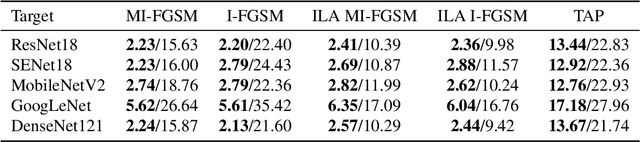

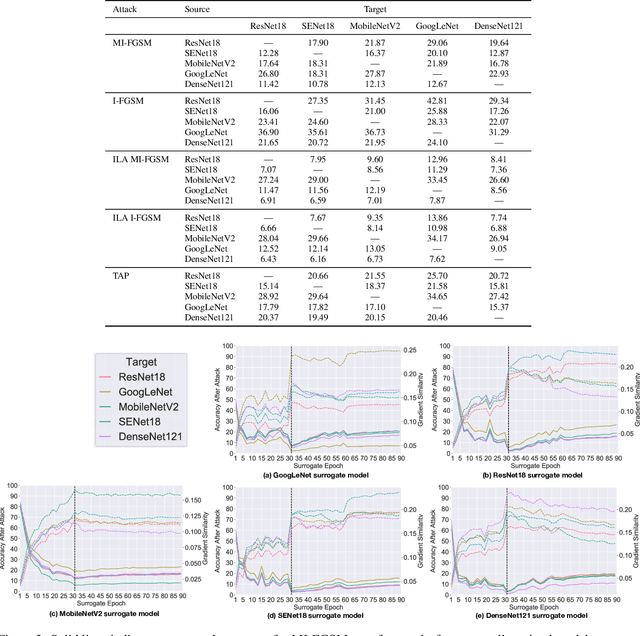
Deep neural networks have been shown to be highly vulnerable to adversarial examples---minor perturbations added to a model's input which cause the model to output an incorrect prediction. This vulnerability represents both a risk for the use of deep learning models in security-conscious fields and an opportunity to improve our understanding of how deep networks generalize to unexpected inputs. In a transfer attack, the adversary builds an adversarial attack using a surrogate model, then uses that attack to fool an unseen target model. Recent work in this subfield has focused on attack generation methods which can improve transferability between models. We show that optimizing a single surrogate model is a more effective method of improving adversarial transfer, using the simple example of an undertrained surrogate. This method transfers well across varied architectures and outperforms state-of-the-art methods. To interpret the effectiveness of undertrained surrogate models, we represent adversarial transferability as a function of surrogate model loss function curvature and similarity between surrogate and target gradients and show that our approach reduces the presence of local loss maxima which hinder transferability. Our results suggest that finding good single surrogate models is a highly effective and simple method for generating transferable adversarial attacks, and that this method represents a valuable route for future study in this field.