 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan you pass that tool?: Implications of Indirect Speech in Physical Human-Robot Collaboration
Feb 17, 2025Indirect speech acts (ISAs) are a natural pragmatic feature of human communication, allowing requests to be conveyed implicitly while maintaining subtlety and flexibility. Although advancements in speech recognition have enabled natural language interactions with robots through direct, explicit commands--providing clarity in communication--the rise of large language models presents the potential for robots to interpret ISAs. However, empirical evidence on the effects of ISAs on human-robot collaboration (HRC) remains limited. To address this, we conducted a Wizard-of-Oz study (N=36), engaging a participant and a robot in collaborative physical tasks. Our findings indicate that robots capable of understanding ISAs significantly improve human's perceived robot anthropomorphism, team performance, and trust. However, the effectiveness of ISAs is task- and context-dependent, thus requiring careful use. These results highlight the importance of appropriately integrating direct and indirect requests in HRC to enhance collaborative experiences and task performance.
'Labelling the Gaps': A Weakly Supervised Automatic Eye Gaze Estimation
Aug 12, 2022
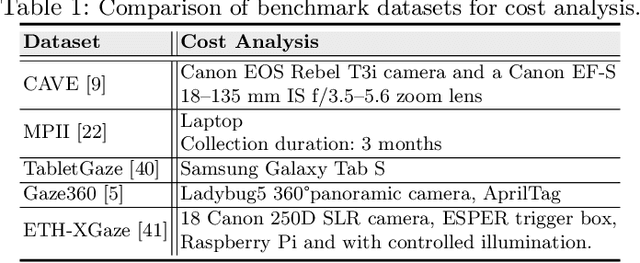

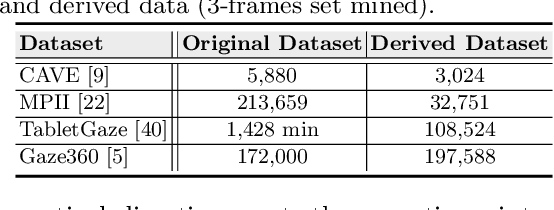
Over the past few years, there has been an increasing interest to interpret gaze direction in an unconstrained environment with limited supervision. Owing to data curation and annotation issues, replicating gaze estimation method to other platforms, such as unconstrained outdoor or AR/VR, might lead to significant drop in performance due to insufficient availability of accurately annotated data for model training. In this paper, we explore an interesting yet challenging problem of gaze estimation method with a limited amount of labelled data. The proposed method distills knowledge from the labelled subset with visual features; including identity-specific appearance, gaze trajectory consistency and motion features. Given a gaze trajectory, the method utilizes label information of only the start and the end frames of a gaze sequence. An extension of the proposed method further reduces the requirement of labelled frames to only the start frame with a minor drop in the generated label's quality. We evaluate the proposed method on four benchmark datasets (CAVE, TabletGaze, MPII and Gaze360) as well as web-crawled YouTube videos. Our proposed method reduces the annotation effort to as low as 2.67%, with minimal impact on performance; indicating the potential of our model enabling gaze estimation 'in-the-wild' setup.
AV-Gaze: A Study on the Effectiveness of Audio Guided Visual Attention Estimation for Non-Profilic Faces
Jul 07, 2022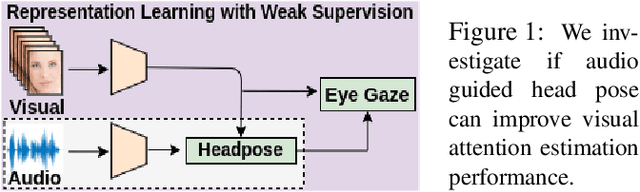
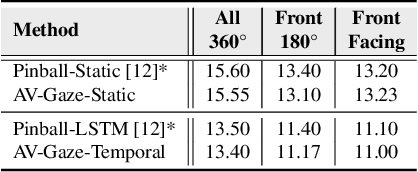
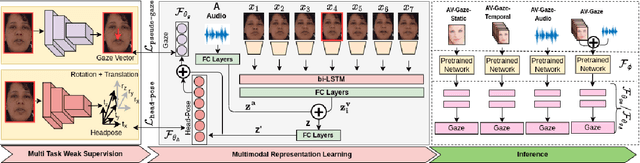
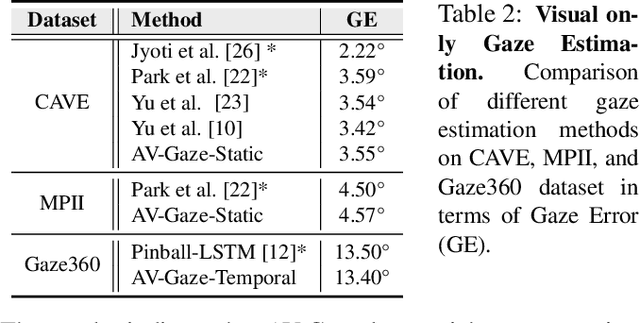
In challenging real-life conditions such as extreme head-pose, occlusions, and low-resolution images where the visual information fails to estimate visual attention/gaze direction, audio signals could provide important and complementary information. In this paper, we explore if audio-guided coarse head-pose can further enhance visual attention estimation performance for non-prolific faces. Since it is difficult to annotate audio signals for estimating the head-pose of the speaker, we use off-the-shelf state-of-the-art models to facilitate cross-modal weak-supervision. During the training phase, the framework learns complementary information from synchronized audio-visual modality. Our model can utilize any of the available modalities i.e. audio, visual or audio-visual for task-specific inference. It is interesting to note that, when AV-Gaze is tested on benchmark datasets with these specific modalities, it achieves competitive results on multiple datasets, while being highly adaptive towards challenging scenarios.
MTGLS: Multi-Task Gaze Estimation with Limited Supervision
Oct 23, 2021

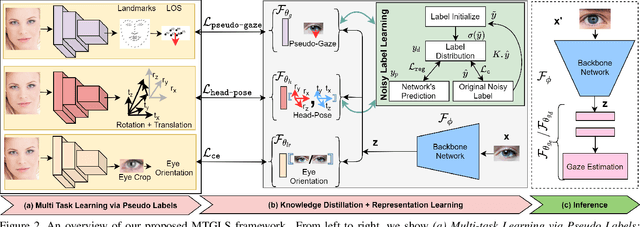

Robust gaze estimation is a challenging task, even for deep CNNs, due to the non-availability of large-scale labeled data. Moreover, gaze annotation is a time-consuming process and requires specialized hardware setups. We propose MTGLS: a Multi-Task Gaze estimation framework with Limited Supervision, which leverages abundantly available non-annotated facial image data. MTGLS distills knowledge from off-the-shelf facial image analysis models, and learns strong feature representations of human eyes, guided by three complementary auxiliary signals: (a) the line of sight of the pupil (i.e. pseudo-gaze) defined by the localized facial landmarks, (b) the head-pose given by Euler angles, and (c) the orientation of the eye patch (left/right eye). To overcome inherent noise in the supervisory signals, MTGLS further incorporates a noise distribution modelling approach. Our experimental results show that MTGLS learns highly generalized representations which consistently perform well on a range of datasets. Our proposed framework outperforms the unsupervised state-of-the-art on CAVE (by 6.43%) and even supervised state-of-the-art methods on Gaze360 (by 6.59%) datasets.
Automatic Gaze Analysis: A Survey of Deep Learning based Approaches
Aug 30, 2021
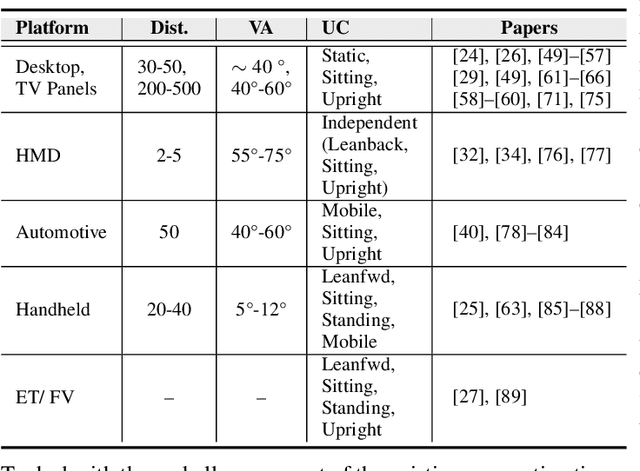
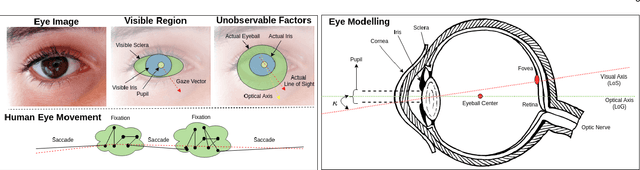

Eye gaze analysis is an important research problem in the field of Computer Vision and Human-Computer Interaction. Even with notable progress in the last 10 years, automatic gaze analysis still remains challenging due to the uniqueness of eye appearance, eye-head interplay, occlusion, image quality, and illumination conditions. There are several open questions including what are the important cues to interpret gaze direction in an unconstrained environment without prior knowledge and how to encode them in real-time. We review the progress across a range of gaze analysis tasks and applications to elucidate these fundamental questions; identify effective methods in gaze analysis and provide possible future directions. We analyze recent gaze estimation and segmentation methods, especially in the unsupervised and weakly supervised domain, based on their advantages and reported evaluation metrics. Our analysis shows that the development of a robust and generic gaze analysis method still needs to address real-world challenges such as unconstrained setup and learning with less supervision. We conclude by discussing future research directions for designing a real-world gaze analysis system that can propagate to other domains including Computer Vision, Augmented Reality (AR), Virtual Reality (VR), and Human Computer Interaction (HCI). Project Page: https://github.com/i-am-shreya/EyeGazeSurvey}{https://github.com/i-am-shreya/EyeGazeSurvey