 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025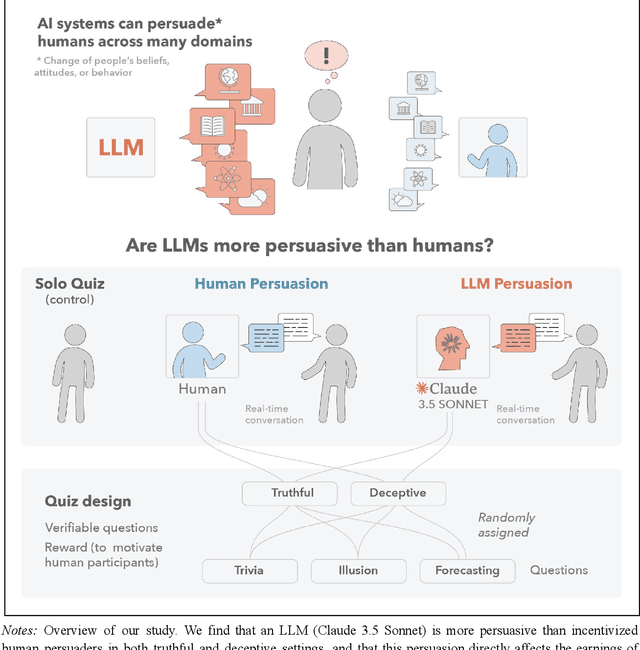
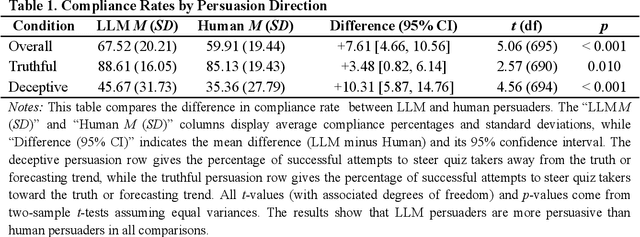
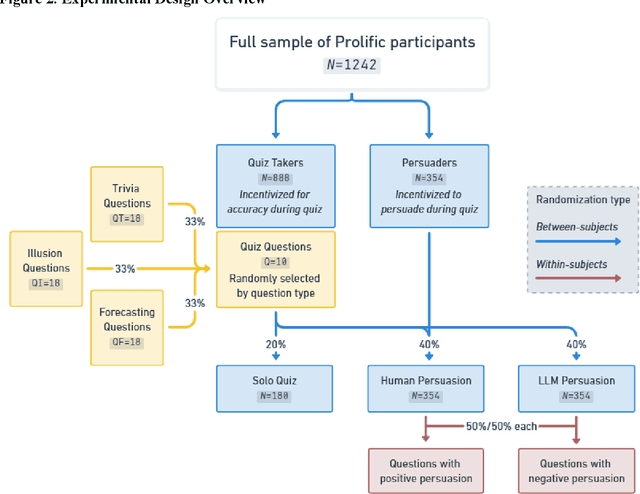
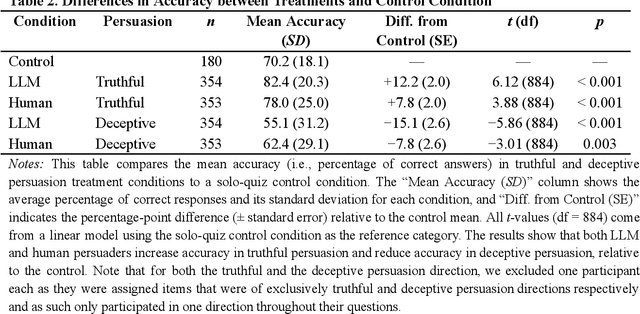
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Uhura: A Benchmark for Evaluating Scientific Question Answering and Truthfulness in Low-Resource African Languages
Dec 01, 2024



Evaluations of Large Language Models (LLMs) on knowledge-intensive tasks and factual accuracy often focus on high-resource languages primarily because datasets for low-resource languages (LRLs) are scarce. In this paper, we present Uhura -- a new benchmark that focuses on two tasks in six typologically-diverse African languages, created via human translation of existing English benchmarks. The first dataset, Uhura-ARC-Easy, is composed of multiple-choice science questions. The second, Uhura-TruthfulQA, is a safety benchmark testing the truthfulness of models on topics including health, law, finance, and politics. We highlight the challenges creating benchmarks with highly technical content for LRLs and outline mitigation strategies. Our evaluation reveals a significant performance gap between proprietary models such as GPT-4o and o1-preview, and Claude models, and open-source models like Meta's LLaMA and Google's Gemma. Additionally, all models perform better in English than in African languages. These results indicate that LMs struggle with answering scientific questions and are more prone to generating false claims in low-resource African languages. Our findings underscore the necessity for continuous improvement of multilingual LM capabilities in LRL settings to ensure safe and reliable use in real-world contexts. We open-source the Uhura Benchmark and Uhura Platform to foster further research and development in NLP for LRLs.
The Grand Illusion: The Myth of Software Portability and Implications for ML Progress
Sep 12, 2023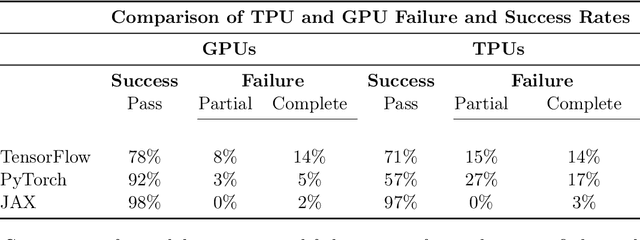
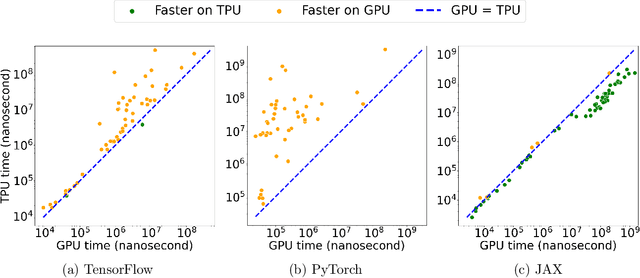
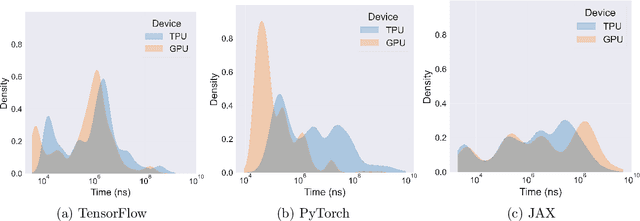
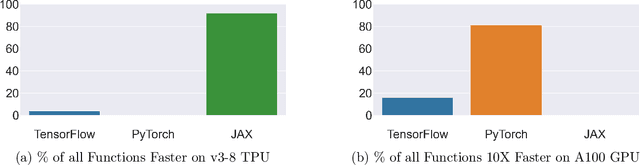
Pushing the boundaries of machine learning often requires exploring different hardware and software combinations. However, the freedom to experiment across different tooling stacks can be at odds with the drive for efficiency, which has produced increasingly specialized AI hardware and incentivized consolidation around a narrow set of ML frameworks. Exploratory research can be restricted if software and hardware are co-evolving, making it even harder to stray away from mainstream ideas that work well with popular tooling stacks. While this friction increasingly impacts the rate of innovation in machine learning, to our knowledge the lack of portability in tooling has not been quantified. In this work, we ask: How portable are popular ML software frameworks? We conduct a large-scale study of the portability of mainstream ML frameworks across different hardware types. Our findings paint an uncomfortable picture -- frameworks can lose more than 40% of their key functions when ported to other hardware. Worse, even when functions are portable, the slowdown in their performance can be extreme and render performance untenable. Collectively, our results reveal how costly straying from a narrow set of hardware-software combinations can be - and suggest that specialization of hardware impedes innovation in machine learning research.