 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Uhura: A Benchmark for Evaluating Scientific Question Answering and Truthfulness in Low-Resource African Languages
Dec 01, 2024



Evaluations of Large Language Models (LLMs) on knowledge-intensive tasks and factual accuracy often focus on high-resource languages primarily because datasets for low-resource languages (LRLs) are scarce. In this paper, we present Uhura -- a new benchmark that focuses on two tasks in six typologically-diverse African languages, created via human translation of existing English benchmarks. The first dataset, Uhura-ARC-Easy, is composed of multiple-choice science questions. The second, Uhura-TruthfulQA, is a safety benchmark testing the truthfulness of models on topics including health, law, finance, and politics. We highlight the challenges creating benchmarks with highly technical content for LRLs and outline mitigation strategies. Our evaluation reveals a significant performance gap between proprietary models such as GPT-4o and o1-preview, and Claude models, and open-source models like Meta's LLaMA and Google's Gemma. Additionally, all models perform better in English than in African languages. These results indicate that LMs struggle with answering scientific questions and are more prone to generating false claims in low-resource African languages. Our findings underscore the necessity for continuous improvement of multilingual LM capabilities in LRL settings to ensure safe and reliable use in real-world contexts. We open-source the Uhura Benchmark and Uhura Platform to foster further research and development in NLP for LRLs.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
SEAL: Systematic Error Analysis for Value ALignment
Aug 16, 2024Reinforcement Learning from Human Feedback (RLHF) aims to align language models (LMs) with human values by training reward models (RMs) on binary preferences and using these RMs to fine-tune the base LMs. Despite its importance, the internal mechanisms of RLHF remain poorly understood. This paper introduces new metrics to evaluate the effectiveness of modeling and aligning human values, namely feature imprint, alignment resistance and alignment robustness. We categorize alignment datasets into target features (desired values) and spoiler features (undesired concepts). By regressing RM scores against these features, we quantify the extent to which RMs reward them - a metric we term feature imprint. We define alignment resistance as the proportion of the preference dataset where RMs fail to match human preferences, and we assess alignment robustness by analyzing RM responses to perturbed inputs. Our experiments, utilizing open-source components like the Anthropic/hh-rlhf preference dataset and OpenAssistant RMs, reveal significant imprints of target features and a notable sensitivity to spoiler features. We observed a 26% incidence of alignment resistance in portions of the dataset where LM-labelers disagreed with human preferences. Furthermore, we find that misalignment often arises from ambiguous entries within the alignment dataset. These findings underscore the importance of scrutinizing both RMs and alignment datasets for a deeper understanding of value alignment.
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
Mar 23, 2023

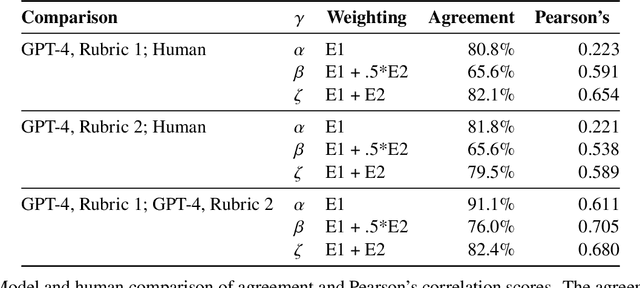

We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.
A Holistic Approach to Undesired Content Detection in the Real World
Aug 05, 2022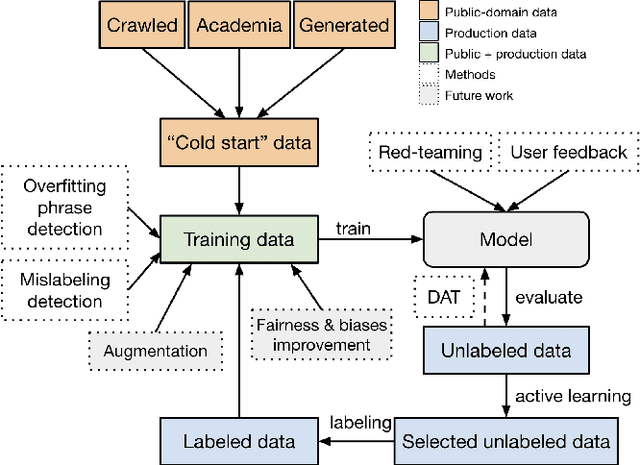


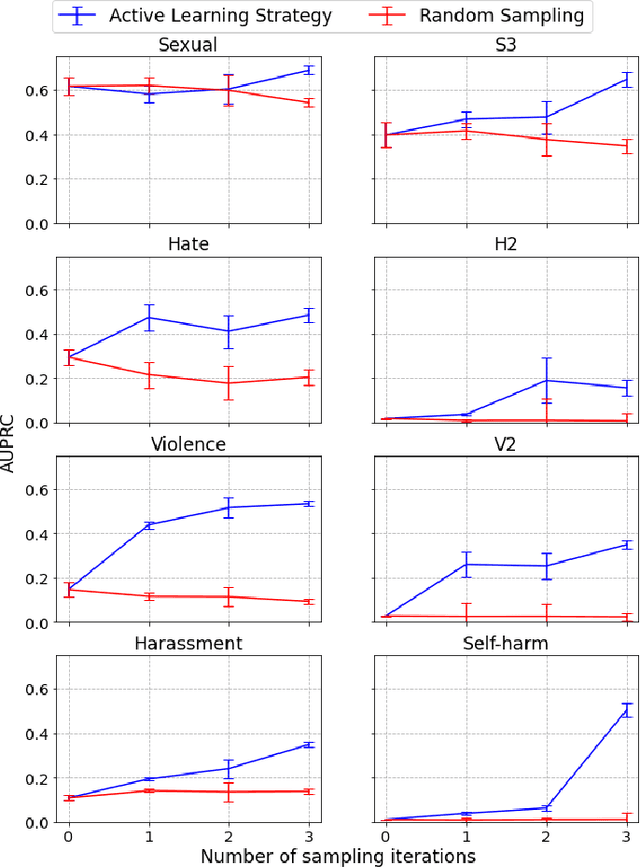
We present a holistic approach to building a robust and useful natural language classification system for real-world content moderation. The success of such a system relies on a chain of carefully designed and executed steps, including the design of content taxonomies and labeling instructions, data quality control, an active learning pipeline to capture rare events, and a variety of methods to make the model robust and to avoid overfitting. Our moderation system is trained to detect a broad set of categories of undesired content, including sexual content, hateful content, violence, self-harm, and harassment. This approach generalizes to a wide range of different content taxonomies and can be used to create high-quality content classifiers that outperform off-the-shelf models.
WebGPT: Browser-assisted question-answering with human feedback
Dec 17, 2021


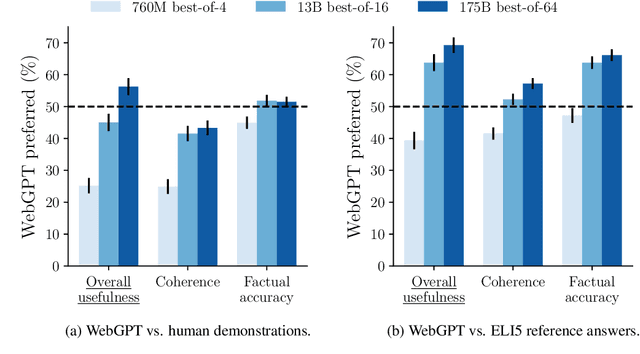
We fine-tune GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web. By setting up the task so that it can be performed by humans, we are able to train models on the task using imitation learning, and then optimize answer quality with human feedback. To make human evaluation of factual accuracy easier, models must collect references while browsing in support of their answers. We train and evaluate our models on ELI5, a dataset of questions asked by Reddit users. Our best model is obtained by fine-tuning GPT-3 using behavior cloning, and then performing rejection sampling against a reward model trained to predict human preferences. This model's answers are preferred by humans 56% of the time to those of our human demonstrators, and 69% of the time to the highest-voted answer from Reddit.