 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrends in Frontier AI Model Count: A Forecast to 2028
Apr 21, 2025Governments are starting to impose requirements on AI models based on how much compute was used to train them. For example, the EU AI Act imposes requirements on providers of general-purpose AI with systemic risk, which includes systems trained using greater than $10^{25}$ floating point operations (FLOP). In the United States' AI Diffusion Framework, a training compute threshold of $10^{26}$ FLOP is used to identify "controlled models" which face a number of requirements. We explore how many models such training compute thresholds will capture over time. We estimate that by the end of 2028, there will be between 103-306 foundation models exceeding the $10^{25}$ FLOP threshold put forward in the EU AI Act (90% CI), and 45-148 models exceeding the $10^{26}$ FLOP threshold that defines controlled models in the AI Diffusion Framework (90% CI). We also find that the number of models exceeding these absolute compute thresholds each year will increase superlinearly -- that is, each successive year will see more new models captured within the threshold than the year before. Thresholds that are defined with respect to the largest training run to date (for example, such that all models within one order of magnitude of the largest training run to date are captured by the threshold) see a more stable trend, with a median forecast of 14-16 models being captured by this definition annually from 2025-2028.
Measuring AI agent autonomy: Towards a scalable approach with code inspection
Feb 21, 2025AI agents are AI systems that can achieve complex goals autonomously. Assessing the level of agent autonomy is crucial for understanding both their potential benefits and risks. Current assessments of autonomy often focus on specific risks and rely on run-time evaluations -- observations of agent actions during operation. We introduce a code-based assessment of autonomy that eliminates the need to run an AI agent to perform specific tasks, thereby reducing the costs and risks associated with run-time evaluations. Using this code-based framework, the orchestration code used to run an AI agent can be scored according to a taxonomy that assesses attributes of autonomy: impact and oversight. We demonstrate this approach with the AutoGen framework and select applications.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
Mar 23, 2023

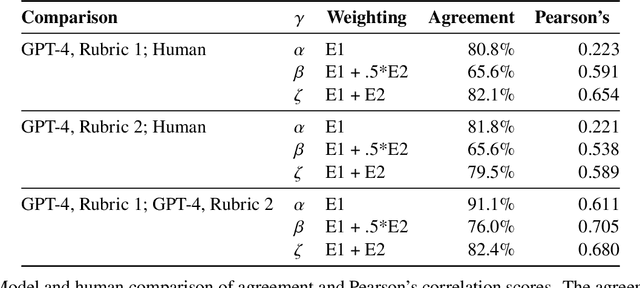

We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.