 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis of document graph construction methods for AMR summarization
Paper and Code
Nov 27, 2021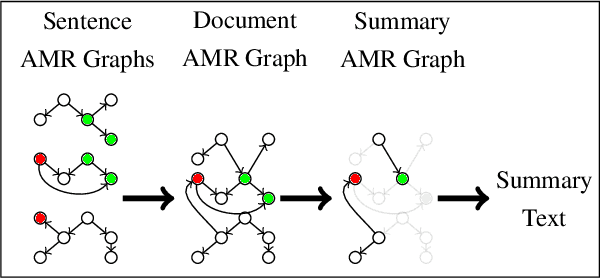
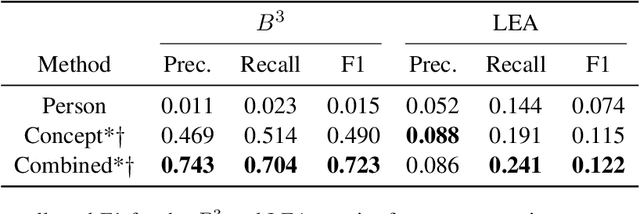
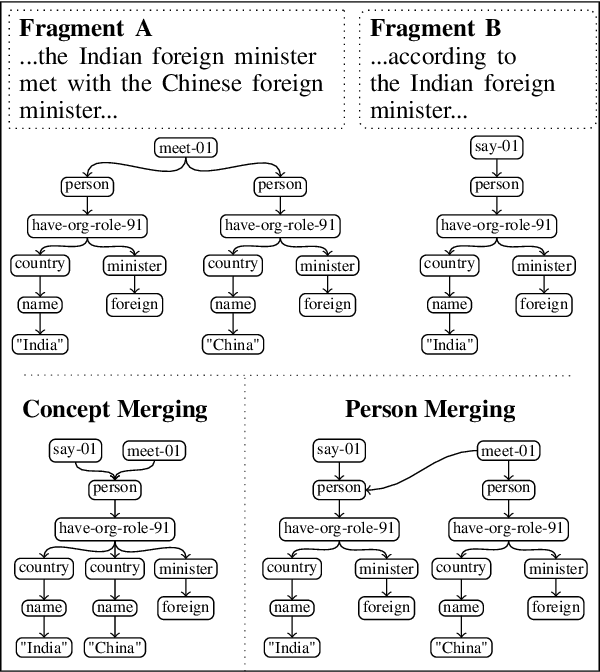
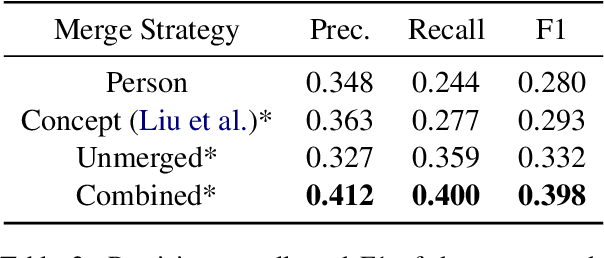
Meaning Representation (AMR) is a graph-based semantic representation for sentences, composed of collections of concepts linked by semantic relations. AMR-based approaches have found success in a variety of applications, but a challenge to using it in tasks that require document-level context is that it only represents individual sentences. Prior work in AMR-based summarization has automatically merged the individual sentence graphs into a document graph, but the method of merging and its effects on summary content selection have not been independently evaluated. In this paper, we present a novel dataset consisting of human-annotated alignments between the nodes of paired documents and summaries which may be used to evaluate (1) merge strategies; and (2) the performance of content selection methods over nodes of a merged or unmerged AMR graph. We apply these two forms of evaluation to prior work as well as a new method for node merging and show that our new method has significantly better performance than prior work.