 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-language Sentence Selection via Data Augmentation and Rationale Training
Paper and Code
Jun 04, 2021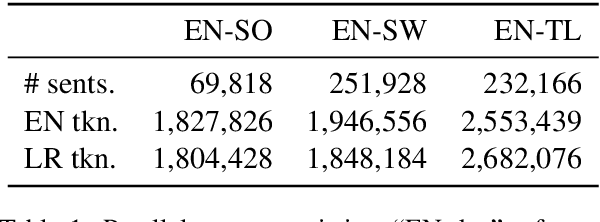
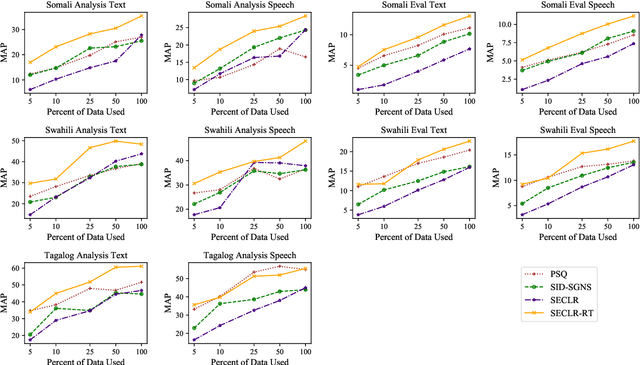
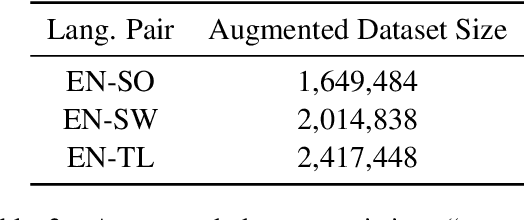
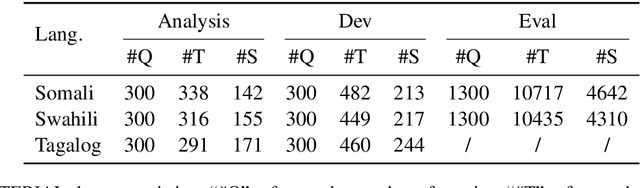
This paper proposes an approach to cross-language sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-the-art machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (English-Somali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.