 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorize Early, Integrate Late: Divergent Processing Strategies in Automatic Speech Recognition
Jan 11, 2026In speech language modeling, two architectures dominate the frontier: the Transformer and the Conformer. However, it remains unknown whether their comparable performance stems from convergent processing strategies or distinct architectural inductive biases. We introduce Architectural Fingerprinting, a probing framework that isolates the effect of architecture on representation, and apply it to a controlled suite of 24 pre-trained encoders (39M-3.3B parameters). Our analysis reveals divergent hierarchies: Conformers implement a "Categorize Early" strategy, resolving phoneme categories 29% earlier in depth and speaker gender by 16% depth. In contrast, Transformers "Integrate Late," deferring phoneme, accent, and duration encoding to deep layers (49-57%). These fingerprints suggest design heuristics: Conformers' front-loaded categorization may benefit low-latency streaming, while Transformers' deep integration may favor tasks requiring rich context and cross-utterance normalization.
In-Context Learning Boosts Speech Recognition via Human-like Adaptation to Speakers and Language Varieties
May 20, 2025

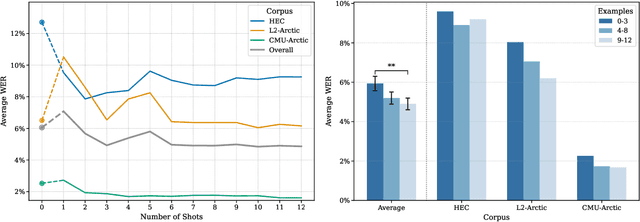
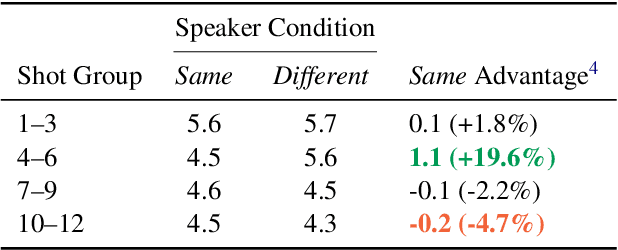
Human listeners readily adjust to unfamiliar speakers and language varieties through exposure, but do these adaptation benefits extend to state-of-the-art spoken language models? We introduce a scalable framework that allows for in-context learning (ICL) in Phi-4 Multimodal using interleaved task prompts and audio-text pairs, and find that as few as 12 example utterances (~50 seconds) at inference time reduce word error rates by a relative 19.7% (1.2 pp.) on average across diverse English corpora. These improvements are most pronounced in low-resource varieties, when the context and target speaker match, and when more examples are provided--though scaling our procedure yields diminishing marginal returns to context length. Overall, we find that our novel ICL adaptation scheme (1) reveals a similar performance profile to human listeners, and (2) demonstrates consistent improvements to automatic speech recognition (ASR) robustness across diverse speakers and language backgrounds. While adaptation succeeds broadly, significant gaps remain for certain varieties, revealing where current models still fall short of human flexibility. We release our prompts and code on GitHub.
Stepback: Enhanced Disentanglement for Voice Conversion via Multi-Task Learning
Jan 26, 2025Voice conversion (VC) modifies voice characteristics while preserving linguistic content. This paper presents the Stepback network, a novel model for converting speaker identity using non-parallel data. Unlike traditional VC methods that rely on parallel data, our approach leverages deep learning techniques to enhance disentanglement completion and linguistic content preservation. The Stepback network incorporates a dual flow of different domain data inputs and uses constraints with self-destructive amendments to optimize the content encoder. Extensive experiments show that our model significantly improves VC performance, reducing training costs while achieving high-quality voice conversion. The Stepback network's design offers a promising solution for advanced voice conversion tasks.
PSST! Prosodic Speech Segmentation with Transformers
Feb 03, 2023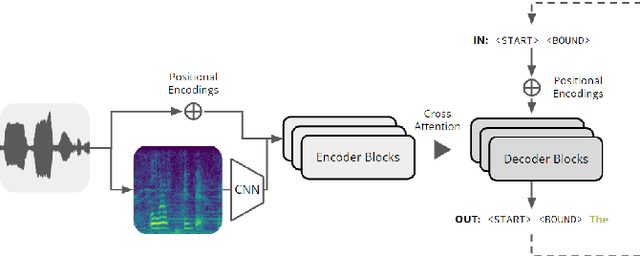
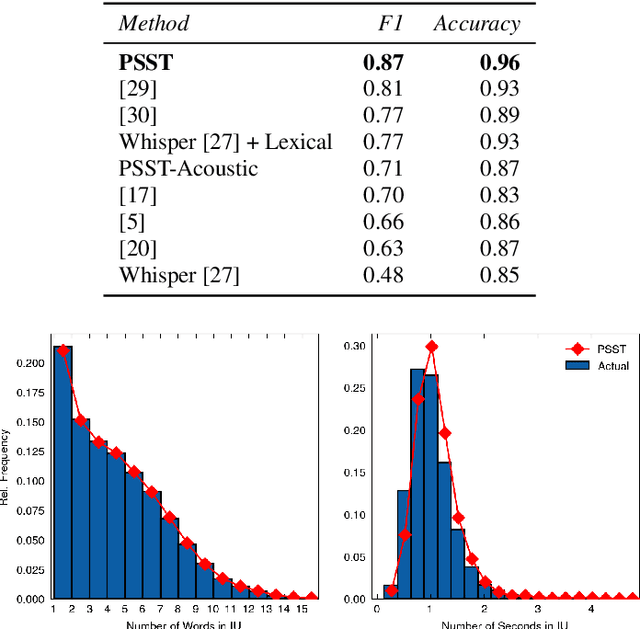
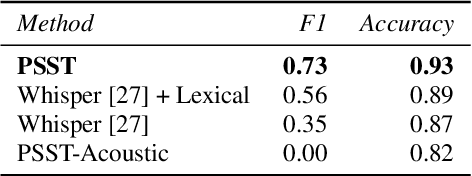
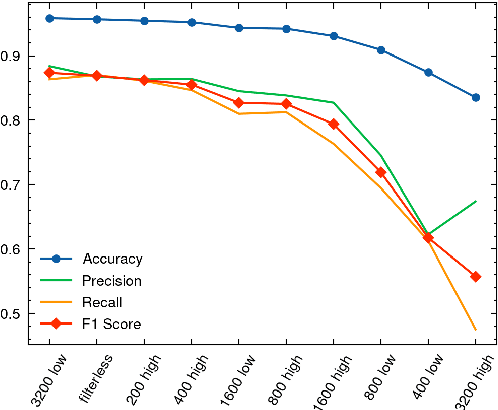
Self-attention mechanisms have enabled transformers to achieve superhuman-level performance on many speech-to-text (STT) tasks, yet the challenge of automatic prosodic segmentation has remained unsolved. In this paper we finetune Whisper, a pretrained STT model, to annotate intonation unit (IU) boundaries by repurposing low-frequency tokens. Our approach achieves an accuracy of 95.8%, outperforming previous methods without the need for large-scale labeled data or enterprise grade compute resources. We also diminish input signals by applying a series of filters, finding that low pass filters at a 3.2 kHz level improve segmentation performance in out of sample and out of distribution contexts. We release our model as both a transcription tool and a baseline for further improvements in prosodic segmentation.