 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Just Statistical Recurrence: Human and Machine Unsupervised Learning of Māori Word Segmentation across Morphological Processes
Mar 21, 2024Non-M\=aori-speaking New Zealanders (NMS)are able to segment M\=aori words in a highlysimilar way to fluent speakers (Panther et al.,2024). This ability is assumed to derive through the identification and extraction of statistically recurrent forms. We examine this assumption by asking how NMS segmentations compare to those produced by Morfessor, an unsupervised machine learning model that operates based on statistical recurrence, across words formed by a variety of morphological processes. Both NMS and Morfessor succeed in segmenting words formed by concatenative processes (compounding and affixation without allomorphy), but NMS also succeed for words that invoke templates (reduplication and allomorphy) and other cues to morphological structure, implying that their learning process is sensitive to more than just statistical recurrence.
PSST! Prosodic Speech Segmentation with Transformers
Feb 03, 2023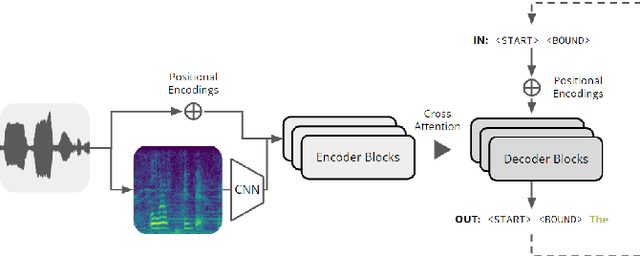
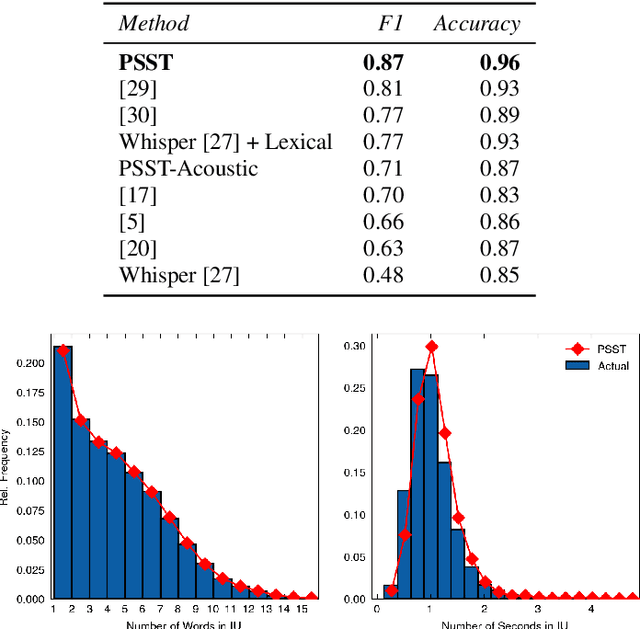
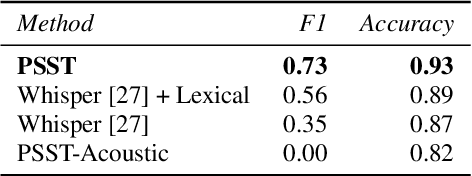
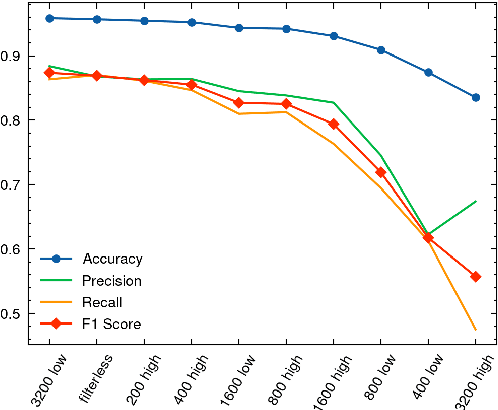
Self-attention mechanisms have enabled transformers to achieve superhuman-level performance on many speech-to-text (STT) tasks, yet the challenge of automatic prosodic segmentation has remained unsolved. In this paper we finetune Whisper, a pretrained STT model, to annotate intonation unit (IU) boundaries by repurposing low-frequency tokens. Our approach achieves an accuracy of 95.8%, outperforming previous methods without the need for large-scale labeled data or enterprise grade compute resources. We also diminish input signals by applying a series of filters, finding that low pass filters at a 3.2 kHz level improve segmentation performance in out of sample and out of distribution contexts. We release our model as both a transcription tool and a baseline for further improvements in prosodic segmentation.