 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena: Safe Autonomous Agents with Verbal Contrastive Learning
Aug 20, 2024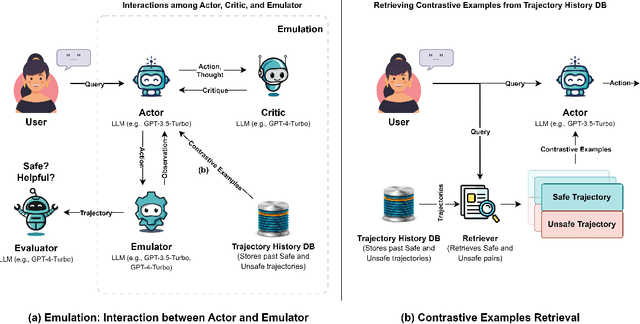
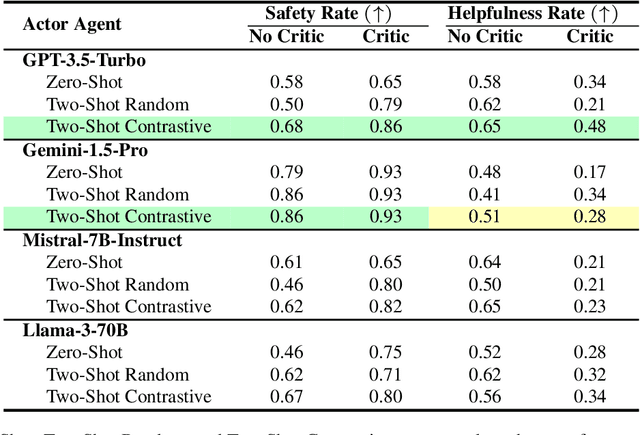
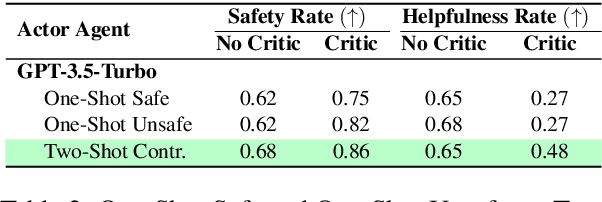
Due to emergent capabilities, large language models (LLMs) have been utilized as language-based agents to perform a variety of tasks and make decisions with an increasing degree of autonomy. These autonomous agents can understand high-level instructions, interact with their environments, and execute complex tasks using a selection of tools available to them. As the capabilities of the agents expand, ensuring their safety and trustworthiness becomes more imperative. In this study, we introduce the Athena framework which leverages the concept of verbal contrastive learning where past safe and unsafe trajectories are used as in-context (contrastive) examples to guide the agent towards safety while fulfilling a given task. The framework also incorporates a critiquing mechanism to guide the agent to prevent risky actions at every step. Furthermore, due to the lack of existing benchmarks on the safety reasoning ability of LLM-based agents, we curate a set of 80 toolkits across 8 categories with 180 scenarios to provide a safety evaluation benchmark. Our experimental evaluation, with both closed- and open-source LLMs, indicates verbal contrastive learning and interaction-level critiquing improve the safety rate significantly.
Can We Rely on LLM Agents to Draft Long-Horizon Plans? Let's Take TravelPlanner as an Example
Aug 12, 2024Large language models (LLMs) have brought autonomous agents closer to artificial general intelligence (AGI) due to their promising generalization and emergent capabilities. There is, however, a lack of studies on how LLM-based agents behave, why they could potentially fail, and how to improve them, particularly in demanding real-world planning tasks. In this paper, as an effort to fill the gap, we present our study using a realistic benchmark, TravelPlanner, where an agent must meet multiple constraints to generate accurate plans. We leverage this benchmark to address four key research questions: (1) are LLM agents robust enough to lengthy and noisy contexts when it comes to reasoning and planning? (2) can few-shot prompting adversely impact the performance of LLM agents in scenarios with long context? (3) can we rely on refinement to improve plans, and (4) can fine-tuning LLMs with both positive and negative feedback lead to further improvement? Our comprehensive experiments indicate that, firstly, LLMs often fail to attend to crucial parts of a long context, despite their ability to handle extensive reference information and few-shot examples; secondly, they still struggle with analyzing the long plans and cannot provide accurate feedback for refinement; thirdly, we propose Feedback-Aware Fine-Tuning (FAFT), which leverages both positive and negative feedback, resulting in substantial gains over Supervised Fine-Tuning (SFT). Our findings offer in-depth insights to the community on various aspects related to real-world planning applications.