 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Multi-Label Classification of MBTI Types
May 07, 2024In this study, we aim to identify the most effective machine learning model for accurately classifying Myers-Briggs Type Indicator (MBTI) types from Reddit posts and a Kaggle data set. We apply multi-label classification using the Binary Relevance method. We use Explainable Artificial Intelligence (XAI) approach to highlight the transparency and understandability of the process and result. To achieve this, we experiment with glass-box learning models, i.e. models designed for simplicity, transparency, and interpretability. We selected k-Nearest Neighbour, Multinomial Naive Bayes, and Logistic Regression for the glass-box models. We show that Multinomial Naive Bayes and k-Nearest Neighbour perform better if classes with Observer (S) traits are excluded, whereas Logistic Regression obtains its best results when all classes have > 550 entries.
Longitudinal Sentiment Topic Modelling of Reddit Posts
Jan 24, 2024In this study, we analyze texts of Reddit posts written by students of four major Canadian universities. We gauge the emotional tone and uncover prevailing themes and discussions through longitudinal topic modeling of posts textual data. Our study focuses on four years, 2020-2023, covering COVID-19 pandemic and after pandemic years. Our results highlight a gradual uptick in discussions related to mental health.
Longitudinal Sentiment Classification of Reddit Posts
Jan 22, 2024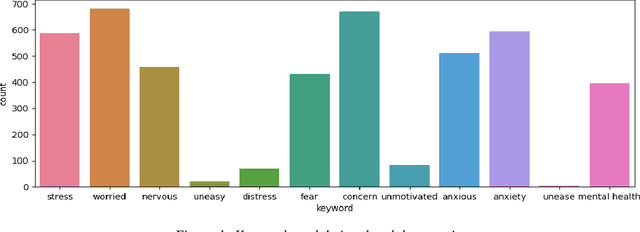

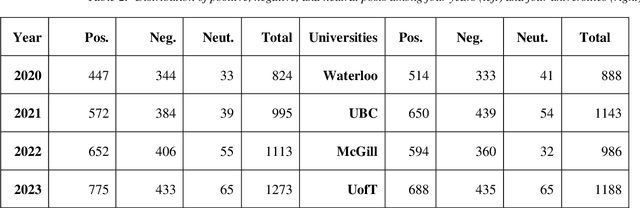
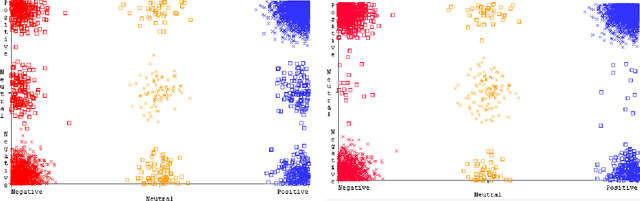
We report results of a longitudinal sentiment classification of Reddit posts written by students of four major Canadian universities. We work with the texts of the posts, concentrating on the years 2020-2023. By finely tuning a sentiment threshold to a range of [-0.075,0.075], we successfully built classifiers proficient in categorizing post sentiments into positive and negative categories. Noticeably, our sentiment classification results are consistent across the four university data sets.
Sentiment Analysis of Covid-related Reddits
May 13, 2022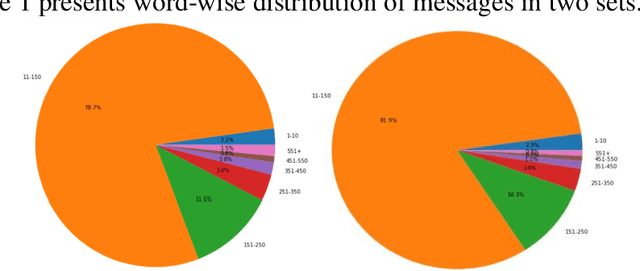
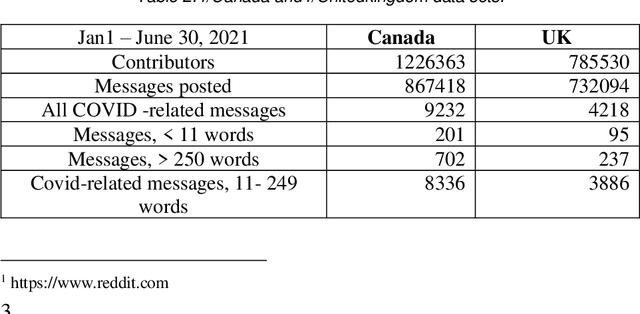
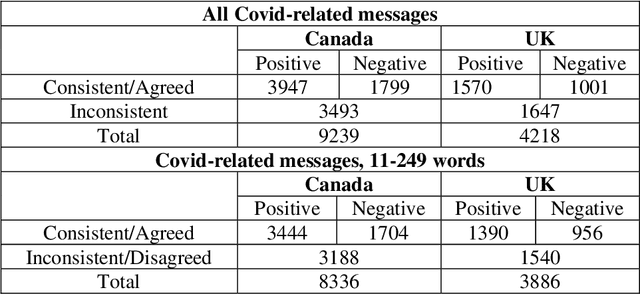
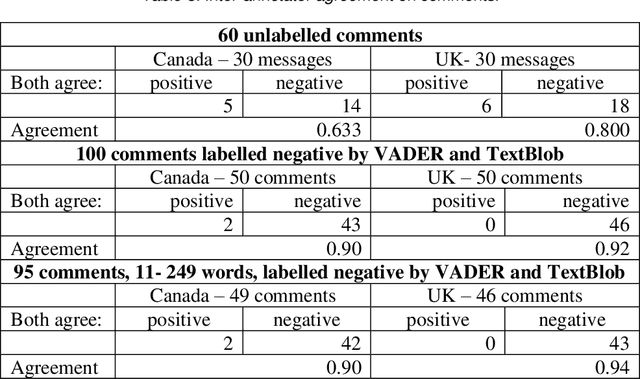
This paper focuses on Sentiment Analysis of Covid-19 related messages from the r/Canada and r/Unitedkingdom subreddits of Reddit. We apply manual annotation and three Machine Learning algorithms to analyze sentiments conveyed in those messages. We use VADER and TextBlob to label messages for Machine Learning experiments. Our results show that removal of shortest and longest messages improves VADER and TextBlob agreement on positive sentiments and F-score of sentiment classification by all the three algorithms
Sentiment Analysis of the COVID-related r/Depression Posts
Jul 28, 2021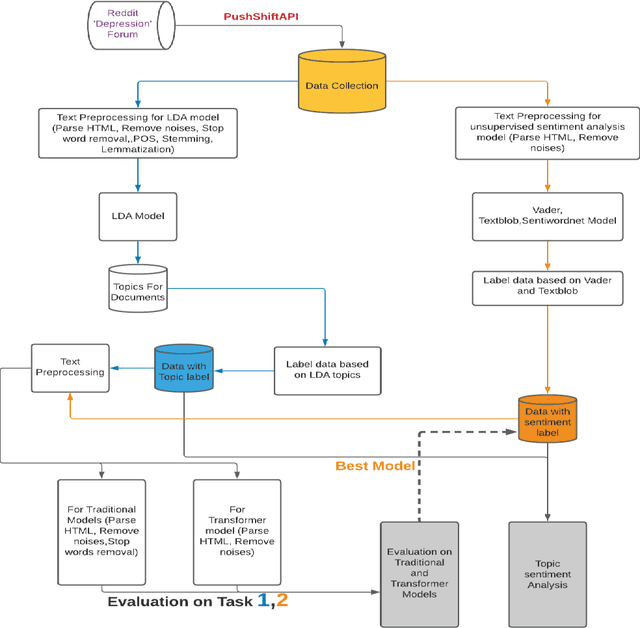
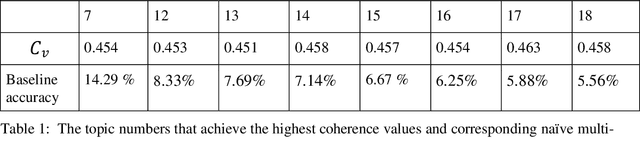
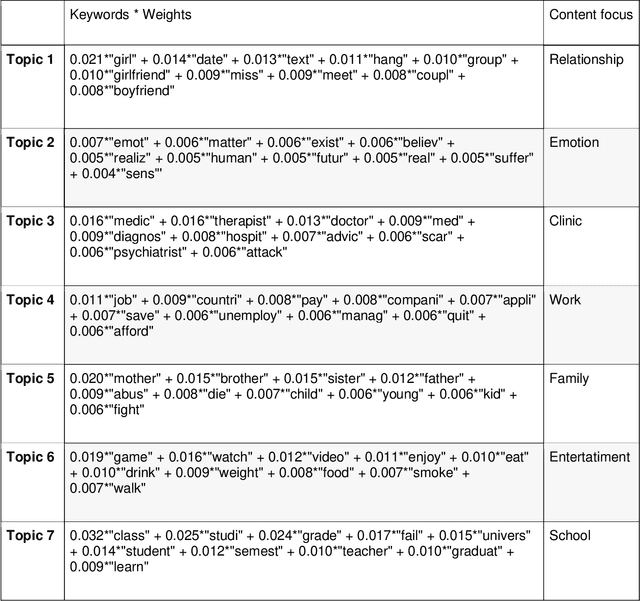
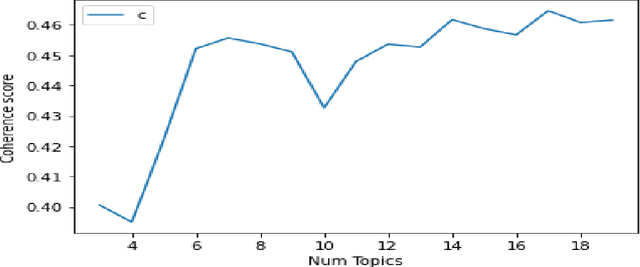
Reddit.com is a popular social media platform among young people. Reddit users share their stories to seek support from other users, especially during the Covid-19 pandemic. Messages posted on Reddit and their content have provided researchers with opportunity to analyze public concerns. In this study, we analyzed sentiments of COVID-related messages posted on r/Depression. Our study poses the following questions: a) What are the common topics that the Reddit users discuss? b) Can we use these topics to classify sentiments of the posts? c) What matters concern people more during the pandemic? Key Words: Sentiment Classification, Depression, COVID-19, Reddit, LDA, BERT
Explainable Multi-class Classification of the CAMH COVID-19 Mental Health Data
May 27, 2021

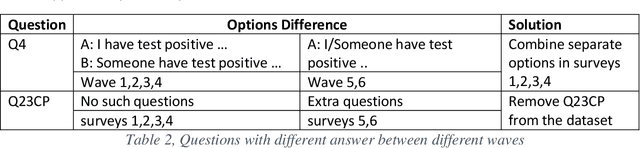
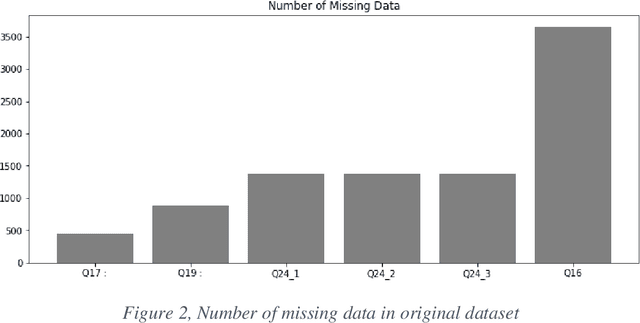
Application of Machine Learning algorithms to the medical domain is an emerging trend that helps to advance medical knowledge. At the same time, there is a significant a lack of explainable studies that promote informed, transparent, and interpretable use of Machine Learning algorithms. In this paper, we present explainable multi-class classification of the Covid-19 mental health data. In Machine Learning study, we aim to find the potential factors to influence a personal mental health during the Covid-19 pandemic. We found that Random Forest (RF) and Gradient Boosting (GB) have scored the highest accuracy of 68.08% and 68.19% respectively, with LIME prediction accuracy 65.5% for RF and 61.8% for GB. We then compare a Post-hoc system (Local Interpretable Model-Agnostic Explanations, or LIME) and an Ante-hoc system (Gini Importance) in their ability to explain the obtained Machine Learning results. To the best of these authors knowledge, our study is the first explainable Machine Learning study of the mental health data collected during Covid-19 pandemics.
Convolutional Neural Networks in Multi-Class Classification of Medical Data
Dec 28, 2020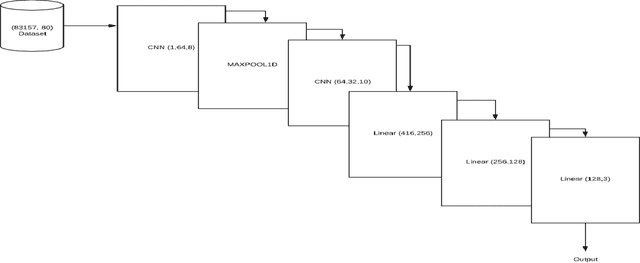
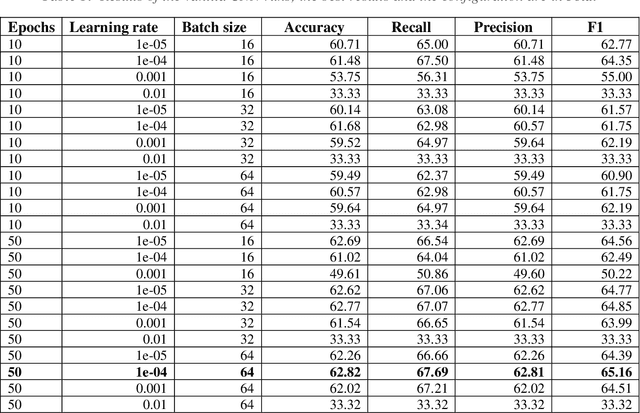
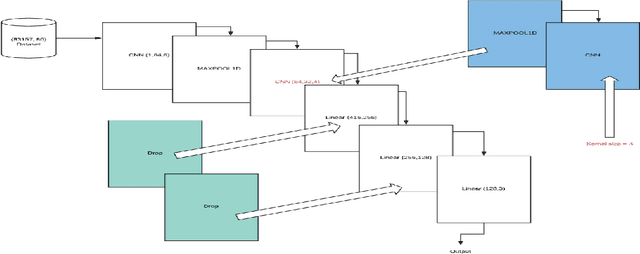
We report applications of Convolutional Neural Networks (CNN) to multi-classification classification of a large medical data set. We discuss in detail how changes in the CNN model and the data pre-processing impact the classification results. In the end, we introduce an ensemble model that consists of both deep learning (CNN) and shallow learning models (Gradient Boosting). The method achieves Accuracy of 64.93, the highest three-class classification accuracy we achieved in this study. Our results also show that CNN and the ensemble consistently obtain a higher Recall than Precision. The highest Recall is 68.87, whereas the highest Precision is 65.04.
Explainable Multi-class Classification of Medical Data
Dec 26, 2020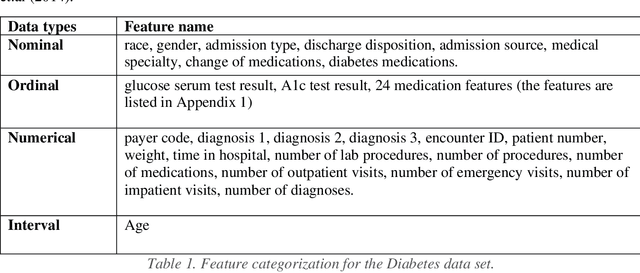
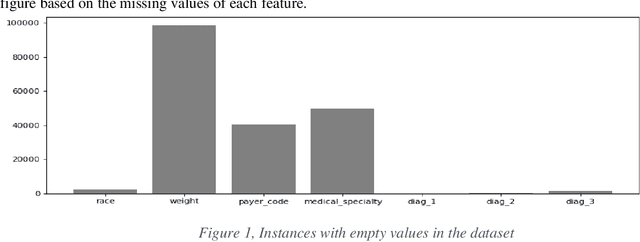

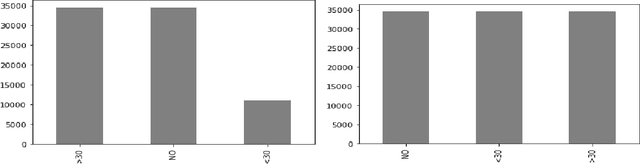
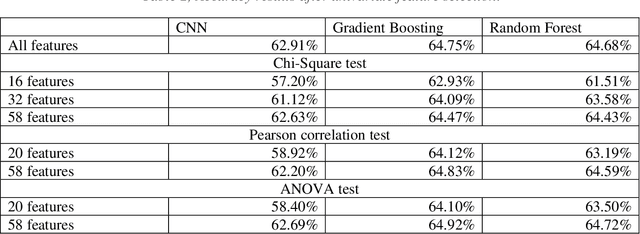
Machine Learning applications have brought new insights into a secondary analysis of medical data. Machine Learning helps to develop new drugs, define populations susceptible to certain illnesses, identify predictors of many common diseases. At the same time, Machine Learning results depend on convolution of many factors, including feature selection, class (im)balance, algorithm preference, and performance metrics. In this paper, we present explainable multi-class classification of a large medical data set. We in details discuss knowledge-based feature engineering, data set balancing, best model selection, and parameter tuning. Six algorithms are used in this study: Support Vector Machine (SVM), Na\"ive Bayes, Gradient Boosting, Decision Trees, Random Forest, and Logistic Regression. Our empirical evaluation is done on the UCI Diabetes 130-US hospitals for years 1999-2008 dataset, with the task to classify patient hospital re-admission stay into three classes: 0 days, <30 days, or > 30 days. Our results show that using 23 medication features in learning experiments improves Recall of five out of the six applied learning algorithms. This is a new result that expands the previous studies conducted on the same data. Gradient Boosting and Random Forest outperformed other algorithms in terms of the three-class classification Accuracy.
Machine Learning Evaluation of the Echo-Chamber Effect in Medical Forums
Oct 19, 2020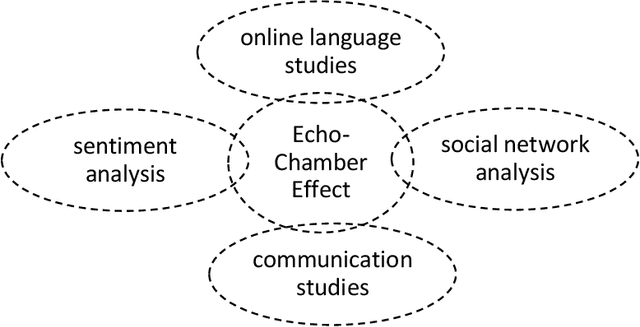
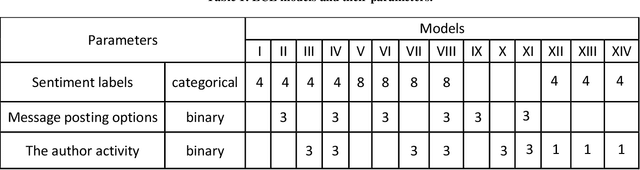
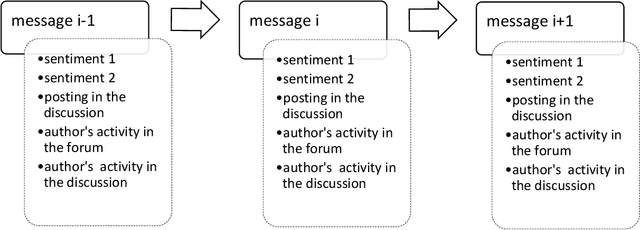

We propose the Echo-Chamber Effect assessment of an online forum. Sentiments perceived by the forum readers are at the core of the analysis; a complete message is the unit of the study. We build 14 models and apply those to represent discussions gathered from an online medical forum. We use four multi-class sentiment classification applications and two Machine Learning algorithms to evaluate prowess of the assessment models.
Word2Vec and Doc2Vec in Unsupervised Sentiment Analysis of Clinical Discharge Summaries
May 01, 2018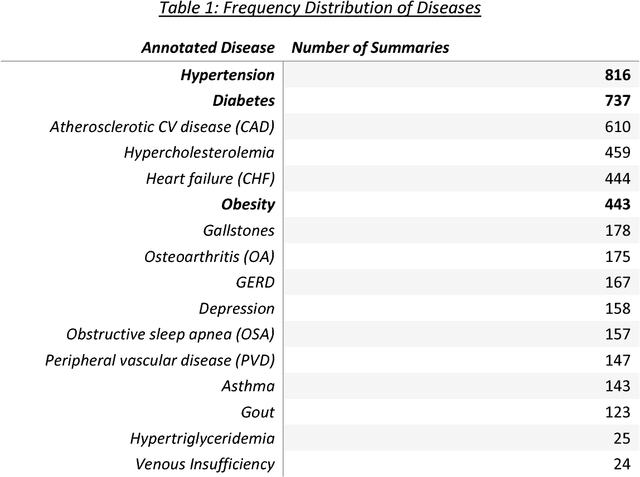
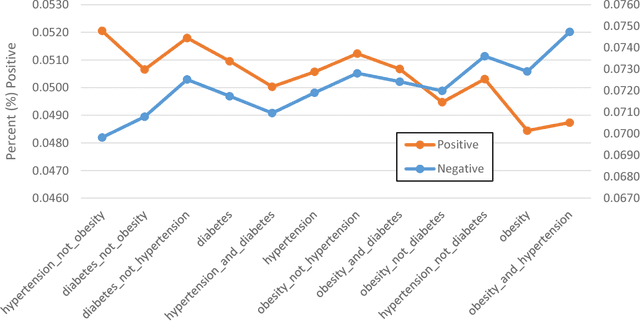
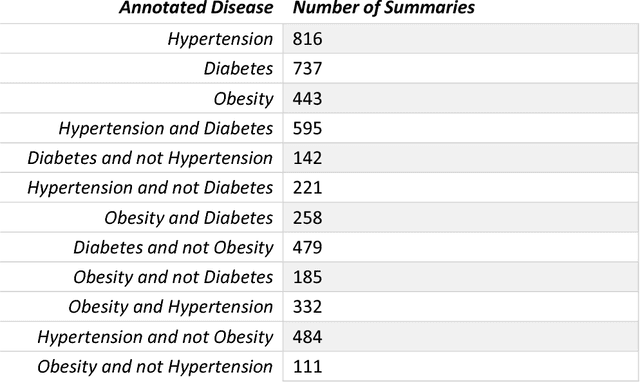
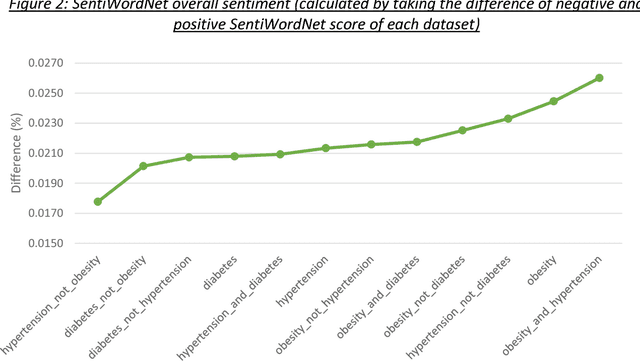
In this study, we explored application of Word2Vec and Doc2Vec for sentiment analysis of clinical discharge summaries. We applied unsupervised learning since the data sets did not have sentiment annotations. Note that unsupervised learning is a more realistic scenario than supervised learning which requires an access to a training set of sentiment-annotated data. We aim to detect if there exists any underlying bias towards or against a certain disease. We used SentiWordNet to establish a gold sentiment standard for the data sets and evaluate performance of Word2Vec and Doc2Vec methods. We have shown that the Word2vec and Doc2Vec methods complement each other results in sentiment analysis of the data sets.