 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Multi-class Classification of the CAMH COVID-19 Mental Health Data
May 27, 2021

Application of Machine Learning algorithms to the medical domain is an emerging trend that helps to advance medical knowledge. At the same time, there is a significant a lack of explainable studies that promote informed, transparent, and interpretable use of Machine Learning algorithms. In this paper, we present explainable multi-class classification of the Covid-19 mental health data. In Machine Learning study, we aim to find the potential factors to influence a personal mental health during the Covid-19 pandemic. We found that Random Forest (RF) and Gradient Boosting (GB) have scored the highest accuracy of 68.08% and 68.19% respectively, with LIME prediction accuracy 65.5% for RF and 61.8% for GB. We then compare a Post-hoc system (Local Interpretable Model-Agnostic Explanations, or LIME) and an Ante-hoc system (Gini Importance) in their ability to explain the obtained Machine Learning results. To the best of these authors knowledge, our study is the first explainable Machine Learning study of the mental health data collected during Covid-19 pandemics.
Convolutional Neural Networks in Multi-Class Classification of Medical Data
Dec 28, 2020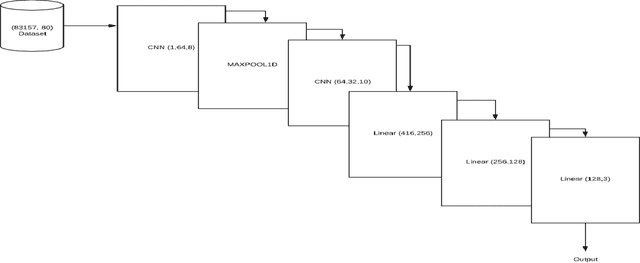
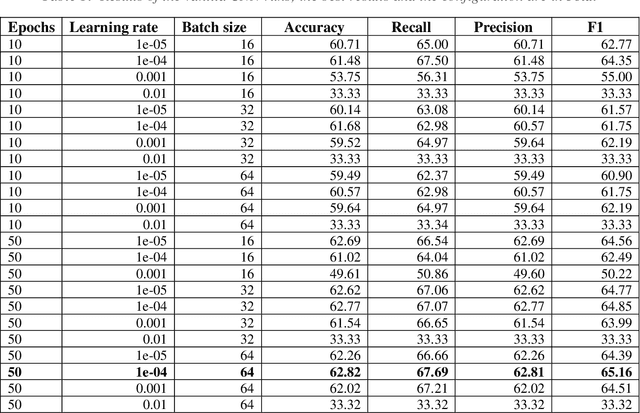
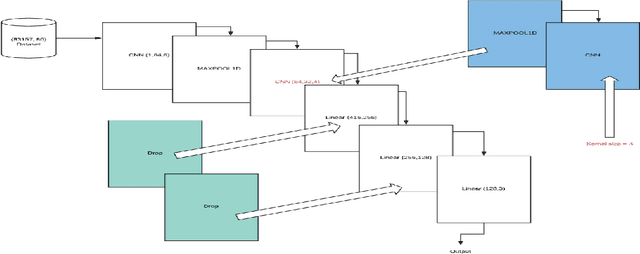
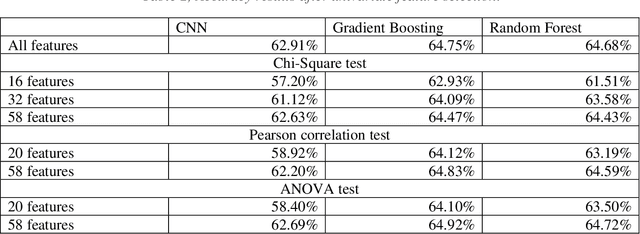
We report applications of Convolutional Neural Networks (CNN) to multi-classification classification of a large medical data set. We discuss in detail how changes in the CNN model and the data pre-processing impact the classification results. In the end, we introduce an ensemble model that consists of both deep learning (CNN) and shallow learning models (Gradient Boosting). The method achieves Accuracy of 64.93, the highest three-class classification accuracy we achieved in this study. Our results also show that CNN and the ensemble consistently obtain a higher Recall than Precision. The highest Recall is 68.87, whereas the highest Precision is 65.04.
Explainable Multi-class Classification of Medical Data
Dec 26, 2020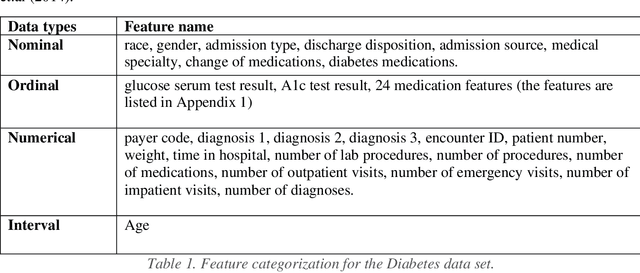
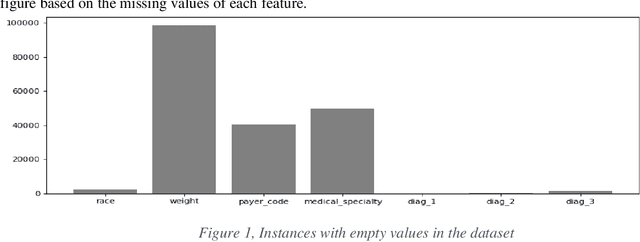

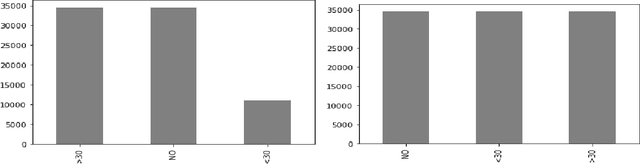
Machine Learning applications have brought new insights into a secondary analysis of medical data. Machine Learning helps to develop new drugs, define populations susceptible to certain illnesses, identify predictors of many common diseases. At the same time, Machine Learning results depend on convolution of many factors, including feature selection, class (im)balance, algorithm preference, and performance metrics. In this paper, we present explainable multi-class classification of a large medical data set. We in details discuss knowledge-based feature engineering, data set balancing, best model selection, and parameter tuning. Six algorithms are used in this study: Support Vector Machine (SVM), Na\"ive Bayes, Gradient Boosting, Decision Trees, Random Forest, and Logistic Regression. Our empirical evaluation is done on the UCI Diabetes 130-US hospitals for years 1999-2008 dataset, with the task to classify patient hospital re-admission stay into three classes: 0 days, <30 days, or > 30 days. Our results show that using 23 medication features in learning experiments improves Recall of five out of the six applied learning algorithms. This is a new result that expands the previous studies conducted on the same data. Gradient Boosting and Random Forest outperformed other algorithms in terms of the three-class classification Accuracy.