 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Multi-class Classification of Medical Data
Paper and Code
Dec 26, 2020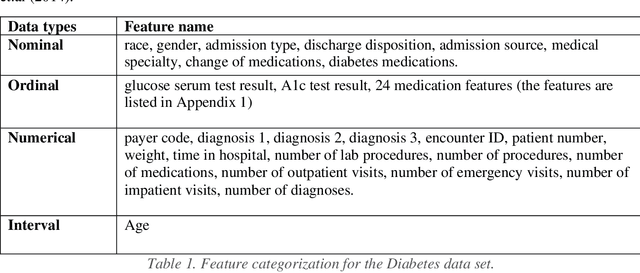
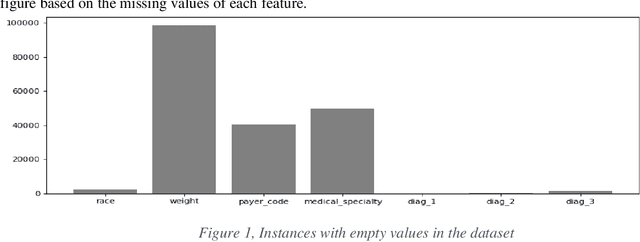

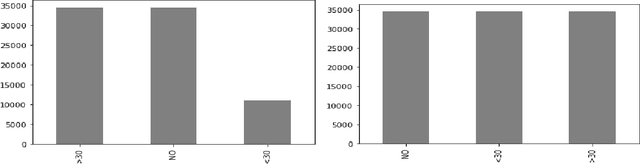
Machine Learning applications have brought new insights into a secondary analysis of medical data. Machine Learning helps to develop new drugs, define populations susceptible to certain illnesses, identify predictors of many common diseases. At the same time, Machine Learning results depend on convolution of many factors, including feature selection, class (im)balance, algorithm preference, and performance metrics. In this paper, we present explainable multi-class classification of a large medical data set. We in details discuss knowledge-based feature engineering, data set balancing, best model selection, and parameter tuning. Six algorithms are used in this study: Support Vector Machine (SVM), Na\"ive Bayes, Gradient Boosting, Decision Trees, Random Forest, and Logistic Regression. Our empirical evaluation is done on the UCI Diabetes 130-US hospitals for years 1999-2008 dataset, with the task to classify patient hospital re-admission stay into three classes: 0 days, <30 days, or > 30 days. Our results show that using 23 medication features in learning experiments improves Recall of five out of the six applied learning algorithms. This is a new result that expands the previous studies conducted on the same data. Gradient Boosting and Random Forest outperformed other algorithms in terms of the three-class classification Accuracy.