 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABCDWaveNet: Advancing Robust Road Ponding Detection in Fog through Dynamic Frequency-Spatial Synergy
Apr 07, 2025Road ponding presents a significant threat to vehicle safety, particularly in adverse fog conditions, where reliable detection remains a persistent challenge for Advanced Driver Assistance Systems (ADAS). To address this, we propose ABCDWaveNet, a novel deep learning framework leveraging Dynamic Frequency-Spatial Synergy for robust ponding detection in fog. The core of ABCDWaveNet achieves this synergy by integrating dynamic convolution for adaptive feature extraction across varying visibilities with a wavelet-based module for synergistic frequency-spatial feature enhancement, significantly improving robustness against fog interference. Building on this foundation, ABCDWaveNet captures multi-scale structural and contextual information, subsequently employing an Adaptive Attention Coupling Gate (AACG) to adaptively fuse global and local features for enhanced accuracy. To facilitate realistic evaluations under combined adverse conditions, we introduce the Foggy Low-Light Puddle dataset. Extensive experiments demonstrate that ABCDWaveNet establishes new state-of-the-art performance, achieving significant Intersection over Union (IoU) gains of 3.51%, 1.75%, and 1.03% on the Foggy-Puddle, Puddle-1000, and our Foggy Low-Light Puddle datasets, respectively. Furthermore, its processing speed of 25.48 FPS on an NVIDIA Jetson AGX Orin confirms its suitability for ADAS deployment. These findings underscore the effectiveness of the proposed Dynamic Frequency-Spatial Synergy within ABCDWaveNet, offering valuable insights for developing proactive road safety solutions capable of operating reliably in challenging weather conditions.
Minds on the Move: Decoding Trajectory Prediction in Autonomous Driving with Cognitive Insights
Feb 27, 2025In mixed autonomous driving environments, accurately predicting the future trajectories of surrounding vehicles is crucial for the safe operation of autonomous vehicles (AVs). In driving scenarios, a vehicle's trajectory is determined by the decision-making process of human drivers. However, existing models primarily focus on the inherent statistical patterns in the data, often neglecting the critical aspect of understanding the decision-making processes of human drivers. This oversight results in models that fail to capture the true intentions of human drivers, leading to suboptimal performance in long-term trajectory prediction. To address this limitation, we introduce a Cognitive-Informed Transformer (CITF) that incorporates a cognitive concept, Perceived Safety, to interpret drivers' decision-making mechanisms. Perceived Safety encapsulates the varying risk tolerances across drivers with different driving behaviors. Specifically, we develop a Perceived Safety-aware Module that includes a Quantitative Safety Assessment for measuring the subject risk levels within scenarios, and Driver Behavior Profiling for characterizing driver behaviors. Furthermore, we present a novel module, Leanformer, designed to capture social interactions among vehicles. CITF demonstrates significant performance improvements on three well-established datasets. In terms of long-term prediction, it surpasses existing benchmarks by 12.0% on the NGSIM, 28.2% on the HighD, and 20.8% on the MoCAD dataset. Additionally, its robustness in scenarios with limited or missing data is evident, surpassing most state-of-the-art (SOTA) baselines, and paving the way for real-world applications.
AGSENet: A Robust Road Ponding Detection Method for Proactive Traffic Safety
Oct 22, 2024



Road ponding, a prevalent traffic hazard, poses a serious threat to road safety by causing vehicles to lose control and leading to accidents ranging from minor fender benders to severe collisions. Existing technologies struggle to accurately identify road ponding due to complex road textures and variable ponding coloration influenced by reflection characteristics. To address this challenge, we propose a novel approach called Self-Attention-based Global Saliency-Enhanced Network (AGSENet) for proactive road ponding detection and traffic safety improvement. AGSENet incorporates saliency detection techniques through the Channel Saliency Information Focus (CSIF) and Spatial Saliency Information Enhancement (SSIE) modules. The CSIF module, integrated into the encoder, employs self-attention to highlight similar features by fusing spatial and channel information. The SSIE module, embedded in the decoder, refines edge features and reduces noise by leveraging correlations across different feature levels. To ensure accurate and reliable evaluation, we corrected significant mislabeling and missing annotations in the Puddle-1000 dataset. Additionally, we constructed the Foggy-Puddle and Night-Puddle datasets for road ponding detection in low-light and foggy conditions, respectively. Experimental results demonstrate that AGSENet outperforms existing methods, achieving IoU improvements of 2.03\%, 0.62\%, and 1.06\% on the Puddle-1000, Foggy-Puddle, and Night-Puddle datasets, respectively, setting a new state-of-the-art in this field. Finally, we verified the algorithm's reliability on edge computing devices. This work provides a valuable reference for proactive warning research in road traffic safety.
Vision-Driven 2D Supervised Fine-Tuning Framework for Bird's Eye View Perception
Sep 09, 2024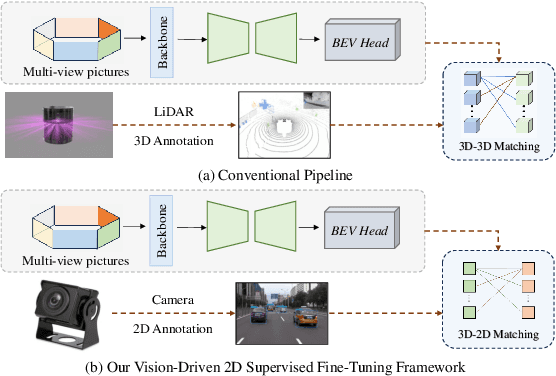
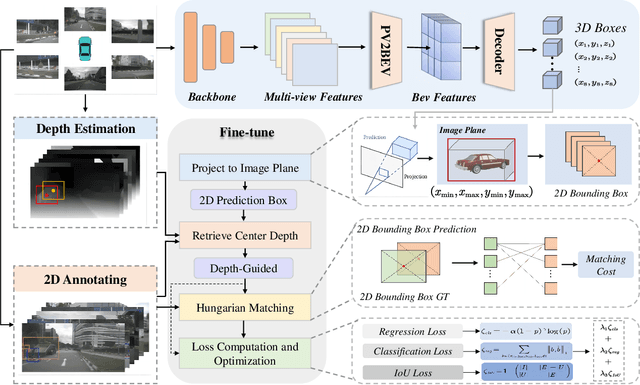


Visual bird's eye view (BEV) perception, due to its excellent perceptual capabilities, is progressively replacing costly LiDAR-based perception systems, especially in the realm of urban intelligent driving. However, this type of perception still relies on LiDAR data to construct ground truth databases, a process that is both cumbersome and time-consuming. Moreover, most massproduced autonomous driving systems are only equipped with surround camera sensors and lack LiDAR data for precise annotation. To tackle this challenge, we propose a fine-tuning method for BEV perception network based on visual 2D semantic perception, aimed at enhancing the model's generalization capabilities in new scene data. Considering the maturity and development of 2D perception technologies, our method significantly reduces the dependency on high-cost BEV ground truths and shows promising industrial application prospects. Extensive experiments and comparative analyses conducted on the nuScenes and Waymo public datasets demonstrate the effectiveness of our proposed method.
Risk Occupancy: A New and Efficient Paradigm through Vehicle-Road-Cloud Collaboration
Aug 14, 2024



This study introduces the 4D Risk Occupancy within a vehicle-road-cloud architecture, integrating the road surface spatial, risk, and temporal dimensions, and endowing the algorithm with beyond-line-of-sight, all-angles, and efficient abilities. The algorithm simplifies risk modeling by focusing on directly observable information and key factors, drawing on the concept of Occupancy Grid Maps (OGM), and incorporating temporal prediction to effectively map current and future risk occupancy. Compared to conventional driving risk fields and grid occupancy maps, this algorithm can map global risks more efficiently, simply, and reliably. It can integrate future risk information, adapting to dynamic traffic environments. The 4D Risk Occupancy also unifies the expression of BEV detection and lane line detection results, enhancing the intuitiveness and unity of environmental perception. Using DAIR-V2X data, this paper validates the 4D Risk Occupancy algorithm and develops a local path planning model based on it. Qualitative experiments under various road conditions demonstrate the practicality and robustness of this local path planning model. Quantitative analysis shows that the path planning based on risk occupation significantly improves trajectory planning performance, increasing safety redundancy by 12.5% and reducing average deceleration by 5.41% at an initial braking speed of 8 m/s, thereby improving safety and comfort. This work provides a new global perception method and local path planning method through Vehicle-Road-Cloud architecture, offering a new perceptual paradigm for achieving safer and more efficient autonomous driving.
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Apr 02, 2024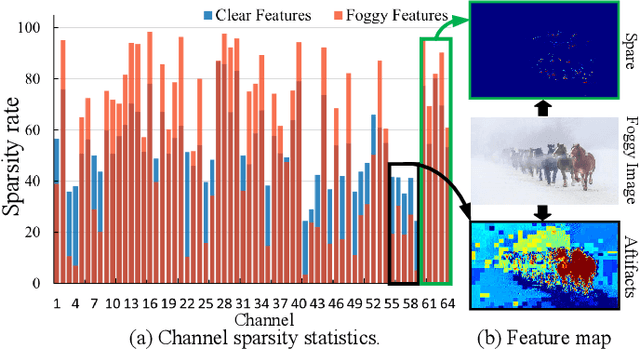
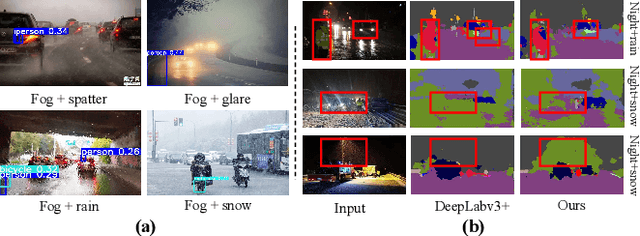
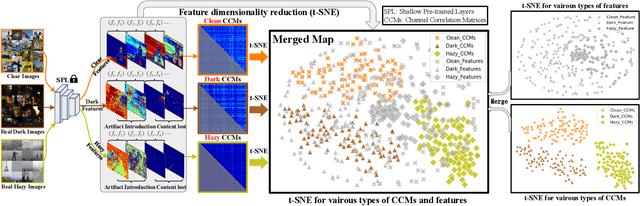
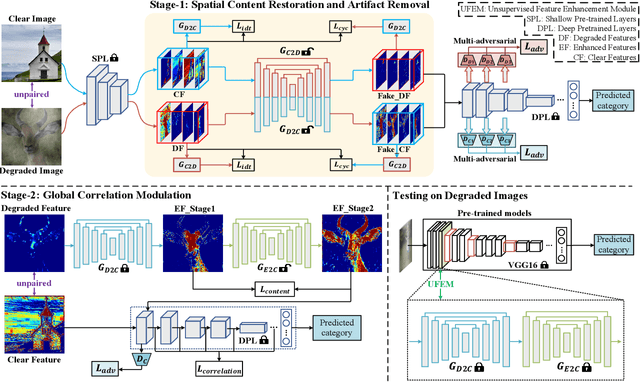
The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior
Second-Order Mirror Descent: Convergence in Games Beyond Averaging and Discounting
Nov 18, 2021

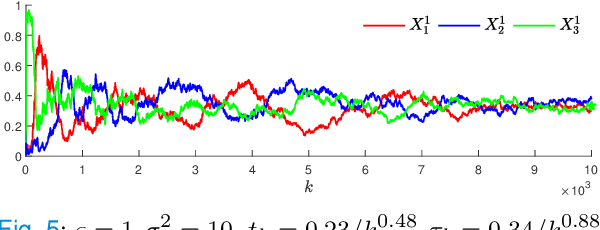
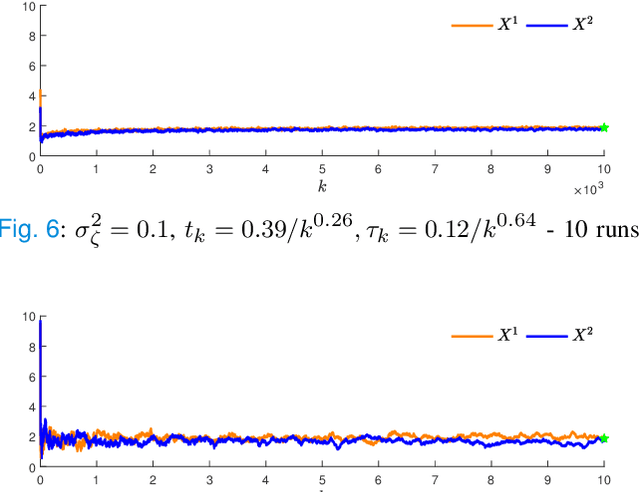
In this paper, we propose a second-order extension of the continuous-time game-theoretic mirror descent (MD) dynamics, referred to as MD2, which converges to mere (but not necessarily strict) variationally stable states (VSS) without using common auxiliary techniques such as averaging or discounting. We show that MD2 enjoys no-regret as well as exponential rate of convergence towards a strong VSS upon a slight modification. Furthermore, MD2 can be used to derive many novel primal-space dynamics. Lastly, using stochastic approximation techniques, we provide a convergence guarantee of discrete-time MD2 with noisy observations towards interior mere VSS. Selected simulations are provided to illustrate our results.
Continuous-time Discounted Mirror-Descent Dynamics in Monotone Concave Games
Dec 07, 2019
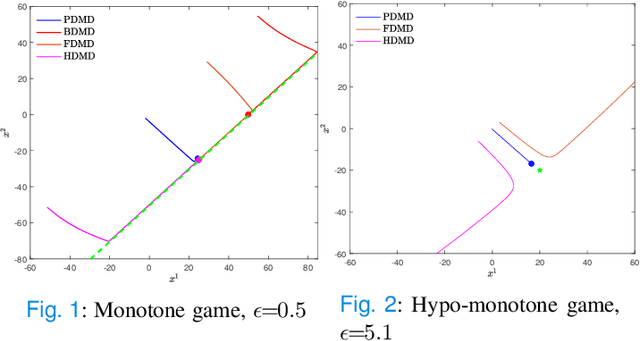
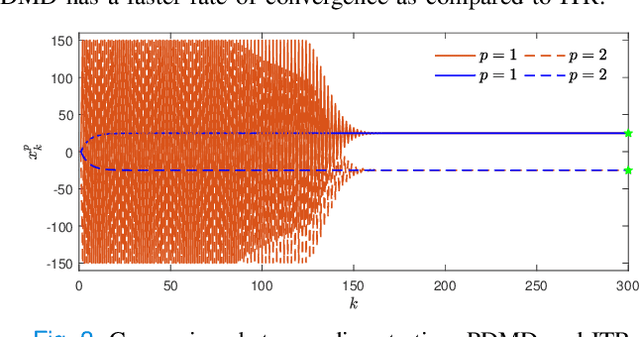
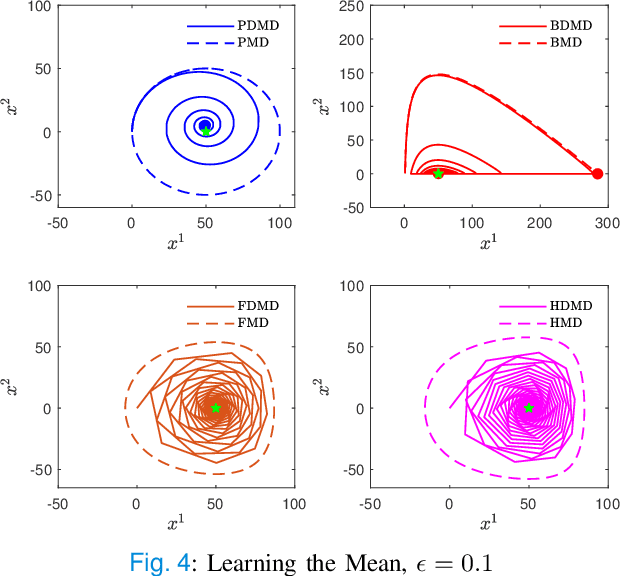
In this paper, we consider concave continuous-kernel games characterized by monotonicity properties and propose discounted mirror descent-type dynamics. We introduce two classes of dynamics whereby the associated mirror map is constructed based on a strongly convex or a Legendre regularizer. Depending on the properties of the regularizer we show that these new dynamics can converge asymptotically in concave games with monotone (negative) pseudo-gradient. Furthermore, we show that when the regularizer enjoys strong convexity, the resulting dynamics can converge even in games with hypo-monotone (negative) pseudo-gradient, which corresponds to a shortage of monotonicity.
On the Properties of the Softmax Function with Application in Game Theory and Reinforcement Learning
Aug 21, 2018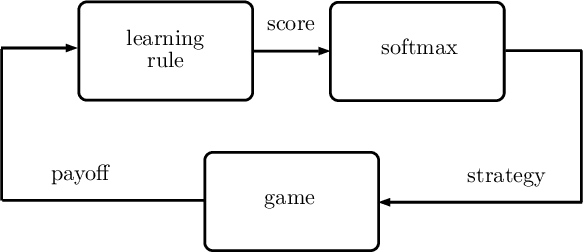
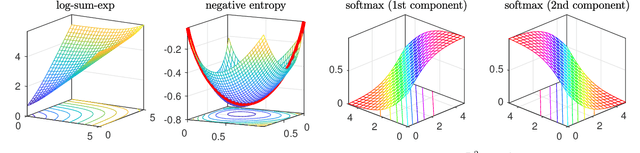
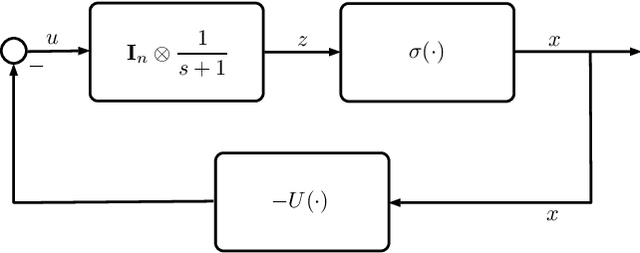
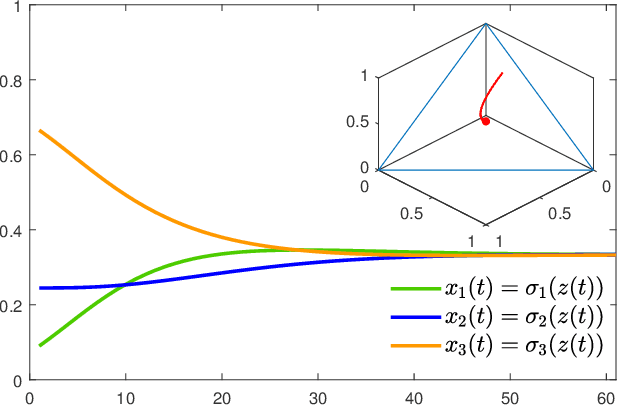
In this paper, we utilize results from convex analysis and monotone operator theory to derive additional properties of the softmax function that have not yet been covered in the existing literature. In particular, we show that the softmax function is the monotone gradient map of the log-sum-exp function. By exploiting this connection, we show that the inverse temperature parameter determines the Lipschitz and co-coercivity properties of the softmax function. We then demonstrate the usefulness of these properties through an application in game-theoretic reinforcement learning.