 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Image-Event Guided Low-Light Image Enhancement
Jun 06, 2025Under extreme low-light conditions, traditional frame-based cameras, due to their limited dynamic range and temporal resolution, face detail loss and motion blur in captured images. To overcome this bottleneck, researchers have introduced event cameras and proposed event-guided low-light image enhancement algorithms. However, these methods neglect the influence of global low-frequency noise caused by dynamic lighting conditions and local structural discontinuities in sparse event data. To address these issues, we propose an innovative Bidirectional guided Low-light Image Enhancement framework (BiLIE). Specifically, to mitigate the significant low-frequency noise introduced by global illumination step changes, we introduce the frequency high-pass filtering-based Event Feature Enhancement (EFE) module at the event representation level to suppress the interference of low-frequency information, and preserve and highlight the high-frequency edges.Furthermore, we design a Bidirectional Cross Attention Fusion (BCAF) mechanism to acquire high-frequency structures and edges while suppressing structural discontinuities and local noise introduced by sparse event guidance, thereby generating smoother fused representations.Additionally, considering the poor visual quality and color bias in existing datasets, we provide a new dataset (RELIE), with high-quality ground truth through a reliable enhancement scheme. Extensive experimental results demonstrate that our proposed BiLIE outperforms state-of-the-art methods by 0.96dB in PSNR and 0.03 in LPIPS.
DPMambaIR:All-in-One Image Restoration via Degradation-Aware Prompt State Space Model
Apr 24, 2025All-in-One image restoration aims to address multiple image degradation problems using a single model, significantly reducing training costs and deployment complexity compared to traditional methods that design dedicated models for each degradation type. Existing approaches typically rely on Degradation-specific models or coarse-grained degradation prompts to guide image restoration. However, they lack fine-grained modeling of degradation information and face limitations in balancing multi-task conflicts. To overcome these limitations, we propose DPMambaIR, a novel All-in-One image restoration framework. By integrating a Degradation-Aware Prompt State Space Model (DP-SSM) and a High-Frequency Enhancement Block (HEB), DPMambaIR enables fine-grained modeling of complex degradation information and efficient global integration, while mitigating the loss of high-frequency details caused by task competition. Specifically, the DP-SSM utilizes a pre-trained degradation extractor to capture fine-grained degradation features and dynamically incorporates them into the state space modeling process, enhancing the model's adaptability to diverse degradation types. Concurrently, the HEB supplements high-frequency information, effectively addressing the loss of critical details, such as edges and textures, in multi-task image restoration scenarios. Extensive experiments on a mixed dataset containing seven degradation types show that DPMambaIR achieves the best performance, with 27.69dB and 0.893 in PSNR and SSIM, respectively. These results highlight the potential and superiority of DPMambaIR as a unified solution for All-in-One image restoration.
SMamba: Sparse Mamba for Event-based Object Detection
Jan 21, 2025



Transformer-based methods have achieved remarkable performance in event-based object detection, owing to the global modeling ability. However, they neglect the influence of non-event and noisy regions and process them uniformly, leading to high computational overhead. To mitigate computation cost, some researchers propose window attention based sparsification strategies to discard unimportant regions, which sacrifices the global modeling ability and results in suboptimal performance. To achieve better trade-off between accuracy and efficiency, we propose Sparse Mamba (SMamba), which performs adaptive sparsification to reduce computational effort while maintaining global modeling capability. Specifically, a Spatio-Temporal Continuity Assessment module is proposed to measure the information content of tokens and discard uninformative ones by leveraging the spatiotemporal distribution differences between activity and noise events. Based on the assessment results, an Information-Prioritized Local Scan strategy is designed to shorten the scan distance between high-information tokens, facilitating interactions among them in the spatial dimension. Furthermore, to extend the global interaction from 2D space to 3D representations, a Global Channel Interaction module is proposed to aggregate channel information from a global spatial perspective. Results on three datasets (Gen1, 1Mpx, and eTram) demonstrate that our model outperforms other methods in both performance and efficiency.
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Apr 02, 2024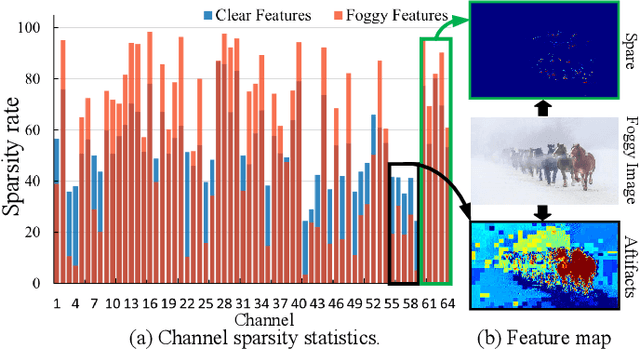
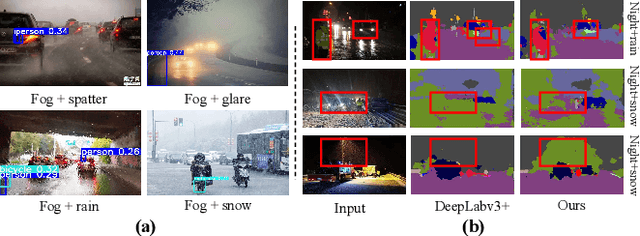
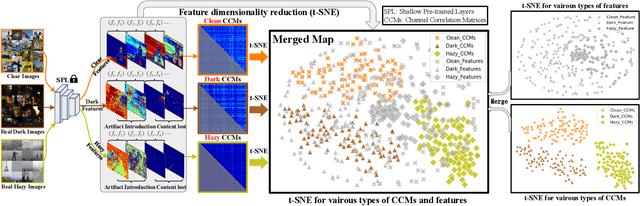
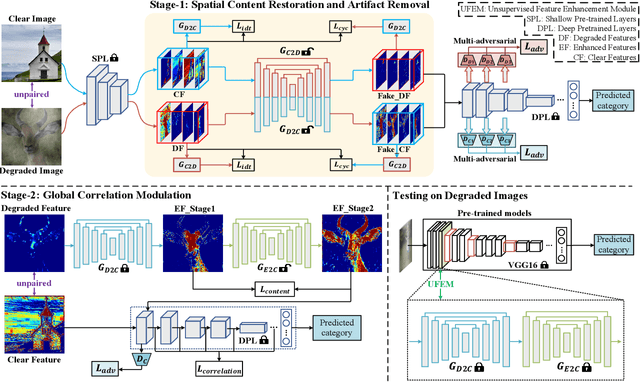
The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior