 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAS-TsC: A Data-Driven Framework for Estimating Time of Arrival Using Temporal-Attribute-Spatial Tri-space Coordination of Truck Trajectories
Dec 02, 2024



Accurately estimating time of arrival (ETA) for trucks is crucial for optimizing transportation efficiency in logistics. GPS trajectory data offers valuable information for ETA, but challenges arise due to temporal sparsity, variable sequence lengths, and the interdependencies among multiple trucks. To address these issues, we propose the Temporal-Attribute-Spatial Tri-space Coordination (TAS-TsC) framework, which leverages three feature spaces-temporal, attribute, and spatial-to enhance ETA. Our framework consists of a Temporal Learning Module (TLM) using state space models to capture temporal dependencies, an Attribute Extraction Module (AEM) that transforms sequential features into structured attribute embeddings, and a Spatial Fusion Module (SFM) that models the interactions among multiple trajectories using graph representation learning.These modules collaboratively learn trajectory embeddings, which are then used by a Downstream Prediction Module (DPM) to estimate arrival times. We validate TAS-TsC on real truck trajectory datasets collected from Shenzhen, China, demonstrating its superior performance compared to existing methods.
AGSENet: A Robust Road Ponding Detection Method for Proactive Traffic Safety
Oct 22, 2024



Road ponding, a prevalent traffic hazard, poses a serious threat to road safety by causing vehicles to lose control and leading to accidents ranging from minor fender benders to severe collisions. Existing technologies struggle to accurately identify road ponding due to complex road textures and variable ponding coloration influenced by reflection characteristics. To address this challenge, we propose a novel approach called Self-Attention-based Global Saliency-Enhanced Network (AGSENet) for proactive road ponding detection and traffic safety improvement. AGSENet incorporates saliency detection techniques through the Channel Saliency Information Focus (CSIF) and Spatial Saliency Information Enhancement (SSIE) modules. The CSIF module, integrated into the encoder, employs self-attention to highlight similar features by fusing spatial and channel information. The SSIE module, embedded in the decoder, refines edge features and reduces noise by leveraging correlations across different feature levels. To ensure accurate and reliable evaluation, we corrected significant mislabeling and missing annotations in the Puddle-1000 dataset. Additionally, we constructed the Foggy-Puddle and Night-Puddle datasets for road ponding detection in low-light and foggy conditions, respectively. Experimental results demonstrate that AGSENet outperforms existing methods, achieving IoU improvements of 2.03\%, 0.62\%, and 1.06\% on the Puddle-1000, Foggy-Puddle, and Night-Puddle datasets, respectively, setting a new state-of-the-art in this field. Finally, we verified the algorithm's reliability on edge computing devices. This work provides a valuable reference for proactive warning research in road traffic safety.
Unpaired MRI Super Resolution with Self-Supervised Contrastive Learning
Oct 24, 2023



High-resolution (HR) magnetic resonance imaging (MRI) is crucial for enhancing diagnostic accuracy in clinical settings. Nonetheless, the inherent limitation of MRI resolution restricts its widespread applicability. Deep learning-based image super-resolution (SR) methods exhibit promise in improving MRI resolution without additional cost. However, these methods frequently require a substantial number of HR MRI images for training, which can be challenging to acquire. In this paper, we propose an unpaired MRI SR approach that employs self-supervised contrastive learning to enhance SR performance with limited training data. Our approach leverages both authentic HR images and synthetically generated SR images to construct positive and negative sample pairs, thus facilitating the learning of discriminative features. Empirical results presented in this study underscore significant enhancements in the peak signal-to-noise ratio and structural similarity index, even when a paucity of HR images is available. These findings accentuate the potential of our approach in addressing the challenge of limited training data, thereby contributing to the advancement of high-resolution MRI in clinical applications.
Batch Implicit Neural Representation for MRI Parallel Reconstruction
Sep 13, 2023



Magnetic resonance imaging (MRI) always suffered from the problem of long acquisition time. MRI reconstruction is one solution to reduce scan time by skipping certain phase-encoding lines and then restoring high-quality images from undersampled measurements. Recently, implicit neural representation (INR) has emerged as a new deep learning method that represents an object as a continuous function of spatial coordinates, and this function is normally parameterized by a multilayer perceptron (MLP). In this paper, we propose a novel MRI reconstruction method based on INR, which represents the fully-sampled images as the function of pixel coordinates and prior feature vectors of undersampled images for overcoming the generalization problem of INR. Specifically, we introduce a scale-embedded encoder to produce scale-independent pixel-specific features from MR images with different undersampled scales and then concatenate with coordinates vectors to recover fully-sampled MR images via an MLP, thus achieving arbitrary scale reconstruction. The performance of the proposed method was assessed by experimenting on publicly available MRI datasets and compared with other reconstruction methods. Our quantitative evaluation demonstrates the superiority of the proposed method over alternative reconstruction methods.
UNAEN: Unsupervised Abnomality Extraction Network for MRI Motion Artifact Reduction
Jan 04, 2023


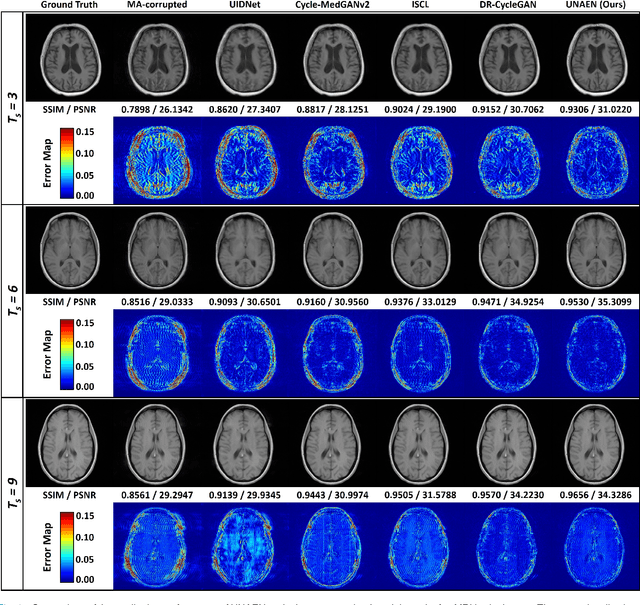
Motion artifact reduction is one of the most concerned problems in magnetic resonance imaging. As a promising solution, deep learning-based methods have been widely investigated for artifact reduction tasks in MRI. As a retrospective processing method, neural network does not cost additional acquisition time or require new acquisition equipment, and seems to work better than traditional artifact reduction methods. In the previous study, training such models require the paired motion-corrupted and motion-free MR images. However, it is extremely tough or even impossible to obtain these images in reality because patients have difficulty in maintaining the same state during two image acquisition, which makes the training in a supervised manner impractical. In this work, we proposed a new unsupervised abnomality extraction network (UNAEN) to alleviate this problem. Our network realizes the transition from artifact domain to motion-free domain by processing the abnormal information introduced by artifact in unpaired MR images. Different from directly generating artifact reduction results from motion-corrupted MR images, we adopted the strategy of abnomality extraction to indirectly correct the impact of artifact in MR images by learning the deep features. Experimental results show that our method is superior to state-of-the-art networks and can potentially be applied in real clinical settings.
Learn to Model Motion from Blurry Footages
Apr 19, 2017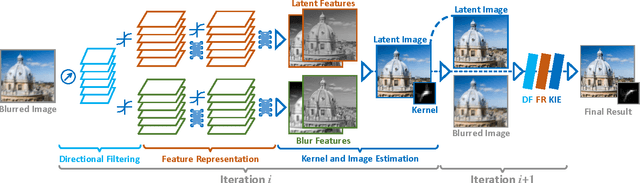


It is difficult to recover the motion field from a real-world footage given a mixture of camera shake and other photometric effects. In this paper we propose a hybrid framework by interleaving a Convolutional Neural Network (CNN) and a traditional optical flow energy. We first conduct a CNN architecture using a novel learnable directional filtering layer. Such layer encodes the angle and distance similarity matrix between blur and camera motion, which is able to enhance the blur features of the camera-shake footages. The proposed CNNs are then integrated into an iterative optical flow framework, which enable the capability of modelling and solving both the blind deconvolution and the optical flow estimation problems simultaneously. Our framework is trained end-to-end on a synthetic dataset and yields competitive precision and performance against the state-of-the-art approaches.
Nonrigid Optical Flow Ground Truth for Real-World Scenes with Time-Varying Shading Effects
Jul 15, 2016In this paper we present a dense ground truth dataset of nonrigidly deforming real-world scenes. Our dataset contains both long and short video sequences, and enables the quantitatively evaluation for RGB based tracking and registration methods. To construct ground truth for the RGB sequences, we simultaneously capture Near-Infrared (NIR) image sequences where dense markers - visible only in NIR - represent ground truth positions. This allows for comparison with automatically tracked RGB positions and the formation of error metrics. Most previous datasets containing nonrigidly deforming sequences are based on synthetic data. Our capture protocol enables us to acquire real-world deforming objects with realistic photometric effects - such as blur and illumination change - as well as occlusion and complex deformations. A public evaluation website is constructed to allow for ranking of RGB image based optical flow and other dense tracking algorithms, with various statistical measures. Furthermore, we present an RGB-NIR multispectral optical flow model allowing for energy optimization by adoptively combining featured information from both the RGB and the complementary NIR channels. In our experiments we evaluate eight existing RGB based optical flow methods on our new dataset. We also evaluate our hybrid optical flow algorithm by comparing to two existing multispectral approaches, as well as varying our input channels across RGB, NIR and RGB-NIR.
Preprint ARPPS Augmented Reality Pipeline Prospect System
Aug 18, 2015
This is the preprint version of our paper on ICONIP. Outdoor augmented reality geographic information system (ARGIS) is the hot application of augmented reality over recent years. This paper concludes the key solutions of ARGIS, designs the mobile augmented reality pipeline prospect system (ARPPS), and respectively realizes the machine vision based pipeline prospect system (MVBPPS) and the sensor based pipeline prospect system (SBPPS). With the MVBPPS's realization, this paper studies the neural network based 3D features matching method.
Preprint Extending Touch-less Interaction on Vision Based Wearable Device
Jul 29, 2015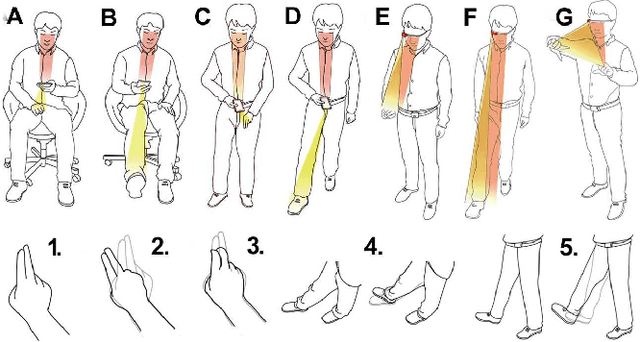
This is the preprint version of our paper on IEEE Virtual Reality Conference 2015. A touch-less interaction technology on vision based wearable device is designed and evaluated. Users interact with the application with dynamic hands/feet gestures in front of the camera. Several proof-of-concept prototypes with eleven dynamic gestures are developed based on the touch-less interaction. At last, a comparing user study evaluation is proposed to demonstrate the usability of the touch-less approach, as well as the impact on user's emotion, running on a wearable framework or Google Glass.