 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetup-Independent Full Projector Compensation
Apr 02, 2026Projector compensation seeks to correct geometric and photometric distortions that occur when images are projected onto nonplanar or textured surfaces. However, most existing methods are highly setup-dependent, requiring fine-tuning or retraining whenever the surface, lighting, or projector-camera pose changes. Progress has been limited by two key challenges: (1) the absence of large, diverse training datasets and (2) existing geometric correction models are typically constrained by specific spatial setups; without further retraining or fine-tuning, they often fail to generalize directly to novel geometric configurations. We introduce SIComp, the first Setup-Independent framework for full projector Compensation, capable of generalizing to unseen setups without fine-tuning or retraining. To enable this, we construct a large-scale real-world dataset spanning 277 distinct projector-camera setups. SIComp adopts a co-adaptive design that decouples geometry and photometry: A carefully tailored optical flow module performs online geometric correction, while a novel photometric network handles photometric compensation. To further enhance robustness under varying illumination, we integrate intensity-varying surface priors into the network design. Extensive experiments demonstrate that SIComp consistently produces high-quality compensation across diverse unseen setups, substantially outperforming existing methods in terms of generalization ability and establishing the first generalizable solution to projector compensation. The code and dataset are available on our project page: https://hai-bo-li.github.io/SIComp/
Non-invasive measuring method of skin temperature based on skin sensitivity index and deep learning
Dec 16, 2018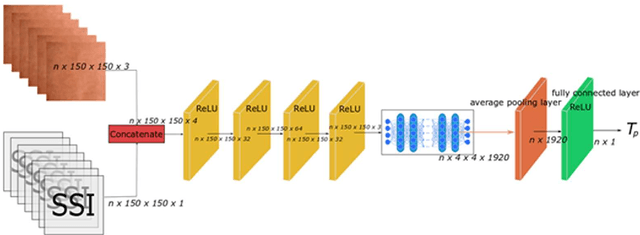

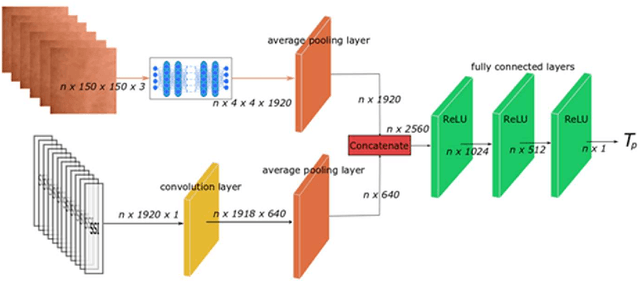
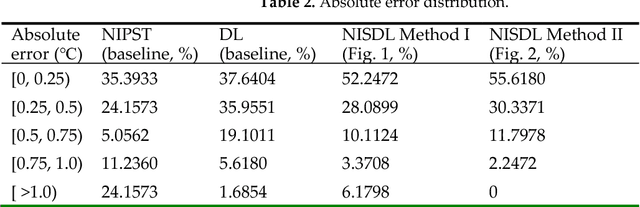
In human-centered intelligent building, real-time measurements of human thermal comfort play critical roles and supply feedback control signals for building heating, ventilation, and air conditioning (HVAC) systems. Due to the challenges of intra- and inter-individual differences and skin subtleness variations, there is no satisfactory solution for thermal comfort measurements until now. In this paper, a non-invasive measuring method based on skin sensitivity index and deep learning (NISDL) was proposed to measure real-time skin temperature. A new evaluating index, named skin sensitivity index (SSI), was defined to overcome individual differences and skin subtleness variations. To illustrate the effectiveness of SSI proposed, two multi-layers deep learning framework (NISDL method I and II) was designed and the DenseNet201 was used for extracting features from skin images. The partly personal saturation temperature (NIPST) algorithm was use for algorithm comparisons. Another deep learning algorithm without SSI (DL) was also generated for algorithm comparisons. Finally, a total of 1.44 million image data was used for algorithm validation. The results show that 55.6180% and 52.2472% error values (NISDL method I, II) are scattered at [0, 0.25), and the same error intervals distribution of NIPST is 35.3933%.
Non-invasive thermal comfort perception based on subtleness magnification and deep learning for energy efficiency
Nov 12, 2018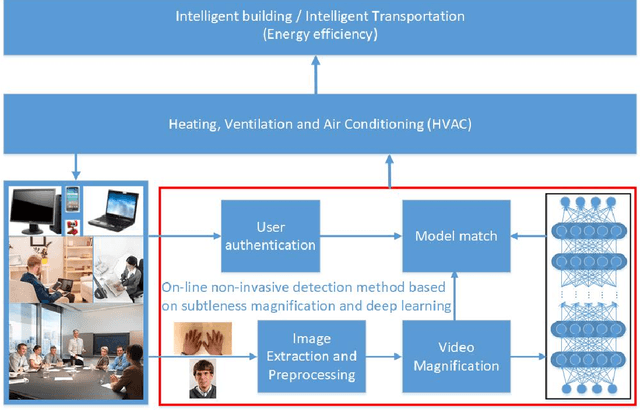
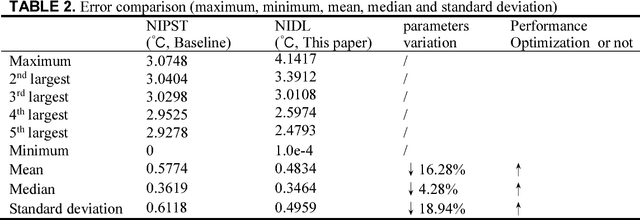
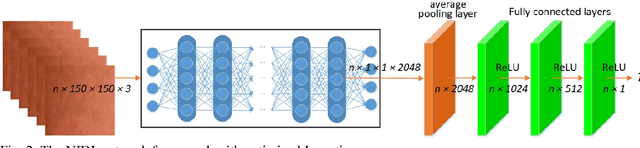
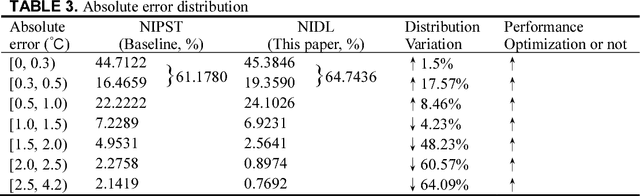
Human thermal comfort measurement plays a critical role in giving feedback signals for building energy efficiency. A non-invasive measuring method based on subtleness magnification and deep learning (NIDL) was designed to achieve a comfortable, energy efficient built environment. The method relies on skin feature data, e.g., subtle motion and texture variation, and a 315-layer deep neural network for constructing the relationship between skin features and skin temperature. A physiological experiment was conducted for collecting feature data (1.44 million) and algorithm validation. The non-invasive measurement algorithm based on a partly-personalized saturation temperature model (NIPST) was used for algorithm performance comparisons. The results show that the mean error and median error of the NIDL are 0.4834 Celsius and 0.3464 Celsius which is equivalent to accuracy improvements of 16.28% and 4.28%, respectively.
Expressway visibility estimation based on image entropy and piecewise stationary time series analysis
Apr 08, 2018



Vision-based methods for visibility estimation can play a critical role in reducing traffic accidents caused by fog and haze. To overcome the disadvantages of current visibility estimation methods, we present a novel data-driven approach based on Gaussian image entropy and piecewise stationary time series analysis (SPEV). This is the first time that Gaussian image entropy is used for estimating atmospheric visibility. To lessen the impact of landscape and sunshine illuminance on visibility estimation, we used region of interest (ROI) analysis and took into account relative ratios of image entropy, to improve estimation accuracy. We assume fog and haze cause blurred images and that fog and haze can be considered as a piecewise stationary signal. We used piecewise stationary time series analysis to construct the piecewise causal relationship between image entropy and visibility. To obtain a real-world visibility measure during fog and haze, a subjective assessment was established through a study with 36 subjects who performed visibility observations. Finally, a total of two million videos were used for training the SPEV model and validate its effectiveness. The videos were collected from the constantly foggy and hazy Tongqi expressway in Jiangsu, China. The contrast model of visibility estimation was used for algorithm performance comparison, and the validation results of the SPEV model were encouraging as 99.14% of the relative errors were less than 10%.
Leveraging Mid-Level Deep Representations For Predicting Face Attributes in the Wild
Jun 21, 2016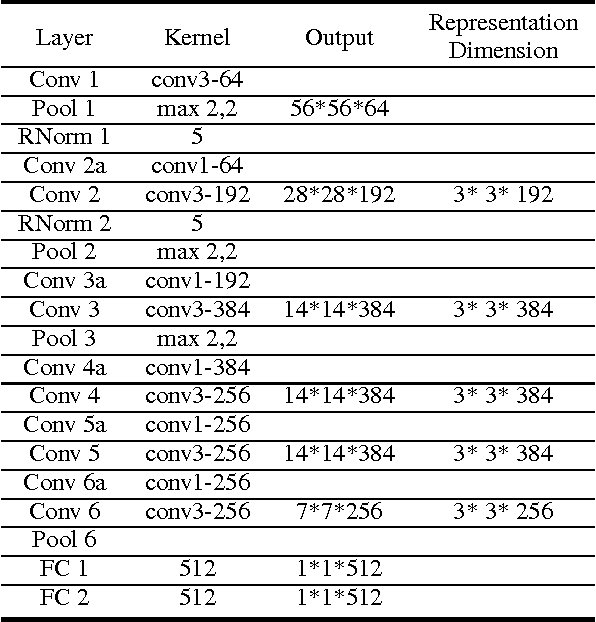
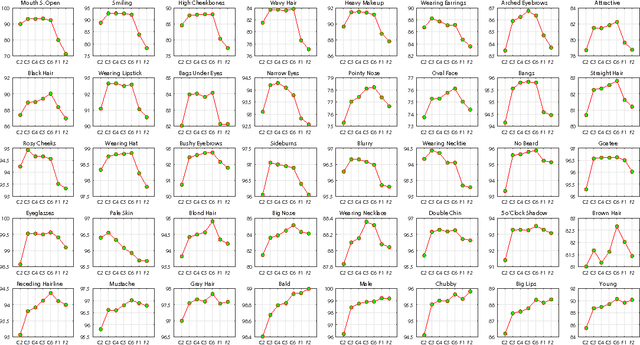
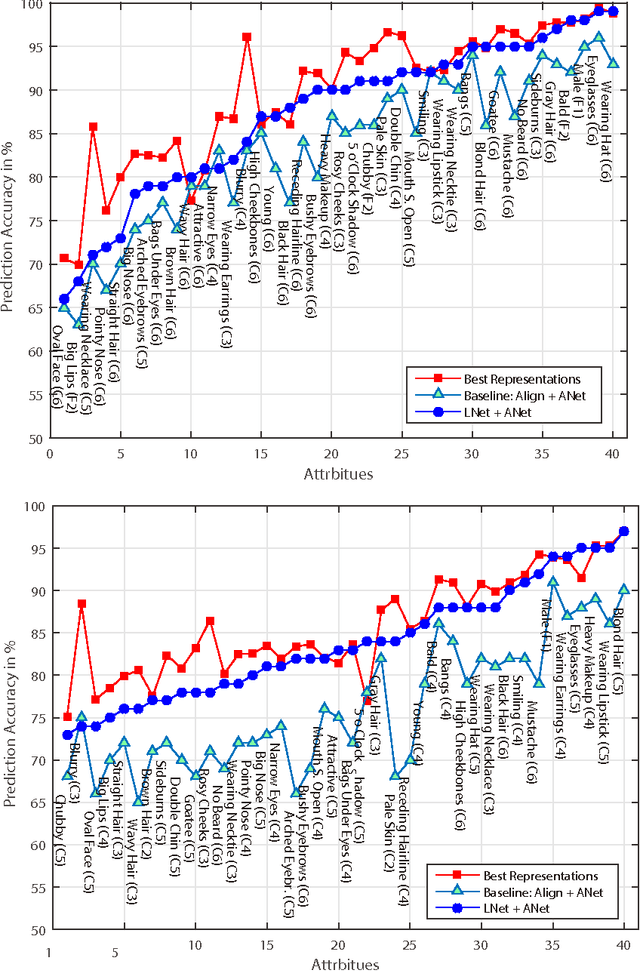
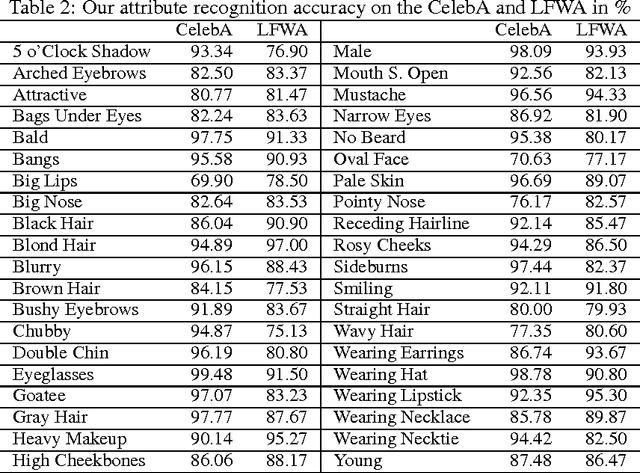
Predicting facial attributes from faces in the wild is very challenging due to pose and lighting variations in the real world. The key to this problem is to build proper feature representations to cope with these unfavourable conditions. Given the success of Convolutional Neural Network (CNN) in image classification, the high-level CNN feature, as an intuitive and reasonable choice, has been widely utilized for this problem. In this paper, however, we consider the mid-level CNN features as an alternative to the high-level ones for attribute prediction. This is based on the observation that face attributes are different: some of them are locally oriented while others are globally defined. Our investigations reveal that the mid-level deep representations outperform the prediction accuracy achieved by the (fine-tuned) high-level abstractions. We empirically demonstrate that the midlevel representations achieve state-of-the-art prediction performance on CelebA and LFWA datasets. Our investigations also show that by utilizing the mid-level representations one can employ a single deep network to achieve both face recognition and attribute prediction.
Face Attribute Prediction Using Off-the-Shelf CNN Features
Jun 21, 2016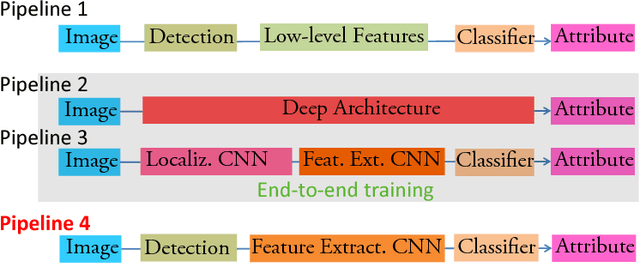
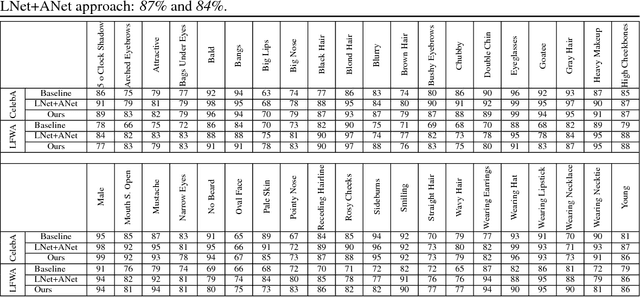
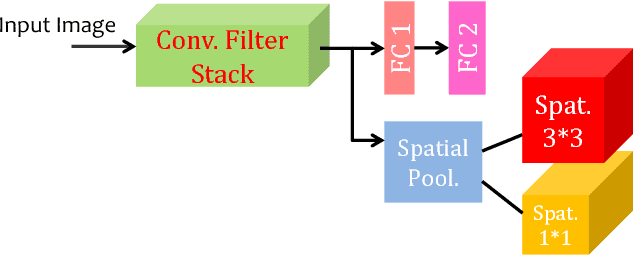
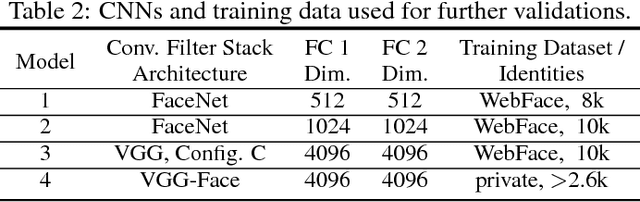
Predicting attributes from face images in the wild is a challenging computer vision problem. To automatically describe face attributes from face containing images, traditionally one needs to cascade three technical blocks --- face localization, facial descriptor construction, and attribute classification --- in a pipeline. As a typical classification problem, face attribute prediction has been addressed using deep learning. Current state-of-the-art performance was achieved by using two cascaded Convolutional Neural Networks (CNNs), which were specifically trained to learn face localization and attribute description. In this paper, we experiment with an alternative way of employing the power of deep representations from CNNs. Combining with conventional face localization techniques, we use off-the-shelf architectures trained for face recognition to build facial descriptors. Recognizing that the describable face attributes are diverse, our face descriptors are constructed from different levels of the CNNs for different attributes to best facilitate face attribute prediction. Experiments on two large datasets, LFWA and CelebA, show that our approach is entirely comparable to the state-of-the-art. Our findings not only demonstrate an efficient face attribute prediction approach, but also raise an important question: how to leverage the power of off-the-shelf CNN representations for novel tasks.
Preprint Extending Touch-less Interaction on Vision Based Wearable Device
Jul 29, 2015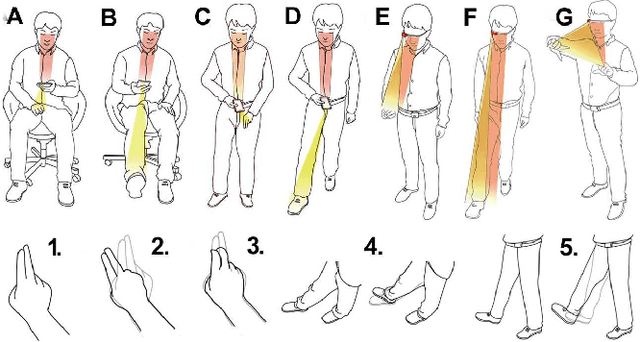
This is the preprint version of our paper on IEEE Virtual Reality Conference 2015. A touch-less interaction technology on vision based wearable device is designed and evaluated. Users interact with the application with dynamic hands/feet gestures in front of the camera. Several proof-of-concept prototypes with eleven dynamic gestures are developed based on the touch-less interaction. At last, a comparing user study evaluation is proposed to demonstrate the usability of the touch-less approach, as well as the impact on user's emotion, running on a wearable framework or Google Glass.
Leveraging the Power of Gabor Phase for Face Identification: A Block Matching Approach
Jun 15, 2015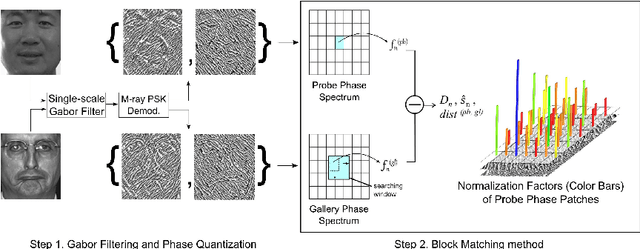
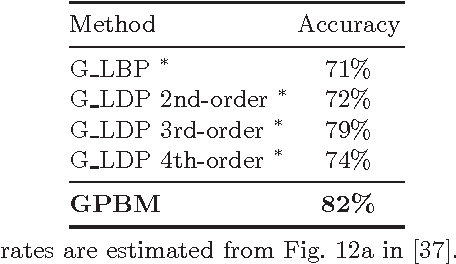
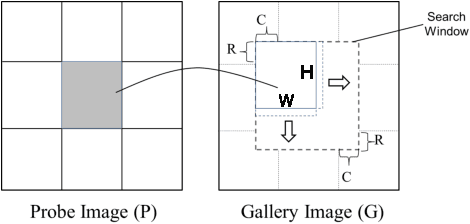
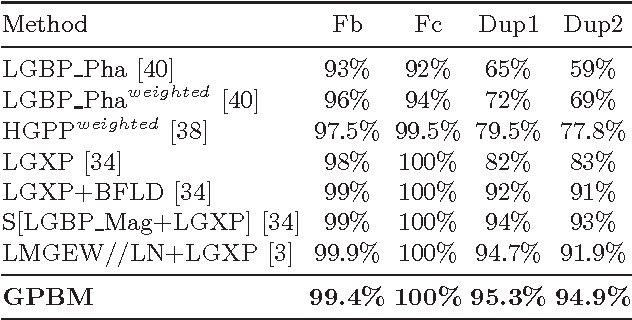
Different from face verification, face identification is much more demanding. To reach comparable performance, an identifier needs to be roughly N times better than a verifier. To expect a breakthrough in face identification, we need a fresh look at the fundamental building blocks of face recognition. In this paper we focus on the selection of a suitable signal representation and better matching strategy for face identification. We demonstrate how Gabor phase could be leveraged to improve the performance of face identification by using the Block Matching method. Compared to the existing approaches, the proposed method features much lower algorithmic complexity: face images are only filtered by a single-scale Gabor filter pair and the matching is performed between any pairs of face images at hand without involving any training process. Benchmark evaluations show that the proposed approach is totally comparable to and even better than state-of-the-art algorithms, which are typically based on more features extracted from a large set of Gabor faces and/or rely on heavy training processes.