 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Mid-Level Deep Representations For Predicting Face Attributes in the Wild
Paper and Code
Jun 21, 2016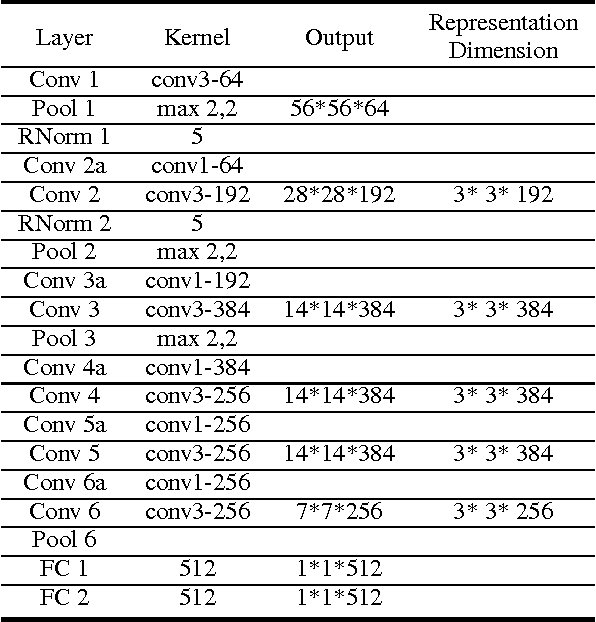
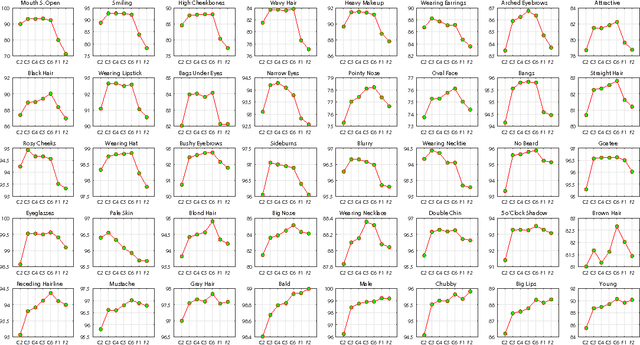
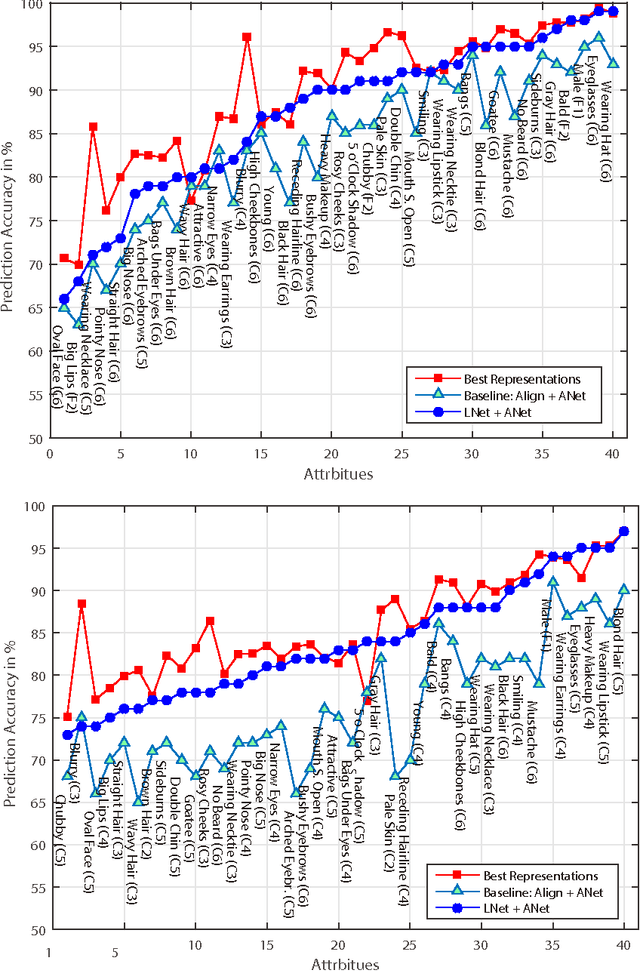
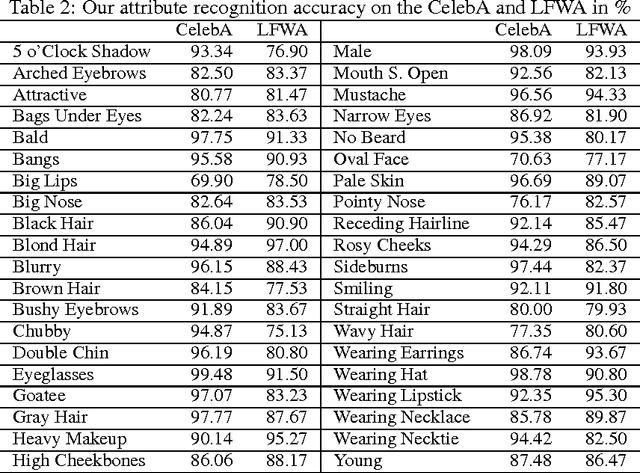
Predicting facial attributes from faces in the wild is very challenging due to pose and lighting variations in the real world. The key to this problem is to build proper feature representations to cope with these unfavourable conditions. Given the success of Convolutional Neural Network (CNN) in image classification, the high-level CNN feature, as an intuitive and reasonable choice, has been widely utilized for this problem. In this paper, however, we consider the mid-level CNN features as an alternative to the high-level ones for attribute prediction. This is based on the observation that face attributes are different: some of them are locally oriented while others are globally defined. Our investigations reveal that the mid-level deep representations outperform the prediction accuracy achieved by the (fine-tuned) high-level abstractions. We empirically demonstrate that the midlevel representations achieve state-of-the-art prediction performance on CelebA and LFWA datasets. Our investigations also show that by utilizing the mid-level representations one can employ a single deep network to achieve both face recognition and attribute prediction.