 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANSION: Multi-floor lANguage-to-3D Scene generatIOn for loNg-horizon tasks
Mar 12, 2026Real-world robotic tasks are long-horizon and often span multiple floors, demanding rich spatial reasoning. However, existing embodied benchmarks are largely confined to single-floor in-house environments, failing to reflect the complexity of real-world tasks. We introduce MANSION, the first language-driven framework for generating building-scale, multi-floor 3D environments. Being aware of vertical structural constraints, MANSION generates realistic, navigable whole-building structures with diverse, human-friendly scenes, enabling the development and evaluation of cross-floor long-horizon tasks. Building on this framework, we release MansionWorld, a dataset of over 1,000 diverse buildings ranging from hospitals to offices, alongside a Task-Semantic Scene Editing Agent that customizes these environments using open-vocabulary commands to meet specific user needs. Benchmarking reveals that state-of-the-art agents degrade sharply in our settings, establishing MANSION as a critical testbed for the next generation of spatial reasoning and planning.
AMP2026: A Multi-Platform Marine Robotics Dataset for Tracking and Mapping
Mar 04, 2026Marine environments present significant challenges for perception and autonomy due to dynamic surfaces, limited visibility, and complex interactions between aerial, surface, and submerged sensing modalities. This paper introduces the Aerial Marine Perception Dataset (AMP2026), a multi-platform marine robotics dataset collected across multiple field deployments designed to support research in two primary areas: multi-view tracking and marine environment mapping. The dataset includes synchronized data from aerial drones, boat-mounted cameras, and submerged robotic platforms, along with associated localization and telemetry information. The goal of this work is to provide a publicly available dataset enabling research in marine perception and multi-robot observation scenarios. This paper describes the data collection methodology, sensor configurations, dataset organization, and intended research tasks supported by the dataset.
Revisiting the Platonic Representation Hypothesis: An Aristotelian View
Feb 16, 2026The Platonic Representation Hypothesis suggests that representations from neural networks are converging to a common statistical model of reality. We show that the existing metrics used to measure representational similarity are confounded by network scale: increasing model depth or width can systematically inflate representational similarity scores. To correct these effects, we introduce a permutation-based null-calibration framework that transforms any representational similarity metric into a calibrated score with statistical guarantees. We revisit the Platonic Representation Hypothesis with our calibration framework, which reveals a nuanced picture: the apparent convergence reported by global spectral measures largely disappears after calibration, while local neighborhood similarity, but not local distances, retains significant agreement across different modalities. Based on these findings, we propose the Aristotelian Representation Hypothesis: representations in neural networks are converging to shared local neighborhood relationships.
Embodied AI-Enhanced IoMT Edge Computing: UAV Trajectory Optimization and Task Offloading with Mobility Prediction
Dec 24, 2025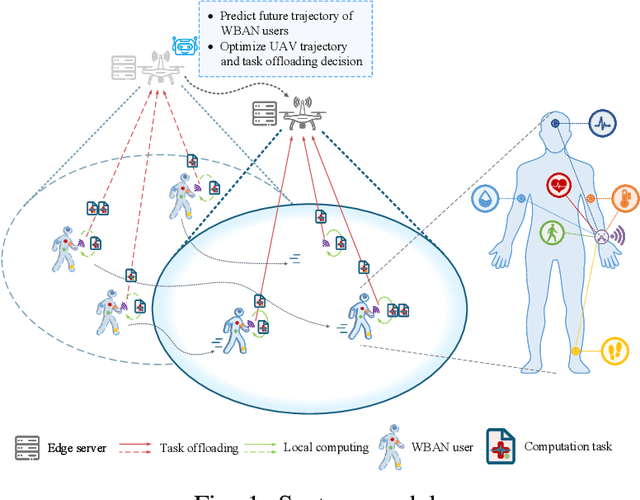
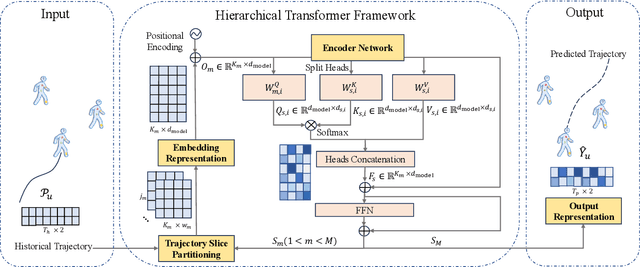
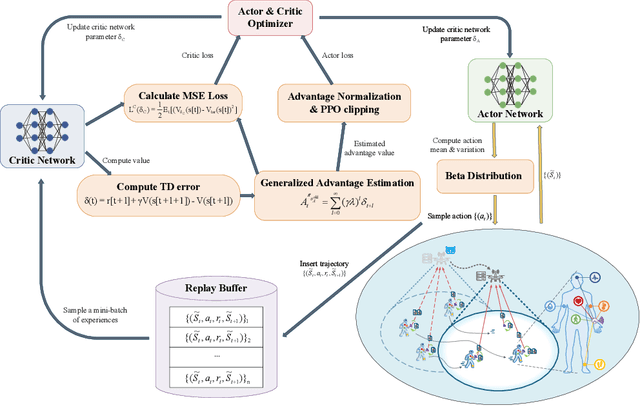
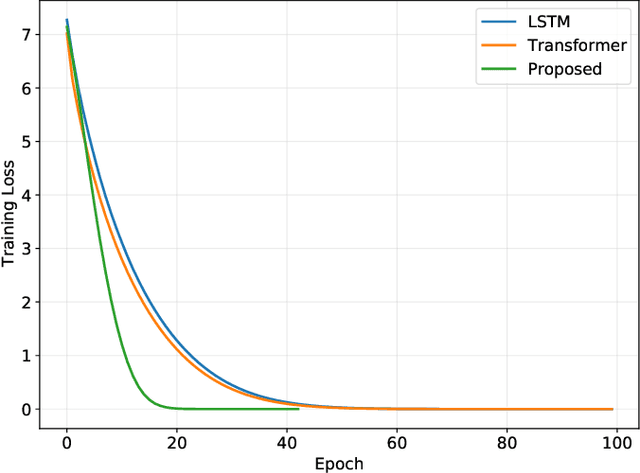
Due to their inherent flexibility and autonomous operation, unmanned aerial vehicles (UAVs) have been widely used in Internet of Medical Things (IoMT) to provide real-time biomedical edge computing service for wireless body area network (WBAN) users. In this paper, considering the time-varying task criticality characteristics of diverse WBAN users and the dual mobility between WBAN users and UAV, we investigate the dynamic task offloading and UAV flight trajectory optimization problem to minimize the weighted average task completion time of all the WBAN users, under the constraint of UAV energy consumption. To tackle the problem, an embodied AI-enhanced IoMT edge computing framework is established. Specifically, we propose a novel hierarchical multi-scale Transformer-based user trajectory prediction model based on the users' historical trajectory traces captured by the embodied AI agent (i.e., UAV). Afterwards, a prediction-enhanced deep reinforcement learning (DRL) algorithm that integrates predicted users' mobility information is designed for intelligently optimizing UAV flight trajectory and task offloading decisions. Real-word movement traces and simulation results demonstrate the superiority of the proposed methods in comparison with the existing benchmarks.
On Mobile Ad Hoc Networks for Coverage of Partially Observable Worlds
Dec 10, 2025This paper addresses the movement and placement of mobile agents to establish a communication network in initially unknown environments. We cast the problem in a computational-geometric framework by relating the coverage problem and line-of-sight constraints to the Cooperative Guard Art Gallery Problem, and introduce its partially observable variant, the Partially Observable Cooperative Guard Art Gallery Problem (POCGAGP). We then present two algorithms that solve POCGAGP: CADENCE, a centralized planner that incrementally selects 270 degree corners at which to deploy agents, and DADENCE, a decentralized scheme that coordinates agents using local information and lightweight messaging. Both approaches operate under partial observability and target simultaneous coverage and connectivity. We evaluate the methods in simulation across 1,500 test cases of varied size and structure, demonstrating consistent success in forming connected networks while covering and exploring unknown space. These results highlight the value of geometric abstractions for communication-driven exploration and show that decentralized policies are competitive with centralized performance while retaining scalability.
Scalable Aerial GNSS Localization for Marine Robots
May 07, 2025



Accurate localization is crucial for water robotics, yet traditional onboard Global Navigation Satellite System (GNSS) approaches are difficult or ineffective due to signal reflection on the water's surface and its high cost of aquatic GNSS receivers. Existing approaches, such as inertial navigation, Doppler Velocity Loggers (DVL), SLAM, and acoustic-based methods, face challenges like error accumulation and high computational complexity. Therefore, a more efficient and scalable solution remains necessary. This paper proposes an alternative approach that leverages an aerial drone equipped with GNSS localization to track and localize a marine robot once it is near the surface of the water. Our results show that this novel adaptation enables accurate single and multi-robot marine robot localization.
Crime Forecasting: A Spatio-temporal Analysis with Deep Learning Models
Feb 11, 2025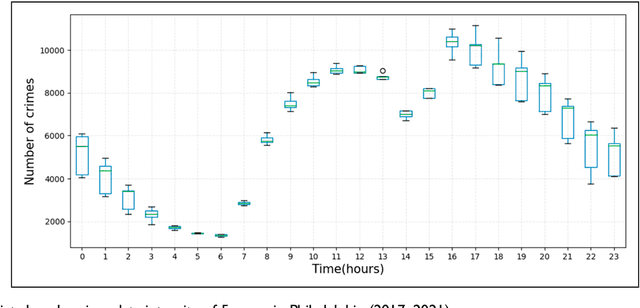
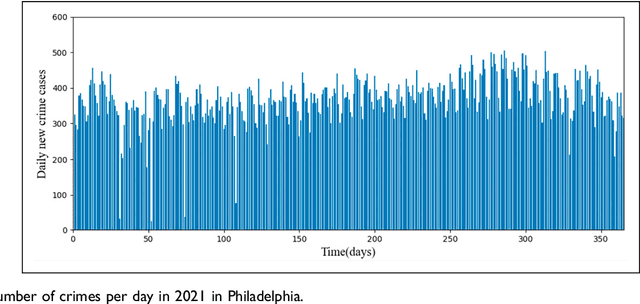
This study uses deep-learning models to predict city partition crime counts on specific days. It helps police enhance surveillance, gather intelligence, and proactively prevent crimes. We formulate crime count prediction as a spatiotemporal sequence challenge, where both input data and prediction targets are spatiotemporal sequences. In order to improve the accuracy of crime forecasting, we introduce a new model that combines Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks. We conducted a comparative analysis to access the effects of various data sequences, including raw and binned data, on the prediction errors of four deep learning forecasting models. Directly inputting raw crime data into the forecasting model causes high prediction errors, making the model unsuitable for real - world use. The findings indicate that the proposed CNN-LSTM model achieves optimal performance when crime data is categorized into 10 or 5 groups. Data binning can enhance forecasting model performance, but poorly defined intervals may reduce map granularity. Compared to dividing into 5 bins, binning into 10 intervals strikes an optimal balance, preserving data characteristics and surpassing raw data in predictive modelling efficacy.
Cross-domain Open-world Discovery
Jun 17, 2024



In many real-world applications, test data may commonly exhibit categorical shifts, characterized by the emergence of novel classes, as well as distribution shifts arising from feature distributions different from the ones the model was trained on. However, existing methods either discover novel classes in the open-world setting or assume domain shifts without the ability to discover novel classes. In this work, we consider a cross-domain open-world discovery setting, where the goal is to assign samples to seen classes and discover unseen classes under a domain shift. To address this challenging problem, we present CROW, a prototype-based approach that introduces a cluster-then-match strategy enabled by a well-structured representation space of foundation models. In this way, CROW discovers novel classes by robustly matching clusters with previously seen classes, followed by fine-tuning the representation space using an objective designed for cross-domain open-world discovery. Extensive experimental results on image classification benchmark datasets demonstrate that CROW outperforms alternative baselines, achieving an 8% average performance improvement across 75 experimental settings.