 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
Jan 02, 2026Diffusion policies have emerged as powerful generative models for offline policy learning, whose sampling process can be rigorously characterized by a score function guiding a Stochastic Differential Equation (SDE). However, the same score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs solver and score-matching errors, large data requirements, and inconsistencies in action generation. While less critical in image generation, these inaccuracies compound and lead to failure in continuous control settings. We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the diffusion sampling dynamics. Contraction pulls nearby flows closer to enhance robustness against solver and score-matching errors while reducing unwanted action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and computational cost. We evaluate CDPs for offline learning by conducting extensive experiments in simulation and real-world settings. Across benchmarks, CDPs often outperform baseline policies, with pronounced benefits under data scarcity.
Scalable Aerial GNSS Localization for Marine Robots
May 07, 2025Accurate localization is crucial for water robotics, yet traditional onboard Global Navigation Satellite System (GNSS) approaches are difficult or ineffective due to signal reflection on the water's surface and its high cost of aquatic GNSS receivers. Existing approaches, such as inertial navigation, Doppler Velocity Loggers (DVL), SLAM, and acoustic-based methods, face challenges like error accumulation and high computational complexity. Therefore, a more efficient and scalable solution remains necessary. This paper proposes an alternative approach that leverages an aerial drone equipped with GNSS localization to track and localize a marine robot once it is near the surface of the water. Our results show that this novel adaptation enables accurate single and multi-robot marine robot localization.
A Study of Human-Robot Handover through Human-Human Object Transfer
Nov 21, 2023



In this preliminary study, we investigate changes in handover behaviour when transferring hazardous objects with the help of a high-resolution touch sensor. Participants were asked to hand over a safe and hazardous object (a full cup and an empty cup) while instrumented with a modified STS sensor. Our data shows a clear distinction in the length of handover for the full cup vs the empty one, with the former being slower. Sensor data further suggests a change in tactile behaviour dependent on the object's risk factor. The results of this paper motivate a deeper study of tactile factors which could characterize a risky handover, allowing for safer human-robot interactions in the future.
Hypernetworks for Zero-shot Transfer in Reinforcement Learning
Nov 28, 2022
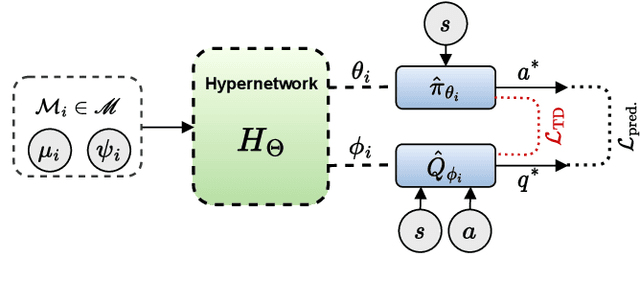
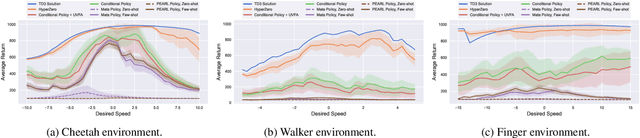
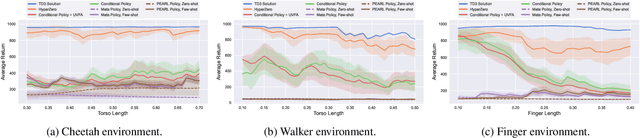
In this paper, hypernetworks are trained to generate behaviors across a range of unseen task conditions, via a novel TD-based training objective and data from a set of near-optimal RL solutions for training tasks. This work relates to meta RL, contextual RL, and transfer learning, with a particular focus on zero-shot performance at test time, enabled by knowledge of the task parameters (also known as context). Our technical approach is based upon viewing each RL algorithm as a mapping from the MDP specifics to the near-optimal value function and policy and seek to approximate it with a hypernetwork that can generate near-optimal value functions and policies, given the parameters of the MDP. We show that, under certain conditions, this mapping can be considered as a supervised learning problem. We empirically evaluate the effectiveness of our method for zero-shot transfer to new reward and transition dynamics on a series of continuous control tasks from DeepMind Control Suite. Our method demonstrates significant improvements over baselines from multitask and meta RL approaches.