 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Heavily-Degraded Prior for Underwater Object Detection
Aug 24, 2023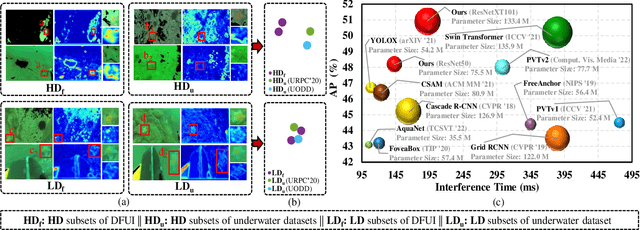
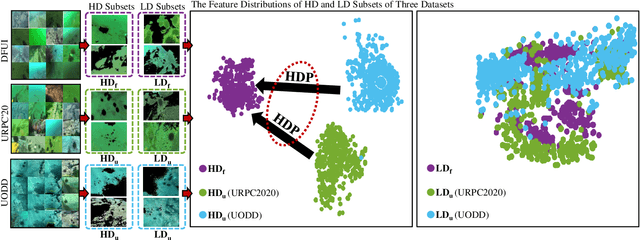

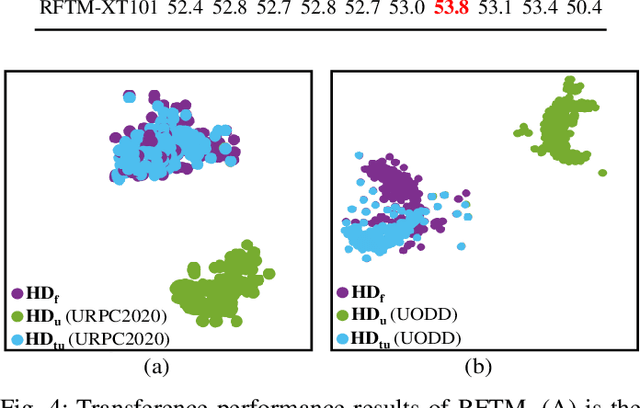
Underwater object detection suffers from low detection performance because the distance and wavelength dependent imaging process yield evident image quality degradations such as haze-like effects, low visibility, and color distortions. Therefore, we commit to resolving the issue of underwater object detection with compounded environmental degradations. Typical approaches attempt to develop sophisticated deep architecture to generate high-quality images or features. However, these methods are only work for limited ranges because imaging factors are either unstable, too sensitive, or compounded. Unlike these approaches catering for high-quality images or features, this paper seeks transferable prior knowledge from detector-friendly images. The prior guides detectors removing degradations that interfere with detection. It is based on statistical observations that, the heavily degraded regions of detector-friendly (DFUI) and underwater images have evident feature distribution gaps while the lightly degraded regions of them overlap each other. Therefore, we propose a residual feature transference module (RFTM) to learn a mapping between deep representations of the heavily degraded patches of DFUI- and underwater- images, and make the mapping as a heavily degraded prior (HDP) for underwater detection. Since the statistical properties are independent to image content, HDP can be learned without the supervision of semantic labels and plugged into popular CNNbased feature extraction networks to improve their performance on underwater object detection. Without bells and whistles, evaluations on URPC2020 and UODD show that our methods outperform CNN-based detectors by a large margin. Our method with higher speeds and less parameters still performs better than transformer-based detectors. Our code and DFUI dataset can be found in https://github.com/xiaoDetection/Learning-Heavily-Degraed-Prior.
Joint Perceptual Learning for Enhancement and Object Detection in Underwater Scenarios
Jul 07, 2023



Underwater degraded images greatly challenge existing algorithms to detect objects of interest. Recently, researchers attempt to adopt attention mechanisms or composite connections for improving the feature representation of detectors. However, this solution does \textit{not} eliminate the impact of degradation on image content such as color and texture, achieving minimal improvements. Another feasible solution for underwater object detection is to develop sophisticated deep architectures in order to enhance image quality or features. Nevertheless, the visually appealing output of these enhancement modules do \textit{not} necessarily generate high accuracy for deep detectors. More recently, some multi-task learning methods jointly learn underwater detection and image enhancement, accessing promising improvements. Typically, these methods invoke huge architecture and expensive computations, rendering inefficient inference. Definitely, underwater object detection and image enhancement are two interrelated tasks. Leveraging information coming from the two tasks can benefit each task. Based on these factual opinions, we propose a bilevel optimization formulation for jointly learning underwater object detection and image enhancement, and then unroll to a dual perception network (DPNet) for the two tasks. DPNet with one shared module and two task subnets learns from the two different tasks, seeking a shared representation. The shared representation provides more structural details for image enhancement and rich content information for object detection. Finally, we derive a cooperative training strategy to optimize parameters for DPNet. Extensive experiments on real-world and synthetic underwater datasets demonstrate that our method outputs visually favoring images and higher detection accuracy.
Taxonomy and evolution predicting using deep learning in images
Jun 28, 2022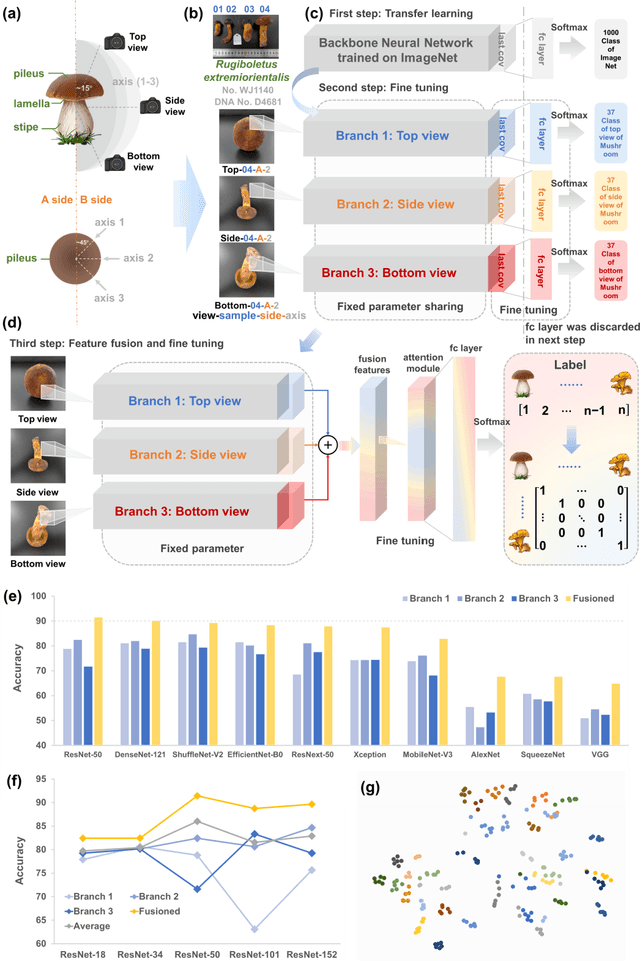
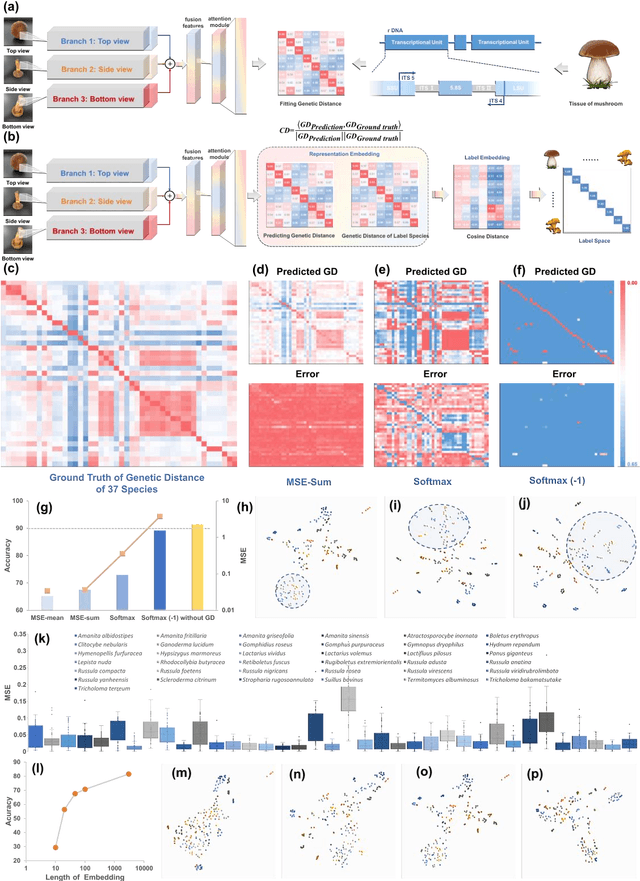
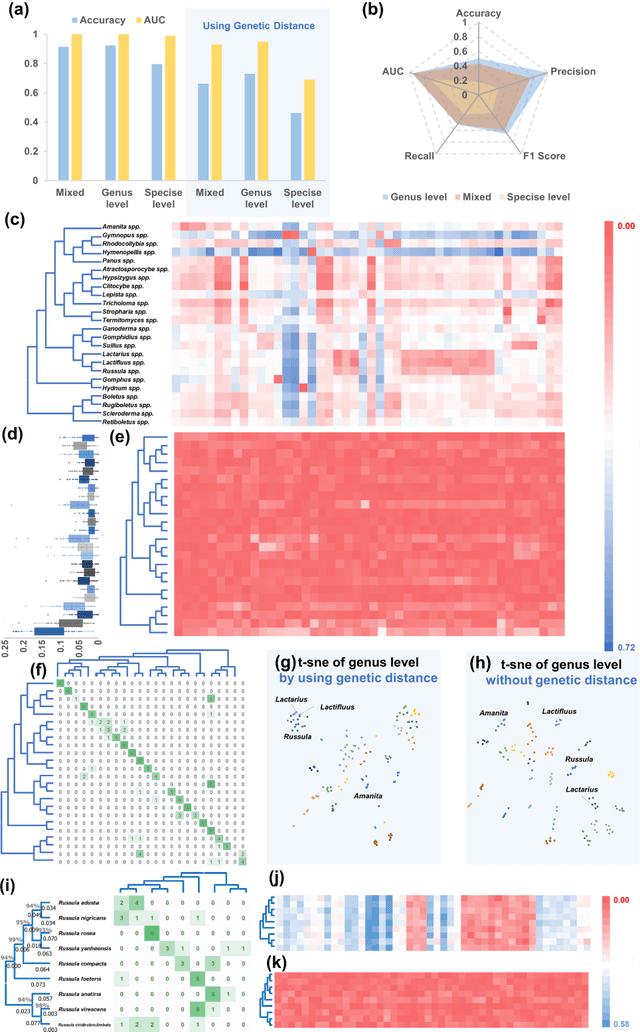
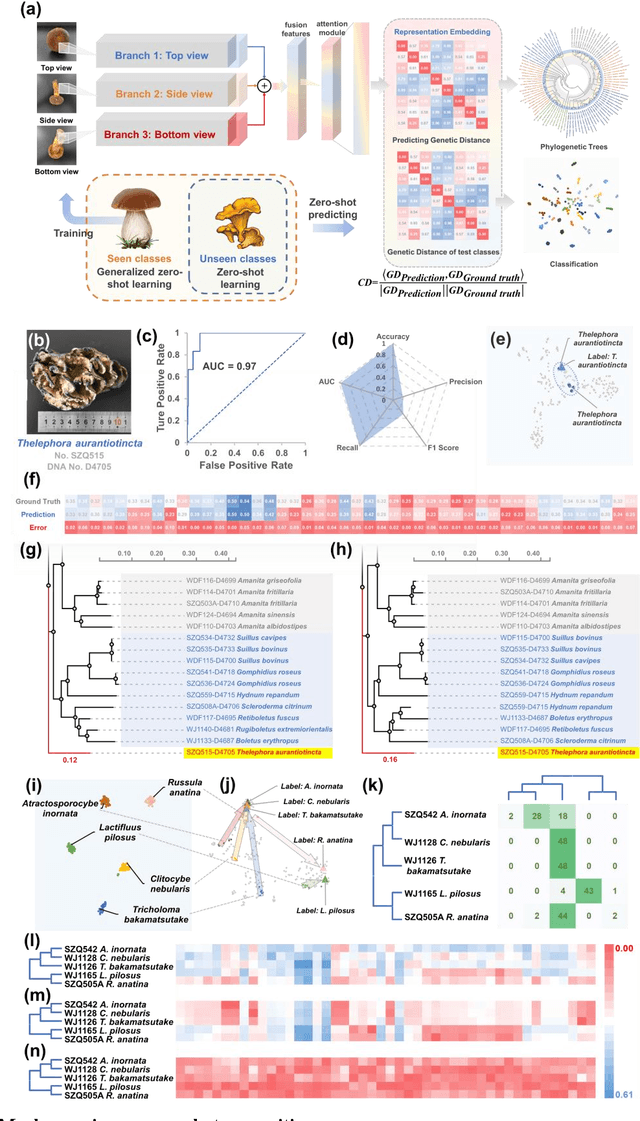
Molecular and morphological characters, as important parts of biological taxonomy, are contradictory but need to be integrated. Organism's image recognition and bioinformatics are emerging and hot problems nowadays but with a gap between them. In this work, a multi-branching recognition framework mediated by genetic information bridges this barrier, which establishes the link between macro-morphology and micro-molecular information of mushrooms. The novel multi-perspective structure is proposed to fuse the feature images from three branching models, which significantly improves the accuracy of recognition by about 10% and up to more than 90%. Further, genetic information is implemented to the mushroom image recognition task by using genetic distance embeddings as the representation space for predicting image distance and species identification. Semantic overfitting of traditional classification tasks and the granularity of fine-grained image recognition are also discussed in depth for the first time. The generalizability of the model was investigated in fine-grained scenarios using zero-shot learning tasks, which could predict the taxonomic and evolutionary information of unseen samples. We presented the first method to map images to DNA, namely used an encoder mapping image to genetic distances, and then decoded DNA through a pre-trained decoder, where the total test accuracy on 37 species for DNA prediction is 87.45%. This study creates a novel recognition framework by systematically studying the mushroom image recognition problem, bridging the gap between macroscopic biological information and microscopic molecular information, which will provide a new reference for intelligent biometrics in the future.
Mushroom image recognition and distance generation based on attention-mechanism model and genetic information
Jun 27, 2022
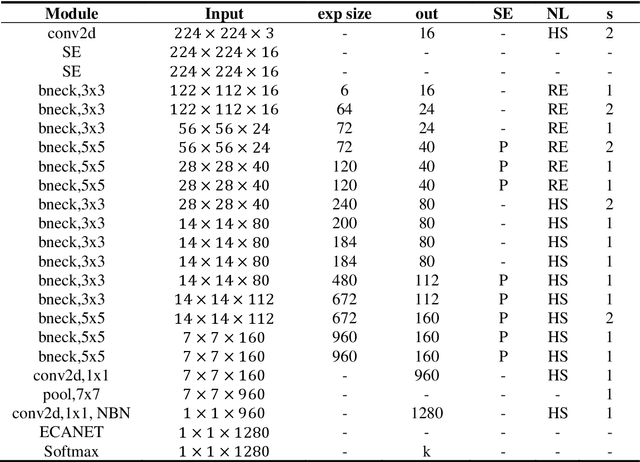

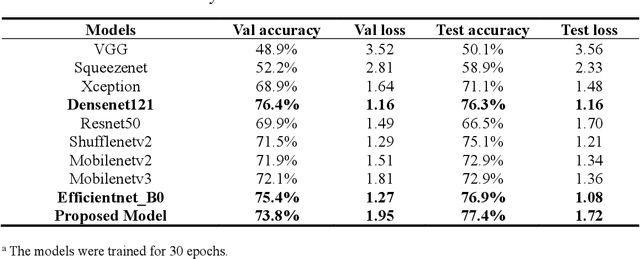
The species identification of Macrofungi, i.e. mushrooms, has always been a challenging task. There are still a large number of poisonous mushrooms that have not been found, which poses a risk to people's life. However, the traditional identification method requires a large number of experts with knowledge in the field of taxonomy for manual identification, it is not only inefficient but also consumes a lot of manpower and capital costs. In this paper, we propose a new model based on attention-mechanism, MushroomNet, which applies the lightweight network MobileNetV3 as the backbone model, combined with the attention structure proposed by us, and has achieved excellent performance in the mushroom recognition task. On the public dataset, the test accuracy of the MushroomNet model has reached 83.9%, and on the local dataset, the test accuracy has reached 77.4%. The proposed attention mechanisms well focused attention on the bodies of mushroom image for mixed channel attention and the attention heat maps visualized by Grad-CAM. Further, in this study, genetic distance was added to the mushroom image recognition task, the genetic distance was used as the representation space, and the genetic distance between each pair of mushroom species in the dataset was used as the embedding of the genetic distance representation space, so as to predict the image distance and species. identify. We found that using the MES activation function can predict the genetic distance of mushrooms very well, but the accuracy is lower than that of SoftMax. The proposed MushroomNet was demonstrated it shows great potential for automatic and online mushroom image and the proposed automatic procedure would assist and be a reference to traditional mushroom classification.