 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025
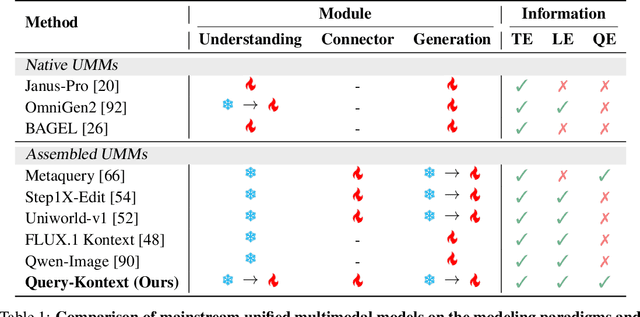
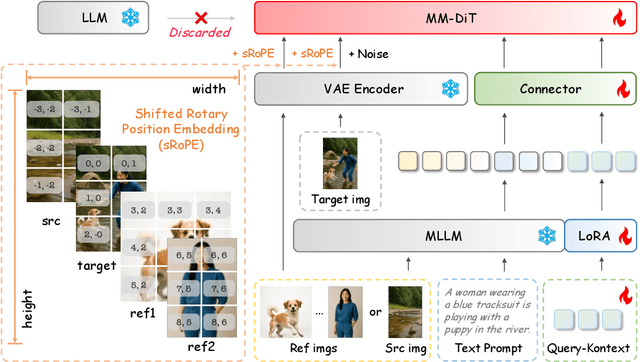
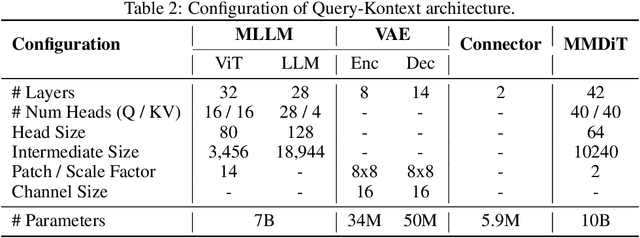
Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
Semi-Supervised Learning for Dose Prediction in Targeted Radionuclide: A Synthetic Data Study
Mar 07, 2025Targeted Radionuclide Therapy (TRT) is a modern strategy in radiation oncology that aims to administer a potent radiation dose specifically to cancer cells using cancer-targeting radiopharmaceuticals. Accurate radiation dose estimation tailored to individual patients is crucial. Deep learning, particularly with pre-therapy imaging, holds promise for personalizing TRT doses. However, current methods require large time series of SPECT imaging, which is hardly achievable in routine clinical practice, and thus raises issues of data availability. Our objective is to develop a semi-supervised learning (SSL) solution to personalize dosimetry using pre-therapy images. The aim is to develop an approach that achieves accurate results when PET/CT images are available, but are associated with only a few post-therapy dosimetry data provided by SPECT images. In this work, we introduce an SSL method using a pseudo-label generation approach for regression tasks inspired by the FixMatch framework. The feasibility of the proposed solution was preliminarily evaluated through an in-silico study using synthetic data and Monte Carlo simulation. Experimental results for organ dose prediction yielded promising outcomes, showing that the use of pseudo-labeled data provides better accuracy compared to using only labeled data.
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
May 08, 2023
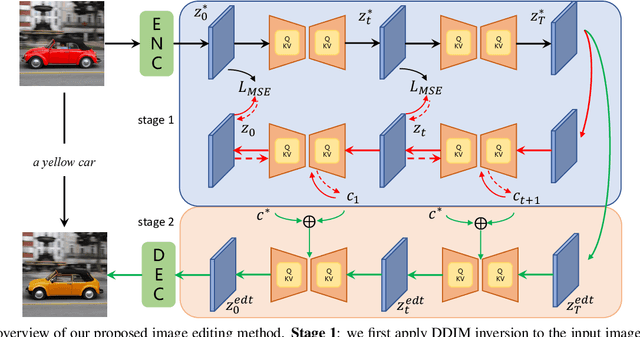
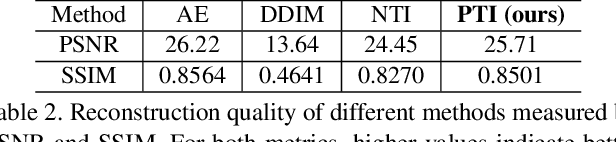
Recently large-scale language-image models (e.g., text-guided diffusion models) have considerably improved the image generation capabilities to generate photorealistic images in various domains. Based on this success, current image editing methods use texts to achieve intuitive and versatile modification of images. To edit a real image using diffusion models, one must first invert the image to a noisy latent from which an edited image is sampled with a target text prompt. However, most methods lack one of the following: user-friendliness (e.g., additional masks or precise descriptions of the input image are required), generalization to larger domains, or high fidelity to the input image. In this paper, we design an accurate and quick inversion technique, Prompt Tuning Inversion, for text-driven image editing. Specifically, our proposed editing method consists of a reconstruction stage and an editing stage. In the first stage, we encode the information of the input image into a learnable conditional embedding via Prompt Tuning Inversion. In the second stage, we apply classifier-free guidance to sample the edited image, where the conditional embedding is calculated by linearly interpolating between the target embedding and the optimized one obtained in the first stage. This technique ensures a superior trade-off between editability and high fidelity to the input image of our method. For example, we can change the color of a specific object while preserving its original shape and background under the guidance of only a target text prompt. Extensive experiments on ImageNet demonstrate the superior editing performance of our method compared to the state-of-the-art baselines.
Rethinking the Number of Shots in Robust Model-Agnostic Meta-Learning
Nov 28, 2022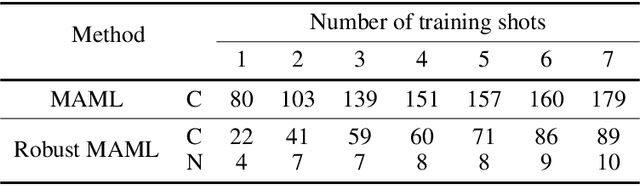
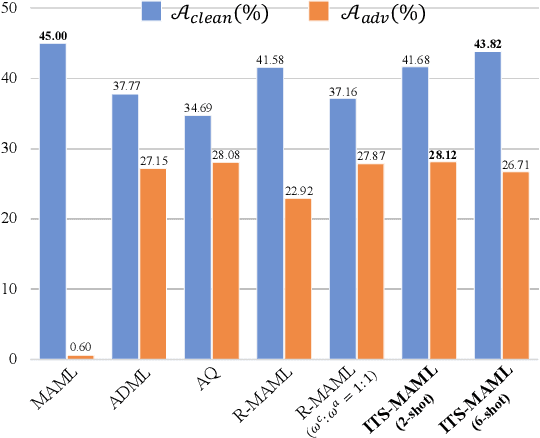

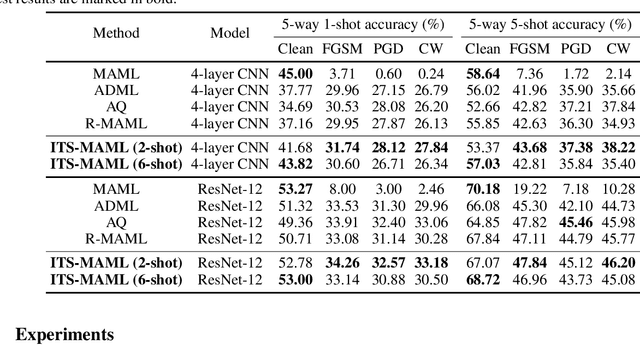
Robust Model-Agnostic Meta-Learning (MAML) is usually adopted to train a meta-model which may fast adapt to novel classes with only a few exemplars and meanwhile remain robust to adversarial attacks. The conventional solution for robust MAML is to introduce robustness-promoting regularization during meta-training stage. With such a regularization, previous robust MAML methods simply follow the typical MAML practice that the number of training shots should match with the number of test shots to achieve an optimal adaptation performance. However, although the robustness can be largely improved, previous methods sacrifice clean accuracy a lot. In this paper, we observe that introducing robustness-promoting regularization into MAML reduces the intrinsic dimension of clean sample features, which results in a lower capacity of clean representations. This may explain why the clean accuracy of previous robust MAML methods drops severely. Based on this observation, we propose a simple strategy, i.e., increasing the number of training shots, to mitigate the loss of intrinsic dimension caused by robustness-promoting regularization. Though simple, our method remarkably improves the clean accuracy of MAML without much loss of robustness, producing a robust yet accurate model. Extensive experiments demonstrate that our method outperforms prior arts in achieving a better trade-off between accuracy and robustness. Besides, we observe that our method is less sensitive to the number of fine-tuning steps during meta-training, which allows for a reduced number of fine-tuning steps to improve training efficiency.
Associative Adversarial Learning Based on Selective Attack
Jan 04, 2022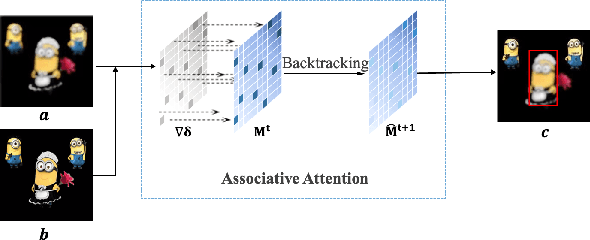
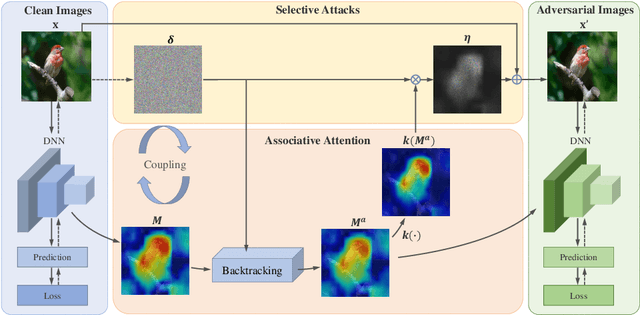
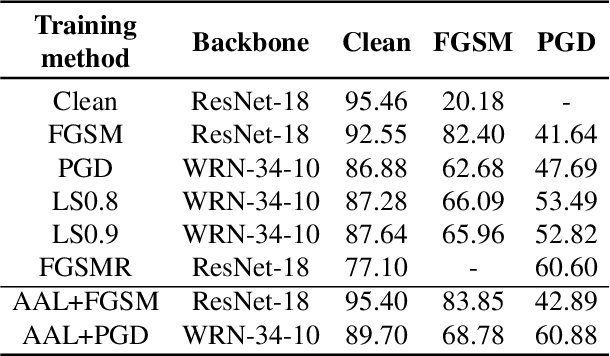
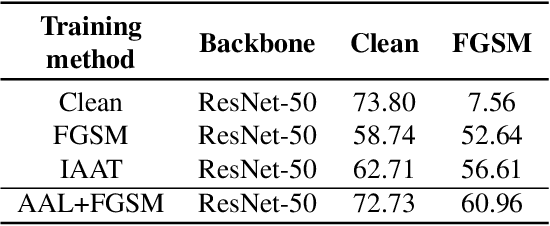
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Anti-Bandit Neural Architecture Search for Model Defense
Aug 05, 2020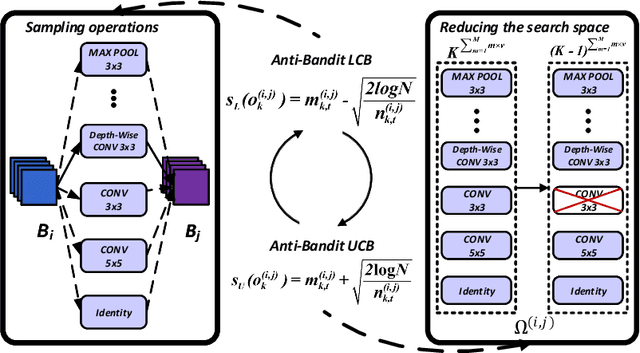

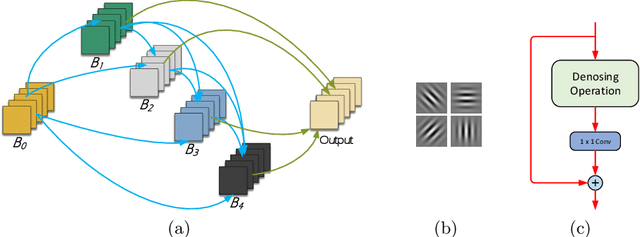
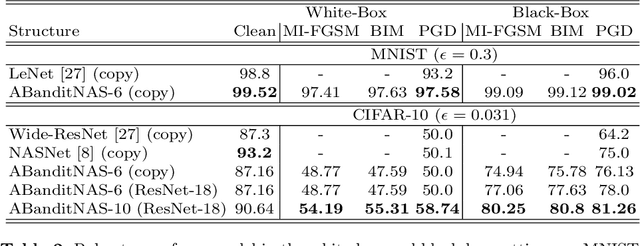
Deep convolutional neural networks (DCNNs) have dominated as the best performers in machine learning, but can be challenged by adversarial attacks. In this paper, we defend against adversarial attacks using neural architecture search (NAS) which is based on a comprehensive search of denoising blocks, weight-free operations, Gabor filters and convolutions. The resulting anti-bandit NAS (ABanditNAS) incorporates a new operation evaluation measure and search process based on the lower and upper confidence bounds (LCB and UCB). Unlike the conventional bandit algorithm using UCB for evaluation only, we use UCB to abandon arms for search efficiency and LCB for a fair competition between arms. Extensive experiments demonstrate that ABanditNAS is faster than other NAS methods, while achieving an $8.73\%$ improvement over prior arts on CIFAR-10 under PGD-$7$.