 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Dimensionless Learning: Geometric Interpretation and the Effect of Noise
Dec 12, 2025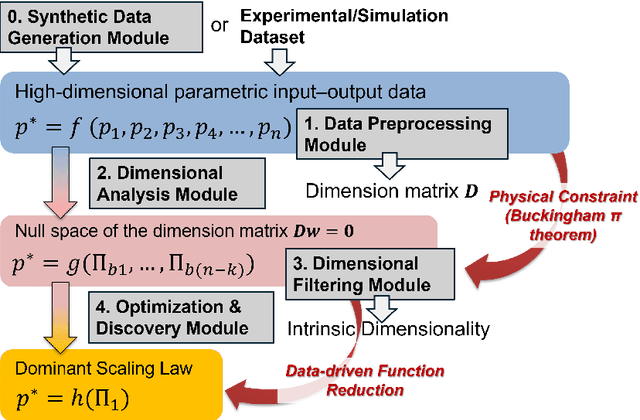
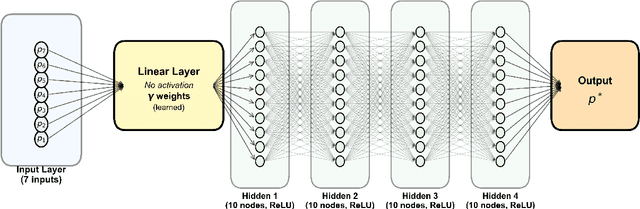
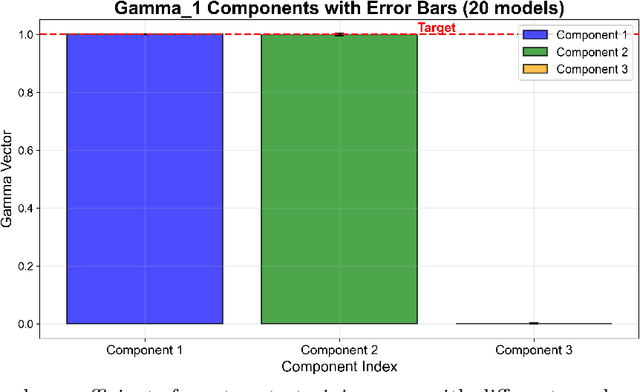
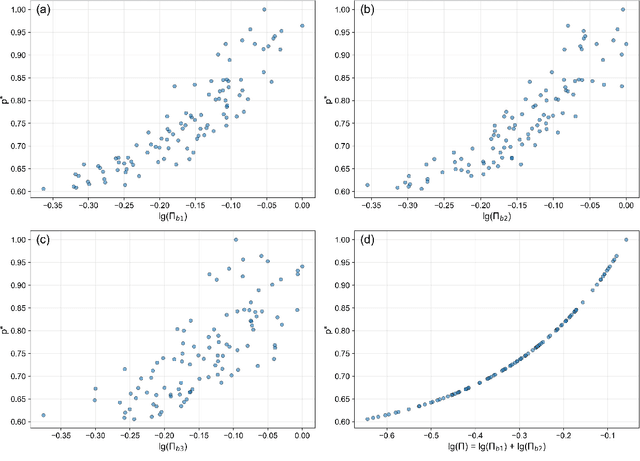
Dimensionless learning is a data-driven framework for discovering dimensionless numbers and scaling laws from experimental measurements. This tutorial introduces the method, explaining how it transforms experimental data into compact physical laws that reveal compact dimensional invariance between variables. The approach combines classical dimensional analysis with modern machine learning techniques. Starting from measurements of physical quantities, the method identifies the fundamental ways to combine variables into dimensionless groups, then uses neural networks to discover which combinations best predict the experimental output. A key innovation is a regularization technique that encourages the learned coefficients to take simple, interpretable values like integers or half-integers, making the discovered laws both accurate and physically meaningful. We systematically investigate how measurement noise and discrete sampling affect the discovery process, demonstrating that the regularization approach provides robustness to experimental uncertainties. The method successfully handles cases with single or multiple dimensionless numbers, revealing how different but equivalent representations can capture the same underlying physics. Despite recent progress, key challenges remain, including managing the computational cost of identifying multiple dimensionless groups, understanding the influence of data characteristics, automating the selection of relevant input variables, and developing user-friendly tools for experimentalists. This tutorial serves as both an educational resource and a practical guide for researchers seeking to apply dimensionless learning to their experimental data.
Engineering software 2.0 by interpolating neural networks: unifying training, solving, and calibration
Apr 16, 2024The evolution of artificial intelligence (AI) and neural network theories has revolutionized the way software is programmed, shifting from a hard-coded series of codes to a vast neural network. However, this transition in engineering software has faced challenges such as data scarcity, multi-modality of data, low model accuracy, and slow inference. Here, we propose a new network based on interpolation theories and tensor decomposition, the interpolating neural network (INN). Instead of interpolating training data, a common notion in computer science, INN interpolates interpolation points in the physical space whose coordinates and values are trainable. It can also extrapolate if the interpolation points reside outside of the range of training data and the interpolation functions have a larger support domain. INN features orders of magnitude fewer trainable parameters, faster training, a smaller memory footprint, and higher model accuracy compared to feed-forward neural networks (FFNN) or physics-informed neural networks (PINN). INN is poised to usher in Engineering Software 2.0, a unified neural network that spans various domains of space, time, parameters, and initial/boundary conditions. This has previously been computationally prohibitive due to the exponentially growing number of trainable parameters, easily exceeding the parameter size of ChatGPT, which is over 1 trillion. INN addresses this challenge by leveraging tensor decomposition and tensor product, with adaptable network architecture.
Smooth and Sparse Latent Dynamics in Operator Learning with Jerk Regularization
Feb 23, 2024



Spatiotemporal modeling is critical for understanding complex systems across various scientific and engineering disciplines, but governing equations are often not fully known or computationally intractable due to inherent system complexity. Data-driven reduced-order models (ROMs) offer a promising approach for fast and accurate spatiotemporal forecasting by computing solutions in a compressed latent space. However, these models often neglect temporal correlations between consecutive snapshots when constructing the latent space, leading to suboptimal compression, jagged latent trajectories, and limited extrapolation ability over time. To address these issues, this paper introduces a continuous operator learning framework that incorporates jerk regularization into the learning of the compressed latent space. This jerk regularization promotes smoothness and sparsity of latent space dynamics, which not only yields enhanced accuracy and convergence speed but also helps identify intrinsic latent space coordinates. Consisting of an implicit neural representation (INR)-based autoencoder and a neural ODE latent dynamics model, the framework allows for inference at any desired spatial or temporal resolution. The effectiveness of this framework is demonstrated through a two-dimensional unsteady flow problem governed by the Navier-Stokes equations, highlighting its potential to expedite high-fidelity simulations in various scientific and engineering applications.
Statistical Parameterized Physics-Based Machine Learning Digital Twin Models for Laser Powder Bed Fusion Process
Nov 14, 2023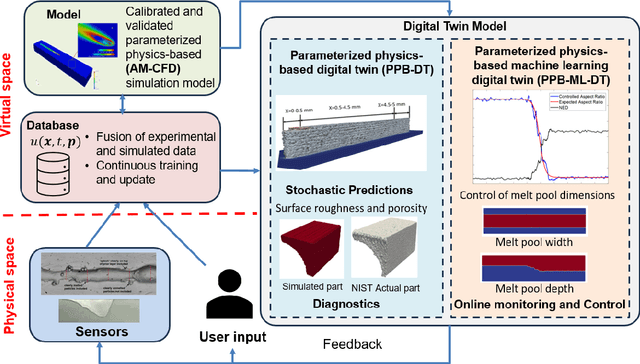
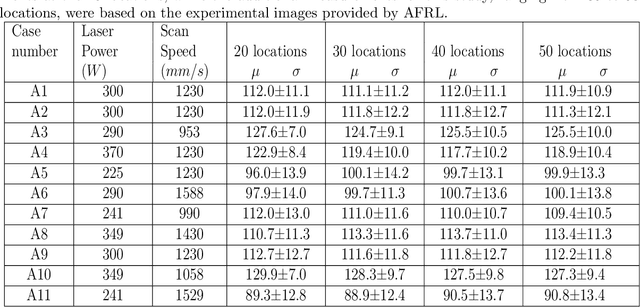
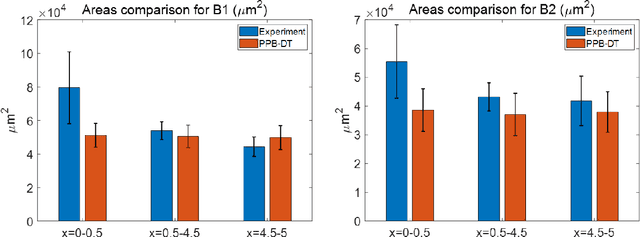
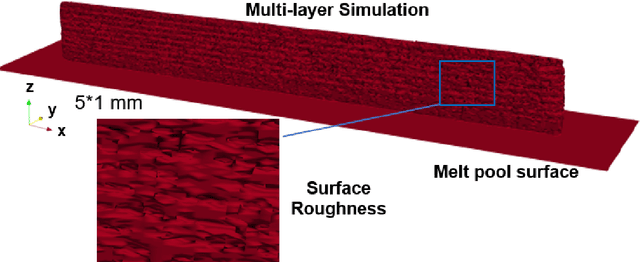
A digital twin (DT) is a virtual representation of physical process, products and/or systems that requires a high-fidelity computational model for continuous update through the integration of sensor data and user input. In the context of laser powder bed fusion (LPBF) additive manufacturing, a digital twin of the manufacturing process can offer predictions for the produced parts, diagnostics for manufacturing defects, as well as control capabilities. This paper introduces a parameterized physics-based digital twin (PPB-DT) for the statistical predictions of LPBF metal additive manufacturing process. We accomplish this by creating a high-fidelity computational model that accurately represents the melt pool phenomena and subsequently calibrating and validating it through controlled experiments. In PPB-DT, a mechanistic reduced-order method-driven stochastic calibration process is introduced, which enables the statistical predictions of the melt pool geometries and the identification of defects such as lack-of-fusion porosity and surface roughness, specifically for diagnostic applications. Leveraging data derived from this physics-based model and experiments, we have trained a machine learning-based digital twin (PPB-ML-DT) model for predicting, monitoring, and controlling melt pool geometries. These proposed digital twin models can be employed for predictions, control, optimization, and quality assurance within the LPBF process, ultimately expediting product development and certification in LPBF-based metal additive manufacturing.
A Two-stage Classification Method for High-dimensional Data and Point Clouds
May 21, 2019
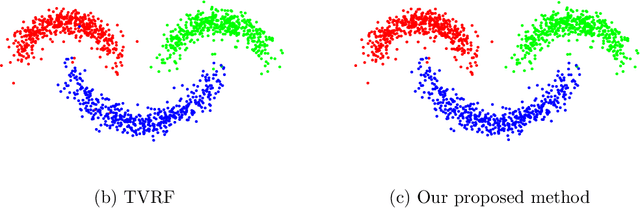
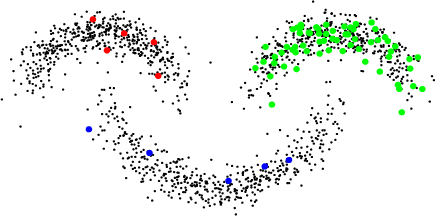

High-dimensional data classification is a fundamental task in machine learning and imaging science. In this paper, we propose a two-stage multiphase semi-supervised classification method for classifying high-dimensional data and unstructured point clouds. To begin with, a fuzzy classification method such as the standard support vector machine is used to generate a warm initialization. We then apply a two-stage approach named SaT (smoothing and thresholding) to improve the classification. In the first stage, an unconstraint convex variational model is implemented to purify and smooth the initialization, followed by the second stage which is to project the smoothed partition obtained at stage one to a binary partition. These two stages can be repeated, with the latest result as a new initialization, to keep improving the classification quality. We show that the convex model of the smoothing stage has a unique solution and can be solved by a specifically designed primal-dual algorithm whose convergence is guaranteed. We test our method and compare it with the state-of-the-art methods on several benchmark data sets. The experimental results demonstrate clearly that our method is superior in both the classification accuracy and computation speed for high-dimensional data and point clouds.