 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Completion with Graph Information: A Provable Nonconvex Optimization Approach
Feb 12, 2025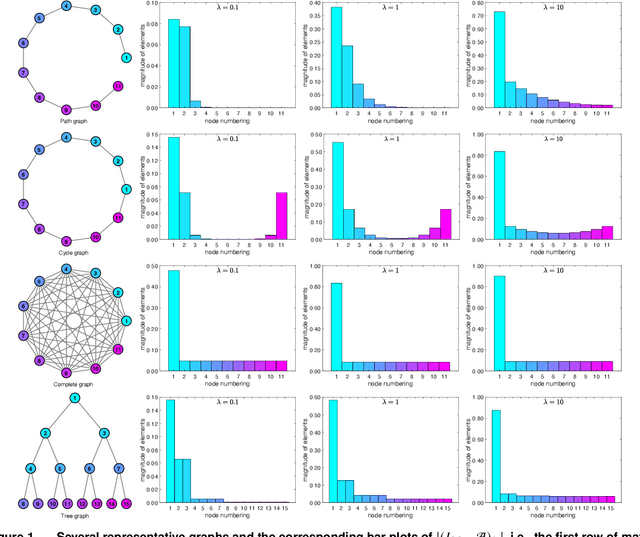
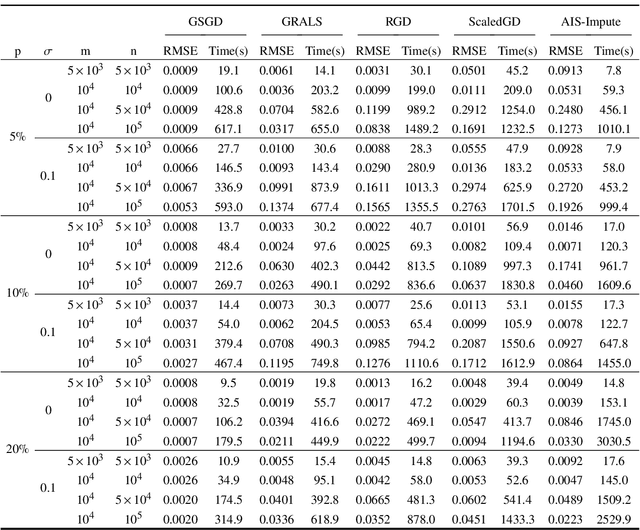
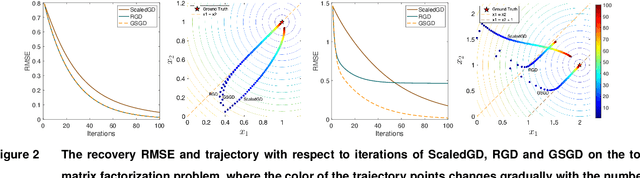

We consider the problem of matrix completion with graphs as side information depicting the interrelations between variables. The key challenge lies in leveraging the similarity structure of the graph to enhance matrix recovery. Existing approaches, primarily based on graph Laplacian regularization, suffer from several limitations: (1) they focus only on the similarity between neighboring variables, while overlooking long-range correlations; (2) they are highly sensitive to false edges in the graphs and (3) they lack theoretical guarantees regarding statistical and computational complexities. To address these issues, we propose in this paper a novel graph regularized matrix completion algorithm called GSGD, based on preconditioned projected gradient descent approach. We demonstrate that GSGD effectively captures the higher-order correlation information behind the graphs, and achieves superior robustness and stability against the false edges. Theoretically, we prove that GSGD achieves linear convergence to the global optimum with near-optimal sample complexity, providing the first theoretical guarantees for both recovery accuracy and efficacy in the perspective of nonconvex optimization. Our numerical experiments on both synthetic and real-world data further validate that GSGD achieves superior recovery accuracy and scalability compared with several popular alternatives.
A Unified Regularization Approach to High-Dimensional Generalized Tensor Bandits
Jan 18, 2025

Modern decision-making scenarios often involve data that is both high-dimensional and rich in higher-order contextual information, where existing bandits algorithms fail to generate effective policies. In response, we propose in this paper a generalized linear tensor bandits algorithm designed to tackle these challenges by incorporating low-dimensional tensor structures, and further derive a unified analytical framework of the proposed algorithm. Specifically, our framework introduces a convex optimization approach with the weakly decomposable regularizers, enabling it to not only achieve better results based on the tensor low-rankness structure assumption but also extend to cases involving other low-dimensional structures such as slice sparsity and low-rankness. The theoretical analysis shows that, compared to existing low-rankness tensor result, our framework not only provides better bounds but also has a broader applicability. Notably, in the special case of degenerating to low-rank matrices, our bounds still offer advantages in certain scenarios.
Efficient Generalized Low-Rank Tensor Contextual Bandits
Nov 09, 2023

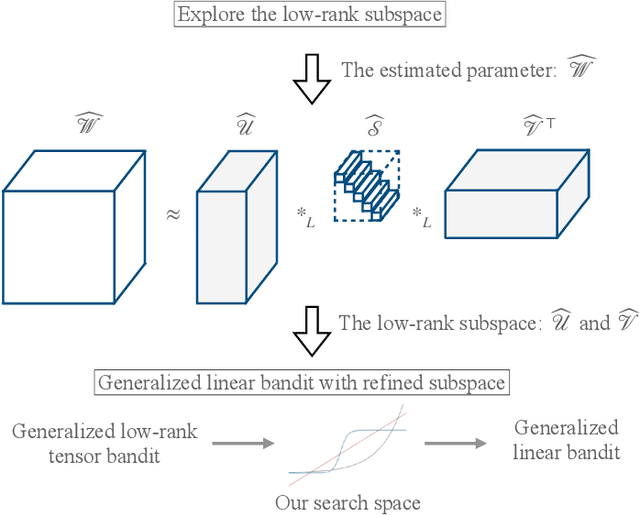
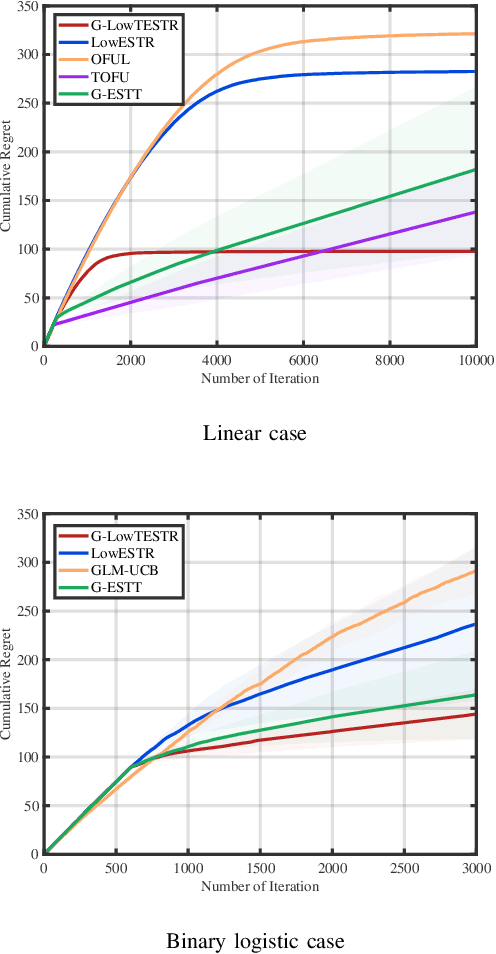
In this paper, we aim to build a novel bandits algorithm that is capable of fully harnessing the power of multi-dimensional data and the inherent non-linearity of reward functions to provide high-usable and accountable decision-making services. To this end, we introduce a generalized low-rank tensor contextual bandits model in which an action is formed from three feature vectors, and thus can be represented by a tensor. In this formulation, the reward is determined through a generalized linear function applied to the inner product of the action's feature tensor and a fixed but unknown parameter tensor with a low tubal rank. To effectively achieve the trade-off between exploration and exploitation, we introduce a novel algorithm called "Generalized Low-Rank Tensor Exploration Subspace then Refine" (G-LowTESTR). This algorithm first collects raw data to explore the intrinsic low-rank tensor subspace information embedded in the decision-making scenario, and then converts the original problem into an almost lower-dimensional generalized linear contextual bandits problem. Rigorous theoretical analysis shows that the regret bound of G-LowTESTR is superior to those in vectorization and matricization cases. We conduct a series of simulations and real data experiments to further highlight the effectiveness of G-LowTESTR, leveraging its ability to capitalize on the low-rank tensor structure for enhanced learning.