 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration
Feb 02, 2026Training instability remains a critical challenge in large language model (LLM) pretraining, often manifesting as sudden gradient explosions that waste significant computational resources. We study training failures in a 5M-parameter NanoGPT model scaled via $μ$P, identifying two key phenomena preceding collapse: (1) rapid decline in weight matrix stable rank (ratio of squared Frobenius norm to squared spectral norm), and (2) increasing alignment between adjacent layer Jacobians. We prove theoretically that these two conditions jointly cause exponential gradient norm growth with network depth. To break this instability mechanism, we propose MSign, a new optimizer that periodically applies matrix sign operations to restore stable rank. Experiments on models from 5M to 3B parameters demonstrate that MSign effectively prevents training failures with a computational overhead of less than 7.0%.
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025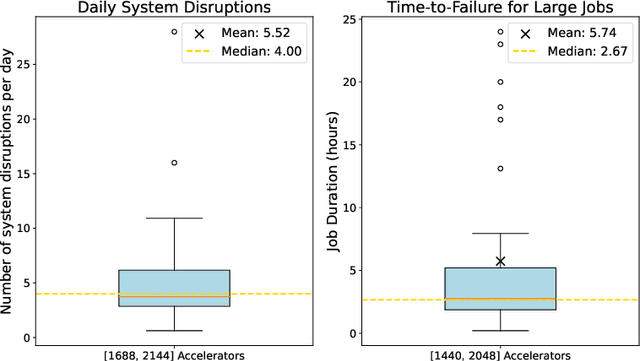

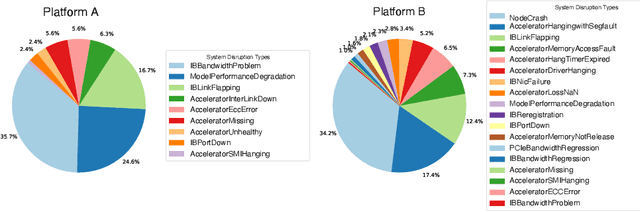

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Unifying back-propagation and forward-forward algorithms through model predictive control
Sep 29, 2024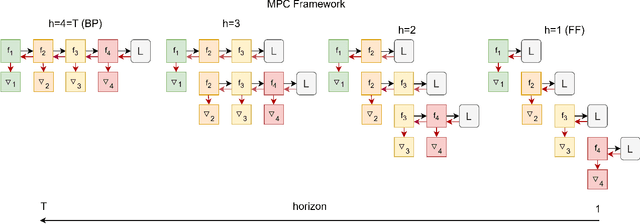
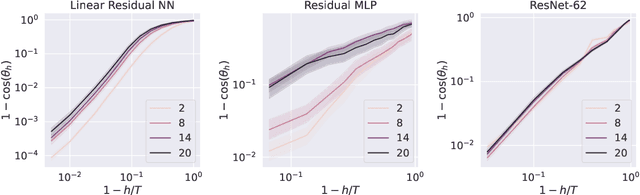
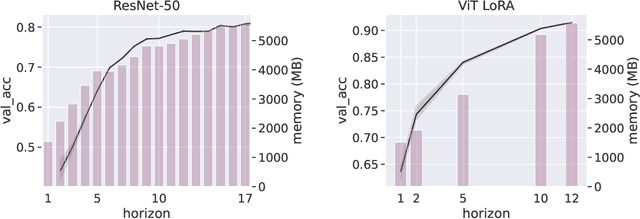
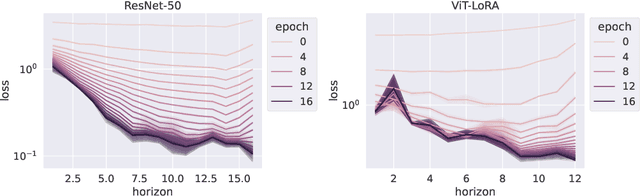
We introduce a Model Predictive Control (MPC) framework for training deep neural networks, systematically unifying the Back-Propagation (BP) and Forward-Forward (FF) algorithms. At the same time, it gives rise to a range of intermediate training algorithms with varying look-forward horizons, leading to a performance-efficiency trade-off. We perform a precise analysis of this trade-off on a deep linear network, where the qualitative conclusions carry over to general networks. Based on our analysis, we propose a principled method to choose the optimization horizon based on given objectives and model specifications. Numerical results on various models and tasks demonstrate the versatility of our method.