 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Human-Centric and Robot-Centric Sampling for Robot Deep Learning from Demonstrations
Paper and Code

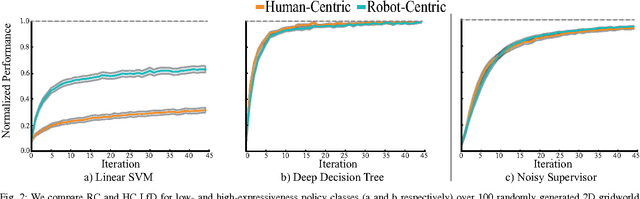
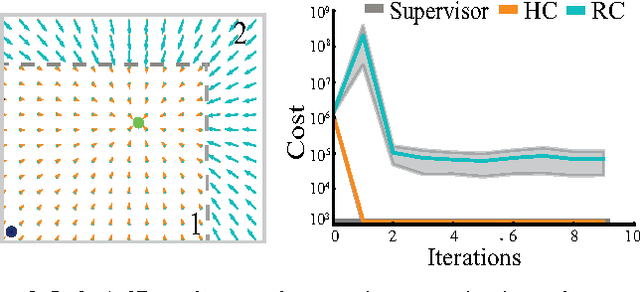
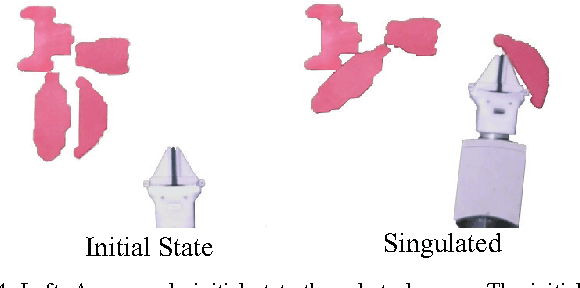
Motivated by recent advances in Deep Learning for robot control, this paper considers two learning algorithms in terms of how they acquire demonstrations. "Human-Centric" (HC) sampling is the standard supervised learning algorithm, where a human supervisor demonstrates the task by teleoperating the robot to provide trajectories consisting of state-control pairs. "Robot-Centric" (RC) sampling is an increasingly popular alternative used in algorithms such as DAgger, where a human supervisor observes the robot executing a learned policy and provides corrective control labels for each state visited. RC sampling can be challenging for human supervisors and prone to mislabeling. RC sampling can also induce error in policy performance because it repeatedly visits areas of the state space that are harder to learn. Although policies learned with RC sampling can be superior to HC sampling for standard learning models such as linear SVMs, policies learned with HC sampling may be comparable with highly-expressive learning models such as deep learning and hyper-parametric decision trees, which have little model error. We compare HC and RC using a grid world and a physical robot singulation task, where in the latter the input is a binary image of a connected set of objects on a planar worksurface and the policy generates a motion of the gripper to separate one object from the rest. We observe in simulation that for linear SVMs, policies learned with RC outperformed those learned with HC but that with deep models this advantage disappears. We also find that with RC, the corrective control labels provided by humans can be highly inconsistent. We prove there exists a class of examples where in the limit, HC is guaranteed to converge to an optimal policy while RC may fail to converge.