 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Occluders with Compositional Convolutional Networks
Paper and Code
Nov 18, 2019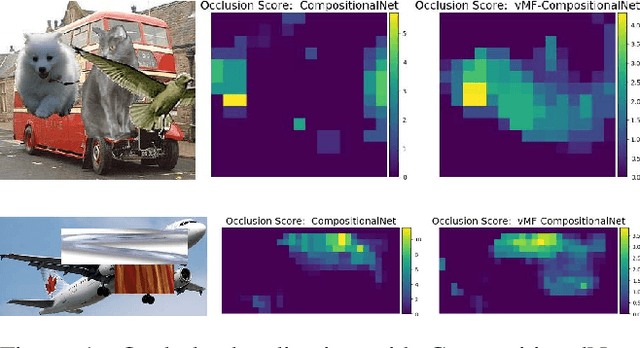


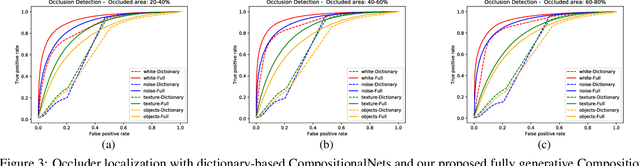
Compositional convolutional networks are generative compositional models of neural network features, that achieve state of the art results when classifying partially occluded objects, even when they have not been exposed to occluded objects during training. In this work, we study the performance of CompositionalNets at localizing occluders in images. We show that the original model is not able to localize occluders well. We propose to overcome this limitation by modeling the feature activations as a mixture of von-Mises-Fisher distributions, which also allows for an end-to-end training of CompositionalNets. Our experimental results demonstrate that the proposed extensions increase the model's performance at localizing occluders as well as at classifying partially occluded objects.