 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Part Discovery via Feature Alignment
Paper and Code
Dec 01, 2020

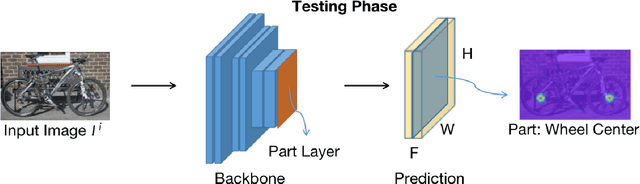

Understanding objects in terms of their individual parts is important, because it enables a precise understanding of the objects' geometrical structure, and enhances object recognition when the object is seen in a novel pose or under partial occlusion. However, the manual annotation of parts in large scale datasets is time consuming and expensive. In this paper, we aim at discovering object parts in an unsupervised manner, i.e., without ground-truth part or keypoint annotations. Our approach builds on the intuition that objects of the same class in a similar pose should have their parts aligned at similar spatial locations. We exploit the property that neural network features are largely invariant to nuisance variables and the main remaining source of variations between images of the same object category is the object pose. Specifically, given a training image, we find a set of similar images that show instances of the same object category in the same pose, through an affine alignment of their corresponding feature maps. The average of the aligned feature maps serves as pseudo ground-truth annotation for a supervised training of the deep network backbone. During inference, part detection is simple and fast, without any extra modules or overheads other than a feed-forward neural network. Our experiments on several datasets from different domains verify the effectiveness of the proposed method. For example, we achieve 37.8 mAP on VehiclePart, which is at least 4.2 better than previous methods.