 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven, ML-assisted Approaches to Problem Well-Posedness
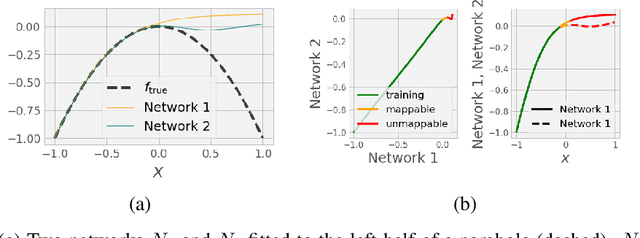
Mar 25, 2025Classically, to solve differential equation problems, it is necessary to specify sufficient initial and/or boundary conditions so as to allow the existence of a unique solution. Well-posedness of differential equation problems thus involves studying the existence and uniqueness of solutions, and their dependence to such pre-specified conditions. However, in part due to mathematical necessity, these conditions are usually specified "to arbitrary precision" only on (appropriate portions of) the boundary of the space-time domain. This does not mirror how data acquisition is performed in realistic situations, where one may observe entire "patches" of solution data at arbitrary space-time locations; alternatively one might have access to more than one solutions stemming from the same differential operator. In our short work, we demonstrate how standard tools from machine and manifold learning can be used to infer, in a data driven manner, certain well-posedness features of differential equation problems, for initial/boundary condition combinations under which rigorous existence/uniqueness theorems are not known. Our study naturally combines a data assimilation perspective with an operator-learning one.
Implementation and (Inverse Modified) Error Analysis for implicitly-templated ODE-nets
Apr 10, 2023We focus on learning unknown dynamics from data using ODE-nets templated on implicit numerical initial value problem solvers. First, we perform Inverse Modified error analysis of the ODE-nets using unrolled implicit schemes for ease of interpretation. It is shown that training an ODE-net using an unrolled implicit scheme returns a close approximation of an Inverse Modified Differential Equation (IMDE). In addition, we establish a theoretical basis for hyper-parameter selection when training such ODE-nets, whereas current strategies usually treat numerical integration of ODE-nets as a black box. We thus formulate an adaptive algorithm which monitors the level of error and adapts the number of (unrolled) implicit solution iterations during the training process, so that the error of the unrolled approximation is less than the current learning loss. This helps accelerate training, while maintaining accuracy. Several numerical experiments are performed to demonstrate the advantages of the proposed algorithm compared to nonadaptive unrollings, and validate the theoretical analysis. We also note that this approach naturally allows for incorporating partially known physical terms in the equations, giving rise to what is termed ``gray box" identification.
Learning effective stochastic differential equations from microscopic simulations: combining stochastic numerics and deep learning
Jun 10, 2021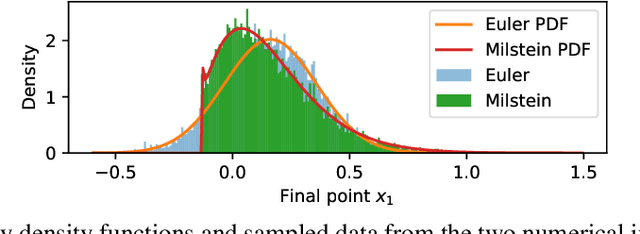


We identify effective stochastic differential equations (SDE) for coarse observables of fine-grained particle- or agent-based simulations; these SDE then provide coarse surrogate models of the fine scale dynamics. We approximate the drift and diffusivity functions in these effective SDE through neural networks, which can be thought of as effective stochastic ResNets. The loss function is inspired by, and embodies, the structure of established stochastic numerical integrators (here, Euler-Maruyama and Milstein); our approximations can thus benefit from error analysis of these underlying numerical schemes. They also lend themselves naturally to "physics-informed" gray-box identification when approximate coarse models, such as mean field equations, are available. Our approach does not require long trajectories, works on scattered snapshot data, and is designed to naturally handle different time steps per snapshot. We consider both the case where the coarse collective observables are known in advance, as well as the case where they must be found in a data-driven manner.
Initializing LSTM internal states via manifold learning
May 12, 2021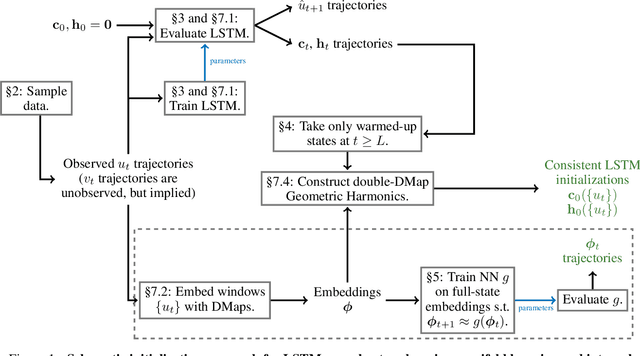
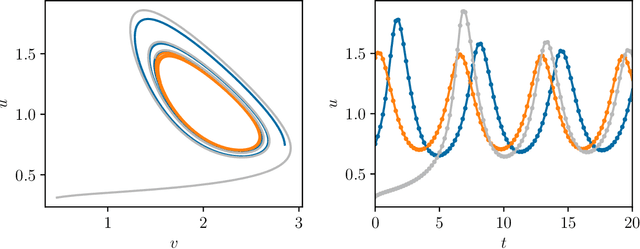
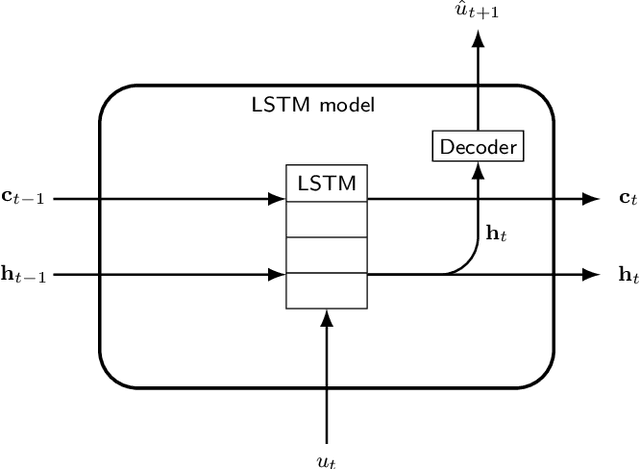
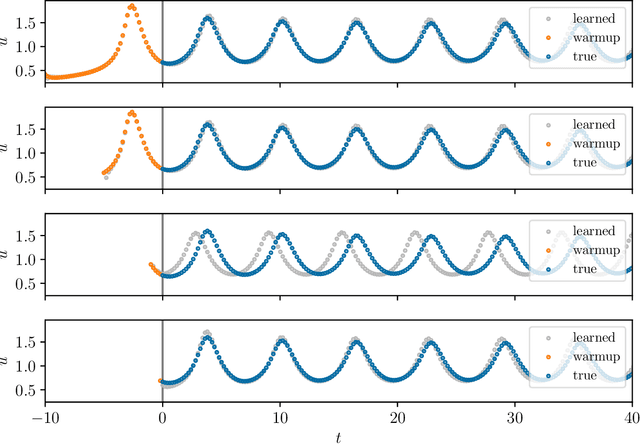
We present an approach, based on learning an intrinsic data manifold, for the initialization of the internal state values of LSTM recurrent neural networks, ensuring consistency with the initial observed input data. Exploiting the generalized synchronization concept, we argue that the converged, "mature" internal states constitute a function on this learned manifold. The dimension of this manifold then dictates the length of observed input time series data required for consistent initialization. We illustrate our approach through a partially observed chemical model system, where initializing the internal LSTM states in this fashion yields visibly improved performance. Finally, we show that learning this data manifold enables the transformation of partially observed dynamics into fully observed ones, facilitating alternative identification paths for nonlinear dynamical systems.
Personalized Algorithm Generation: A Case Study in Meta-Learning ODE Integrators
May 04, 2021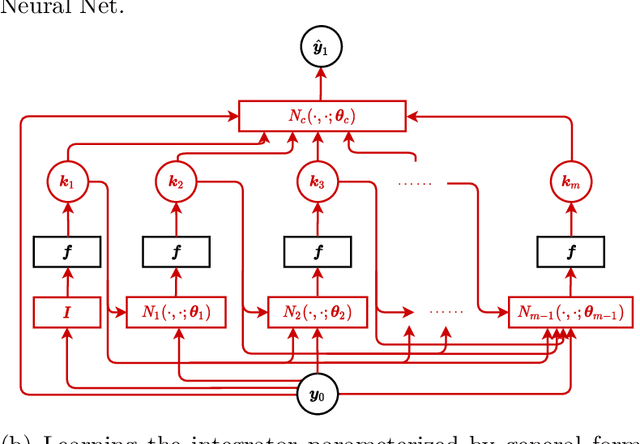
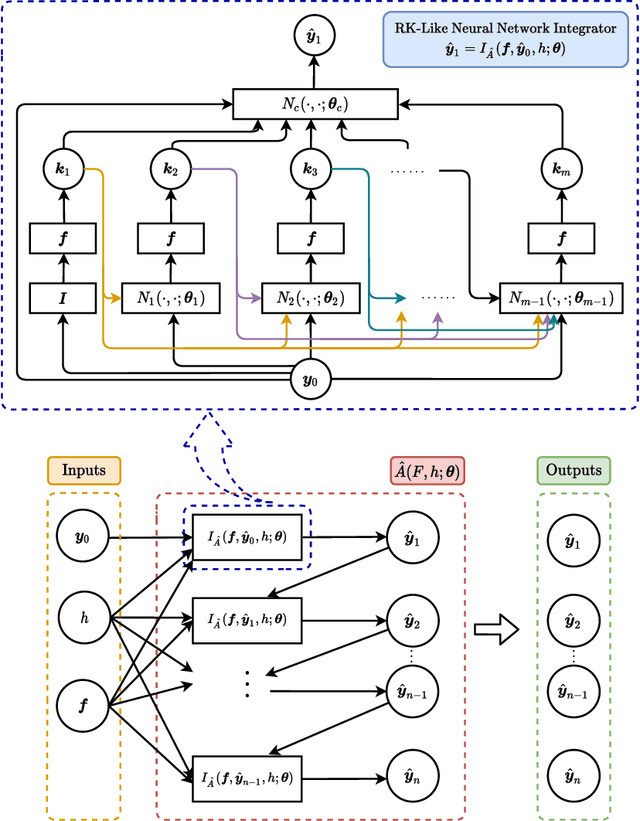
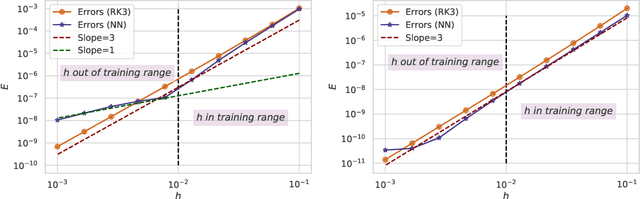
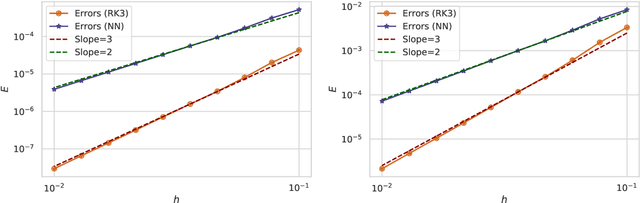
We study the meta-learning of numerical algorithms for scientific computing, which combines the mathematically driven, handcrafted design of general algorithm structure with a data-driven adaptation to specific classes of tasks. This represents a departure from the classical approaches in numerical analysis, which typically do not feature such learning-based adaptations. As a case study, we develop a machine learning approach that automatically learns effective solvers for initial value problems in the form of ordinary differential equations (ODEs), based on the Runge-Kutta (RK) integrator architecture. By combining neural network approximations and meta-learning, we show that we can obtain high-order integrators for targeted families of differential equations without the need for computing integrator coefficients by hand. Moreover, we demonstrate that in certain cases we can obtain superior performance to classical RK methods. This can be attributed to certain properties of the ODE families being identified and exploited by the approach. Overall, this work demonstrates an effective, learning-based approach to the design of algorithms for the numerical solution of differential equations, an approach that can be readily extended to other numerical tasks.
Learning emergent PDEs in a learned emergent space
Dec 23, 2020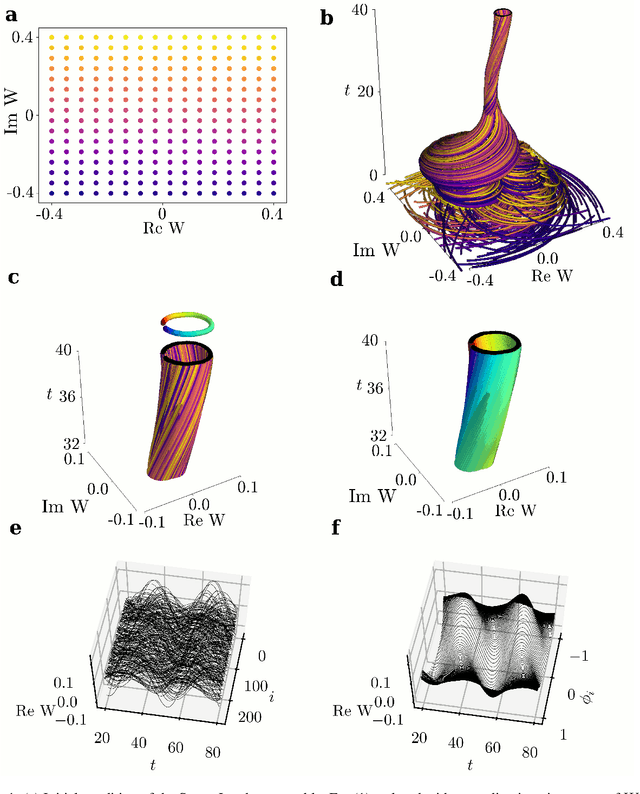
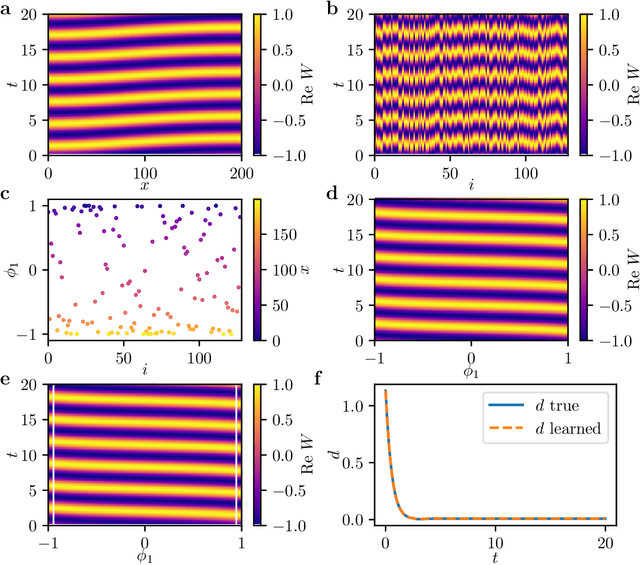
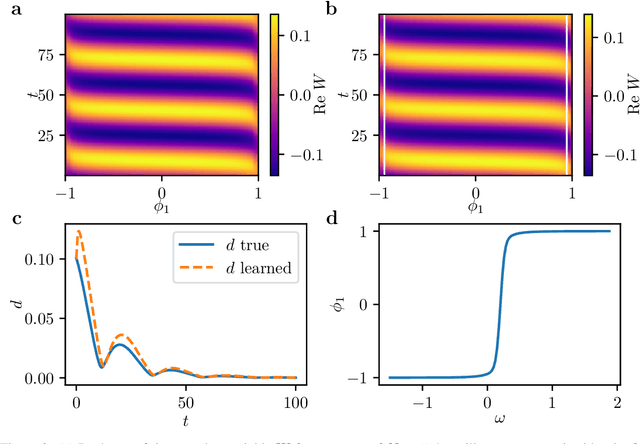
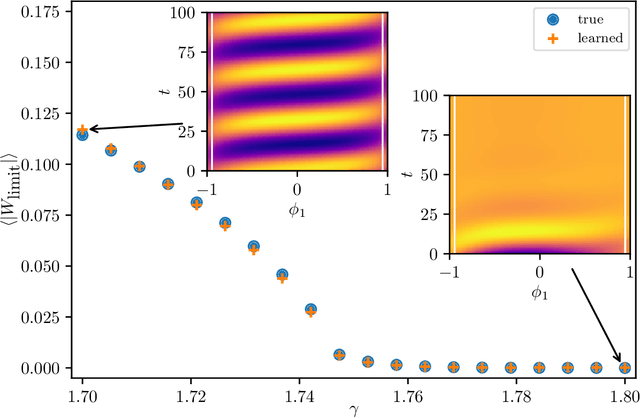
We extract data-driven, intrinsic spatial coordinates from observations of the dynamics of large systems of coupled heterogeneous agents. These coordinates then serve as an emergent space in which to learn predictive models in the form of partial differential equations (PDEs) for the collective description of the coupled-agent system. They play the role of the independent spatial variables in this PDE (as opposed to the dependent, possibly also data-driven, state variables). This leads to an alternative description of the dynamics, local in these emergent coordinates, thus facilitating an alternative modeling path for complex coupled-agent systems. We illustrate this approach on a system where each agent is a limit cycle oscillator (a so-called Stuart-Landau oscillator); the agents are heterogeneous (they each have a different intrinsic frequency $\omega$) and are coupled through the ensemble average of their respective variables. After fast initial transients, we show that the collective dynamics on a slow manifold can be approximated through a learned model based on local "spatial" partial derivatives in the emergent coordinates. The model is then used for prediction in time, as well as to capture collective bifurcations when system parameters vary. The proposed approach thus integrates the automatic, data-driven extraction of emergent space coordinates parametrizing the agent dynamics, with machine-learning assisted identification of an "emergent PDE" description of the dynamics in this parametrization.
Coarse-grained and emergent distributed parameter systems from data
Nov 17, 2020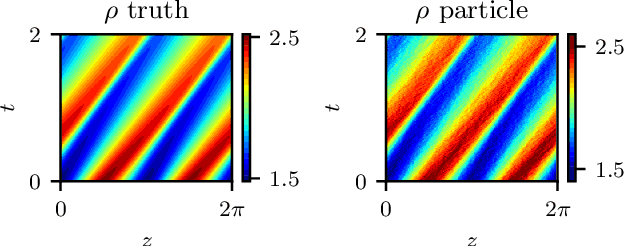
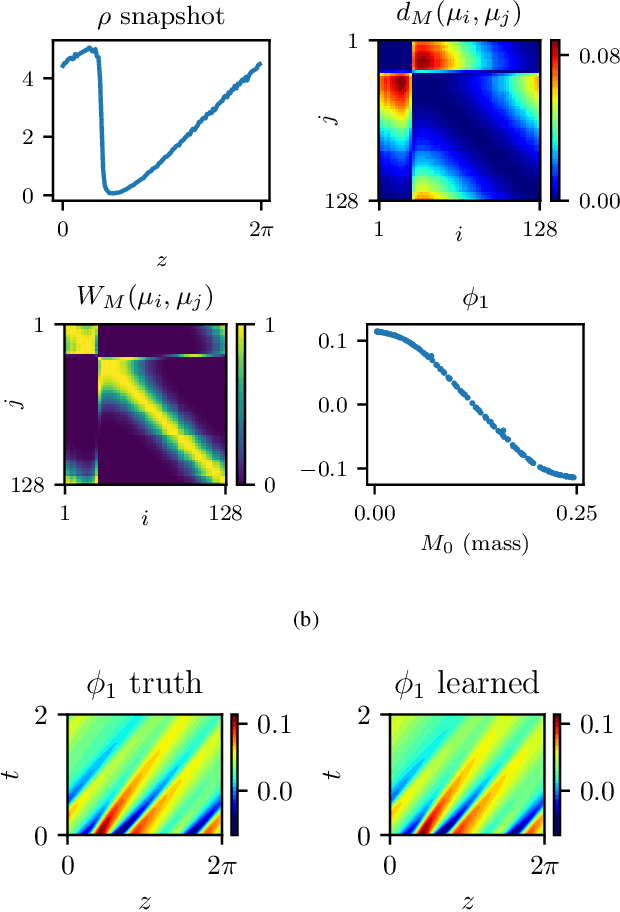
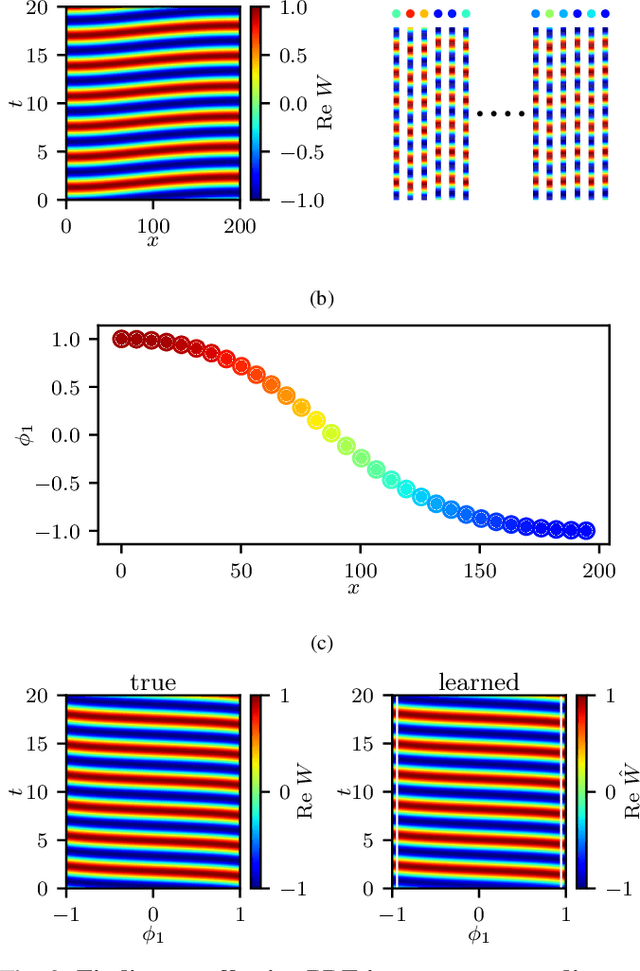
We explore the derivation of distributed parameter system evolution laws (and in particular, partial differential operators and associated partial differential equations, PDEs) from spatiotemporal data. This is, of course, a classical identification problem; our focus here is on the use of manifold learning techniques (and, in particular, variations of Diffusion Maps) in conjunction with neural network learning algorithms that allow us to attempt this task when the dependent variables, and even the independent variables of the PDE are not known a priori and must be themselves derived from the data. The similarity measure used in Diffusion Maps for dependent coarse variable detection involves distances between local particle distribution observations; for independent variable detection we use distances between local short-time dynamics. We demonstrate each approach through an illustrative established PDE example. Such variable-free, emergent space identification algorithms connect naturally with equation-free multiscale computation tools.
Transformations between deep neural networks
Jul 10, 2020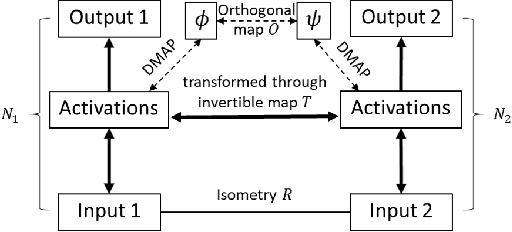
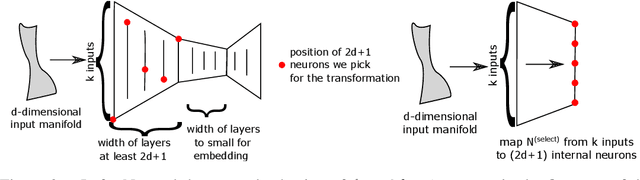
We propose to test, and when possible establish, an equivalence between two different artificial neural networks by attempting to construct a data-driven transformation between them, using manifold-learning techniques. In particular, we employ diffusion maps with a Mahalanobis-like metric. If the construction succeeds, the two networks can be thought of as belonging to the same equivalence class. We first discuss transformation functions between only the outputs of the two networks; we then also consider transformations that take into account outputs (activations) of a number of internal neurons from each network. In general, Whitney's theorem dictates the number of measurements from one of the networks required to reconstruct each and every feature of the second network. The construction of the transformation function relies on a consistent, intrinsic representation of the network input space. We illustrate our algorithm by matching neural network pairs trained to learn (a) observations of scalar functions; (b) observations of two-dimensional vector fields; and (c) representations of images of a moving three-dimensional object (a rotating horse). The construction of such equivalence classes across different network instantiations clearly relates to transfer learning. We also expect that it will be valuable in establishing equivalence between different Machine Learning-based models of the same phenomenon observed through different instruments and by different research groups.
LOCA: LOcal Conformal Autoencoder for standardized data coordinates
Apr 15, 2020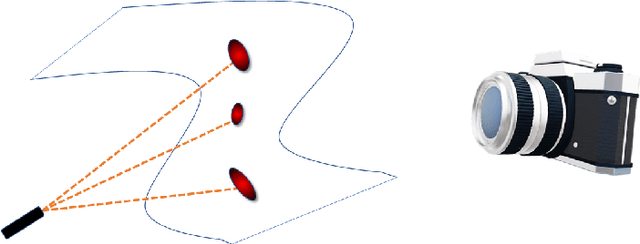
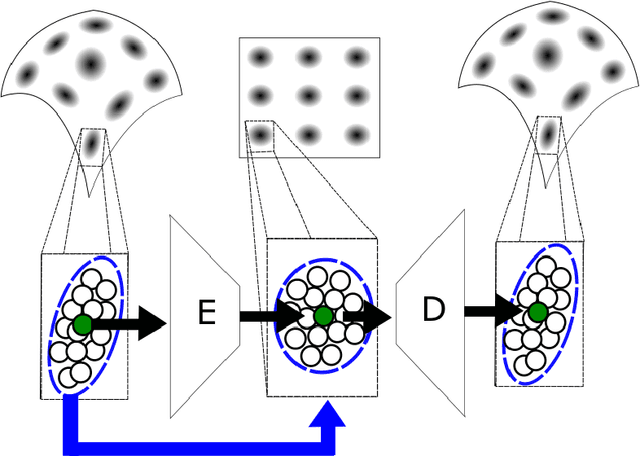
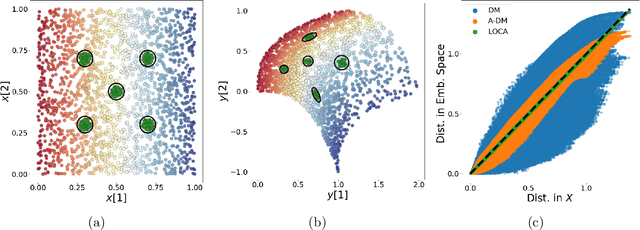
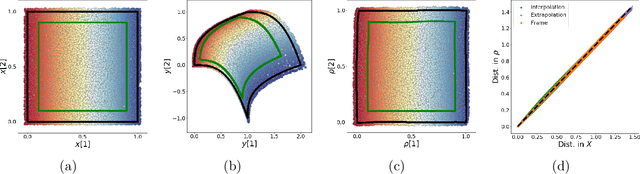
We propose a deep-learning based method for obtaining standardized data coordinates from scientific measurements.Data observations are modeled as samples from an unknown, non-linear deformation of an underlying Riemannian manifold, which is parametrized by a few normalized latent variables. By leveraging a repeated measurement sampling strategy, we present a method for learning an embedding in $\mathbb{R}^d$ that is isometric to the latent variables of the manifold. These data coordinates, being invariant under smooth changes of variables, enable matching between different instrumental observations of the same phenomenon. Our embedding is obtained using a LOcal Conformal Autoencoder (LOCA), an algorithm that constructs an embedding to rectify deformations by using a local z-scoring procedure while preserving relevant geometric information. We demonstrate the isometric embedding properties of LOCA on various model settings and observe that it exhibits promising interpolation and extrapolation capabilities. Finally, we apply LOCA to single-site Wi-Fi localization data, and to $3$-dimensional curved surface estimation based on a $2$-dimensional projection.