 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Hype: Benchmarking LLM-Evolved Heuristics for Bin Packing
Paper and Code
Jan 20, 2025
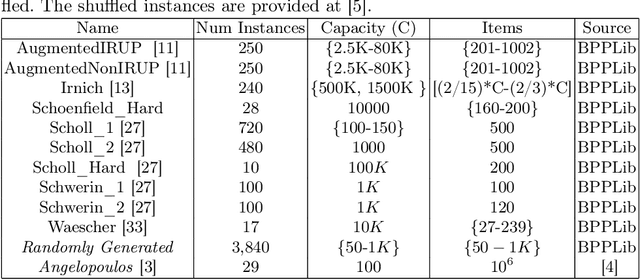
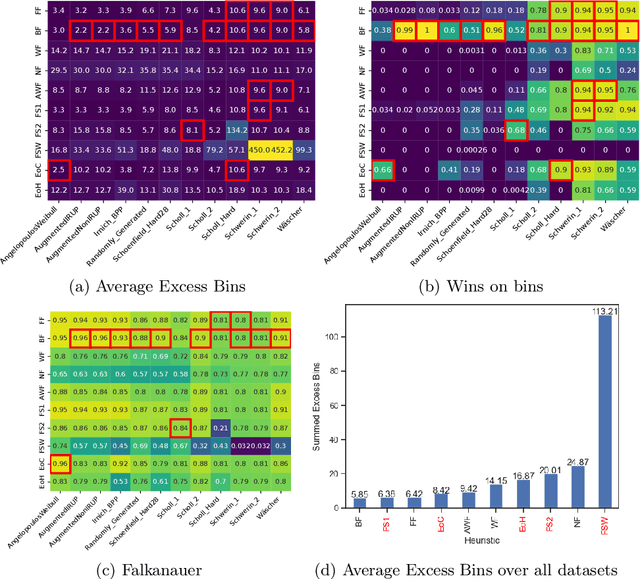
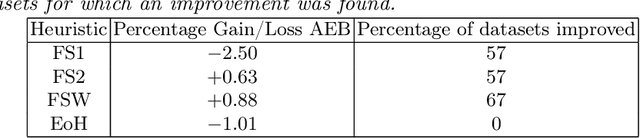
Coupling Large Language Models (LLMs) with Evolutionary Algorithms has recently shown significant promise as a technique to design new heuristics that outperform existing methods, particularly in the field of combinatorial optimisation. An escalating arms race is both rapidly producing new heuristics and improving the efficiency of the processes evolving them. However, driven by the desire to quickly demonstrate the superiority of new approaches, evaluation of the new heuristics produced for a specific domain is often cursory: testing on very few datasets in which instances all belong to a specific class from the domain, and on few instances per class. Taking bin-packing as an example, to the best of our knowledge we conduct the first rigorous benchmarking study of new LLM-generated heuristics, comparing them to well-known existing heuristics across a large suite of benchmark instances using three performance metrics. For each heuristic, we then evolve new instances won by the heuristic and perform an instance space analysis to understand where in the feature space each heuristic performs well. We show that most of the LLM heuristics do not generalise well when evaluated across a broad range of benchmarks in contrast to existing simple heuristics, and suggest that any gains from generating very specialist heuristics that only work in small areas of the instance space need to be weighed carefully against the considerable cost of generating these heuristics.