 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Evaluating Online Anomaly Detection Approaches for Discrete Multivariate Time Series
Nov 21, 2024
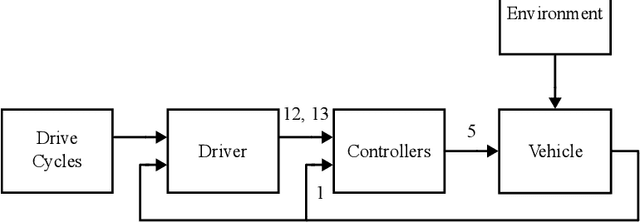
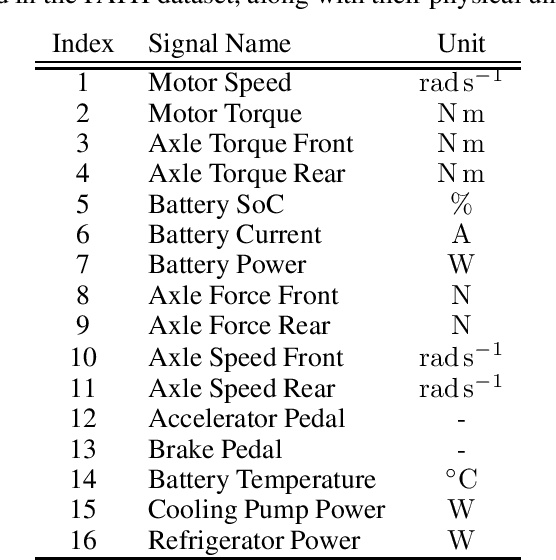
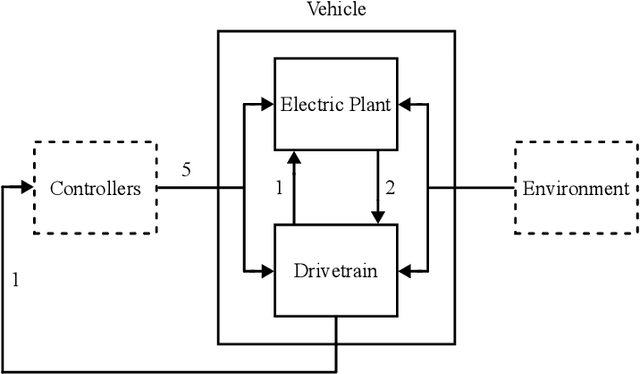
Benchmarking anomaly detection approaches for multivariate time series is challenging due to the lack of high-quality datasets. Current publicly available datasets are too small, not diverse and feature trivial anomalies, which hinders measurable progress in this research area. We propose a solution: a diverse, extensive, and non-trivial dataset generated via state-of-the-art simulation tools that reflects realistic behaviour of an automotive powertrain, including its multivariate, dynamic and variable-state properties. To cater for both unsupervised and semi-supervised anomaly detection settings, as well as time series generation and forecasting, we make different versions of the dataset available, where training and test subsets are offered in contaminated and clean versions, depending on the task. We also provide baseline results from a small selection of approaches based on deterministic and variational autoencoders, as well as a non-parametric approach. As expected, the baseline experimentation shows that the approaches trained on the semi-supervised version of the dataset outperform their unsupervised counterparts, highlighting a need for approaches more robust to contaminated training data.
Online Model-based Anomaly Detection in Multivariate Time Series: Taxonomy, Survey, Research Challenges and Future Directions
Aug 07, 2024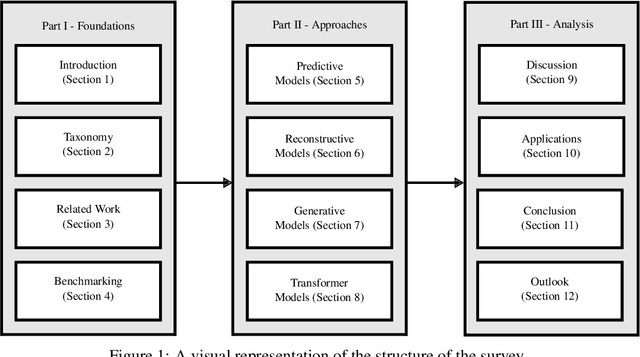

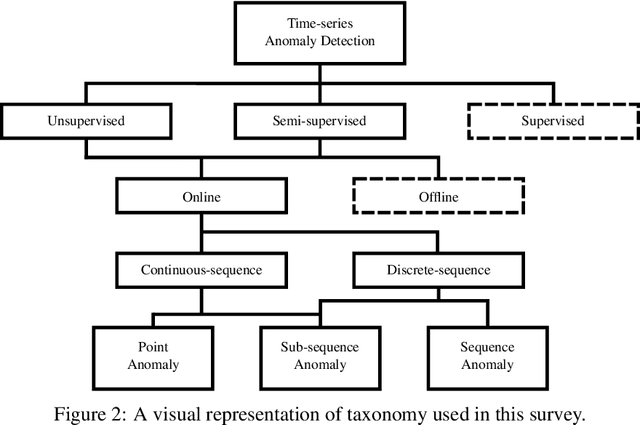
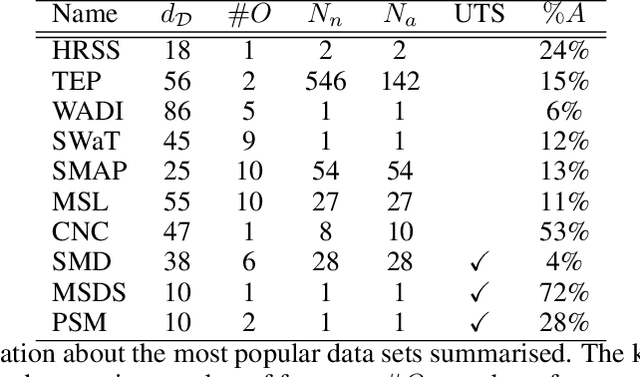
Time-series anomaly detection plays an important role in engineering processes, like development, manufacturing and other operations involving dynamic systems. These processes can greatly benefit from advances in the field, as state-of-the-art approaches may aid in cases involving, for example, highly dimensional data. To provide the reader with understanding of the terminology, this survey introduces a novel taxonomy where a distinction between online and offline, and training and inference is made. Additionally, it presents the most popular data sets and evaluation metrics used in the literature, as well as a detailed analysis. Furthermore, this survey provides an extensive overview of the state-of-the-art model-based online semi- and unsupervised anomaly detection approaches for multivariate time-series data, categorising them into different model families and other properties. The biggest research challenge revolves around benchmarking, as currently there is no reliable way to compare different approaches against one another. This problem is two-fold: on the one hand, public data sets suffers from at least one fundamental flaw, while on the other hand, there is a lack of intuitive and representative evaluation metrics in the field. Moreover, the way most publications choose a detection threshold disregards real-world conditions, which hinders the application in the real world. To allow for tangible advances in the field, these issues must be addressed in future work.
TeVAE: A Variational Autoencoder Approach for Discrete Online Anomaly Detection in Variable-state Multivariate Time-series Data
Jul 09, 2024
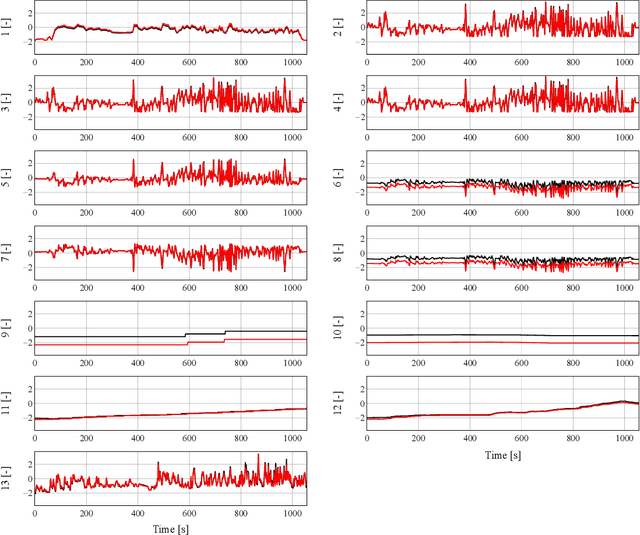
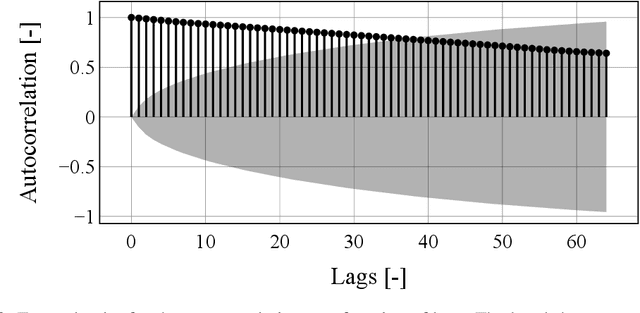
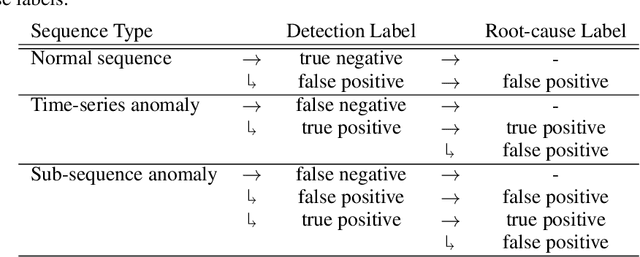
As attention to recorded data grows in the realm of automotive testing and manual evaluation reaches its limits, there is a growing need for automatic online anomaly detection. This real-world data is complex in many ways and requires the modelling of testee behaviour. To address this, we propose a temporal variational autoencoder (TeVAE) that can detect anomalies with minimal false positives when trained on unlabelled data. Our approach also avoids the bypass phenomenon and introduces a new method to remap individual windows to a continuous time series. Furthermore, we propose metrics to evaluate the detection delay and root-cause capability of our approach and present results from experiments on a real-world industrial data set. When properly configured, TeVAE flags anomalies only 6% of the time wrongly and detects 65% of anomalies present. It also has the potential to perform well with a smaller training and validation subset but requires a more sophisticated threshold estimation method.
MA-VAE: Multi-head Attention-based Variational Autoencoder Approach for Anomaly Detection in Multivariate Time-series Applied to Automotive Endurance Powertrain Testing
Sep 05, 2023



A clear need for automatic anomaly detection applied to automotive testing has emerged as more and more attention is paid to the data recorded and manual evaluation by humans reaches its capacity. Such real-world data is massive, diverse, multivariate and temporal in nature, therefore requiring modelling of the testee behaviour. We propose a variational autoencoder with multi-head attention (MA-VAE), which, when trained on unlabelled data, not only provides very few false positives but also manages to detect the majority of the anomalies presented. In addition to that, the approach offers a novel way to avoid the bypass phenomenon, an undesirable behaviour investigated in literature. Lastly, the approach also introduces a new method to remap individual windows to a continuous time series. The results are presented in the context of a real-world industrial data set and several experiments are undertaken to further investigate certain aspects of the proposed model. When configured properly, it is 9% of the time wrong when an anomaly is flagged and discovers 67% of the anomalies present. Also, MA-VAE has the potential to perform well with only a fraction of the training and validation subset, however, to extract it, a more sophisticated threshold estimation method is required.