 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Evaluating Online Anomaly Detection Approaches for Discrete Multivariate Time Series
Paper and Code
Nov 21, 2024
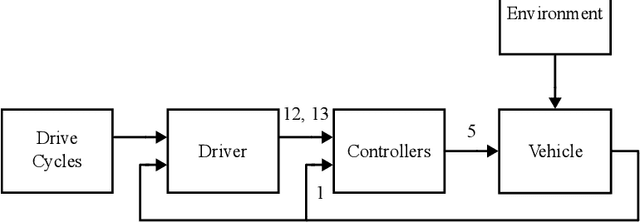
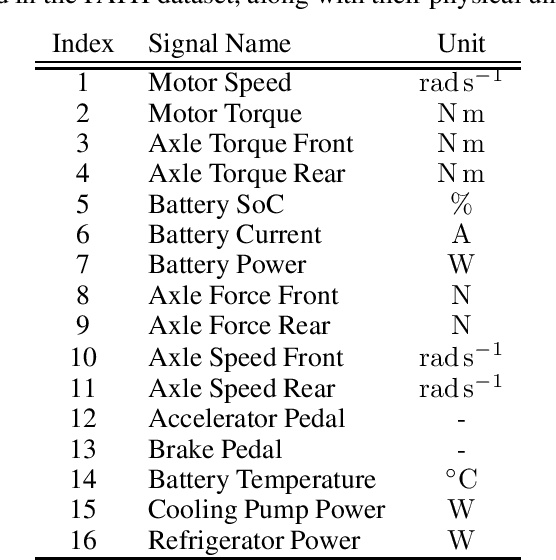
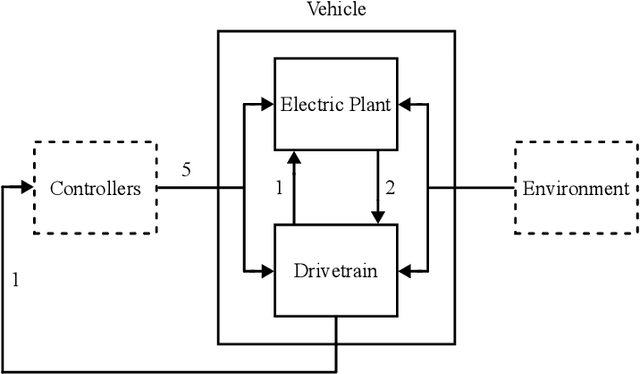
Benchmarking anomaly detection approaches for multivariate time series is challenging due to the lack of high-quality datasets. Current publicly available datasets are too small, not diverse and feature trivial anomalies, which hinders measurable progress in this research area. We propose a solution: a diverse, extensive, and non-trivial dataset generated via state-of-the-art simulation tools that reflects realistic behaviour of an automotive powertrain, including its multivariate, dynamic and variable-state properties. To cater for both unsupervised and semi-supervised anomaly detection settings, as well as time series generation and forecasting, we make different versions of the dataset available, where training and test subsets are offered in contaminated and clean versions, depending on the task. We also provide baseline results from a small selection of approaches based on deterministic and variational autoencoders, as well as a non-parametric approach. As expected, the baseline experimentation shows that the approaches trained on the semi-supervised version of the dataset outperform their unsupervised counterparts, highlighting a need for approaches more robust to contaminated training data.