 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Model-based Anomaly Detection in Multivariate Time Series: Taxonomy, Survey, Research Challenges and Future Directions
Paper and Code
Aug 07, 2024

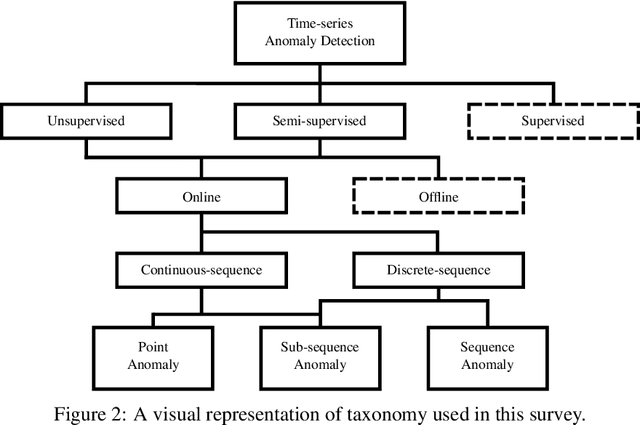
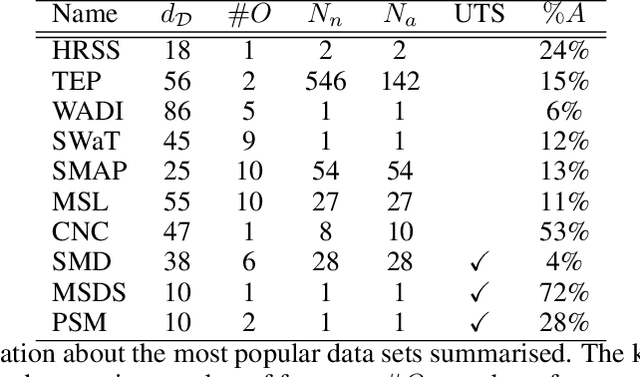
Time-series anomaly detection plays an important role in engineering processes, like development, manufacturing and other operations involving dynamic systems. These processes can greatly benefit from advances in the field, as state-of-the-art approaches may aid in cases involving, for example, highly dimensional data. To provide the reader with understanding of the terminology, this survey introduces a novel taxonomy where a distinction between online and offline, and training and inference is made. Additionally, it presents the most popular data sets and evaluation metrics used in the literature, as well as a detailed analysis. Furthermore, this survey provides an extensive overview of the state-of-the-art model-based online semi- and unsupervised anomaly detection approaches for multivariate time-series data, categorising them into different model families and other properties. The biggest research challenge revolves around benchmarking, as currently there is no reliable way to compare different approaches against one another. This problem is two-fold: on the one hand, public data sets suffers from at least one fundamental flaw, while on the other hand, there is a lack of intuitive and representative evaluation metrics in the field. Moreover, the way most publications choose a detection threshold disregards real-world conditions, which hinders the application in the real world. To allow for tangible advances in the field, these issues must be addressed in future work.