 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Evolution Graphs: Understanding Large Language Model Driven Design of Algorithms
Paper and Code
Mar 20, 2025
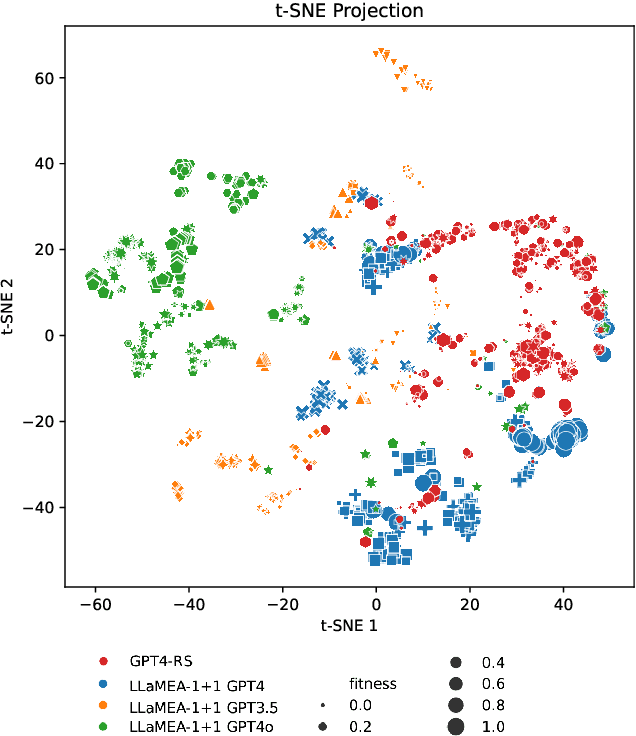
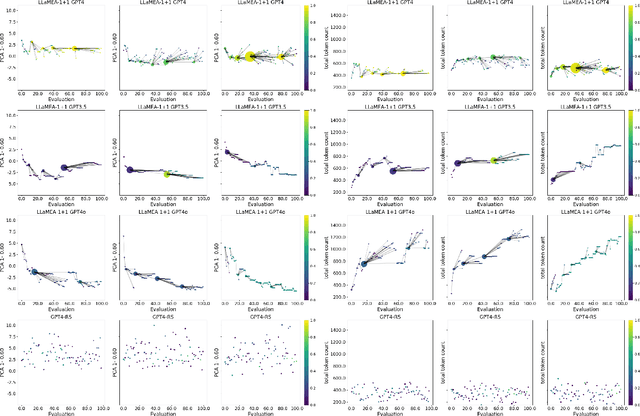

Large Language Models (LLMs) have demonstrated great promise in generating code, especially when used inside an evolutionary computation framework to iteratively optimize the generated algorithms. However, in some cases they fail to generate competitive algorithms or the code optimization stalls, and we are left with no recourse because of a lack of understanding of the generation process and generated codes. We present a novel approach to mitigate this problem by enabling users to analyze the generated codes inside the evolutionary process and how they evolve over repeated prompting of the LLM. We show results for three benchmark problem classes and demonstrate novel insights. In particular, LLMs tend to generate more complex code with repeated prompting, but additional complexity can hurt algorithmic performance in some cases. Different LLMs have different coding ``styles'' and generated code tends to be dissimilar to other LLMs. These two findings suggest that using different LLMs inside the code evolution frameworks might produce higher performing code than using only one LLM.