 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel up: Learning Pulmonary Embolism Segmentation from Image Level Annotation through Model Explainability
Dec 10, 2024



Pulmonary Embolisms (PE) are a leading cause of cardiovascular death. Computed tomographic pulmonary angiography (CTPA) stands as the gold standard for diagnosing pulmonary embolisms (PE) and there has been a lot of interest in developing AI-based models for assisting in PE diagnosis. Performance of these algorithms has been hindered by the scarcity of annotated data, especially those with fine-grained delineation of the thromboembolic burden. In this paper we attempt to address this issue by introducing a weakly supervised learning pipeline, that leverages model explainability to generate fine-grained (pixel level) masks for embolisms starting from more coarse-grained (binary, image level) PE annotations. Furthermore, we show that training models using the automatically generated pixel annotations yields good PE localization performance. We demonstrate the effectiveness of our pipeline on the large-scale, multi-center RSPECT augmented dataset for PE detection and localization.
Anatomically aware dual-hop learning for pulmonary embolism detection in CT pulmonary angiograms
Mar 30, 2023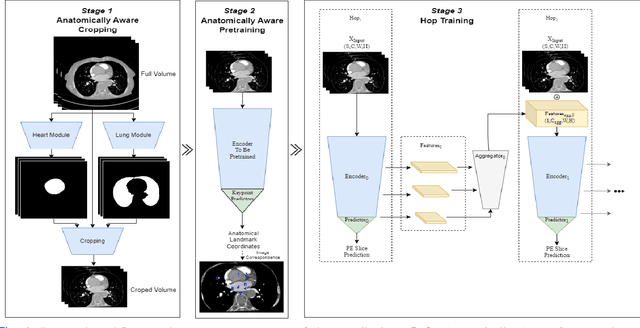
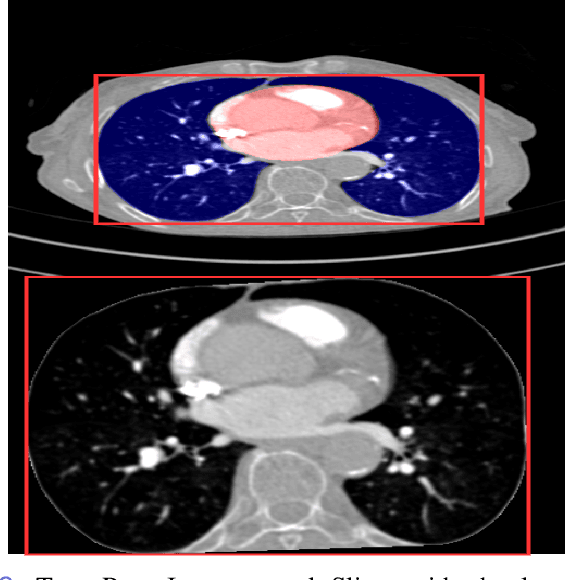
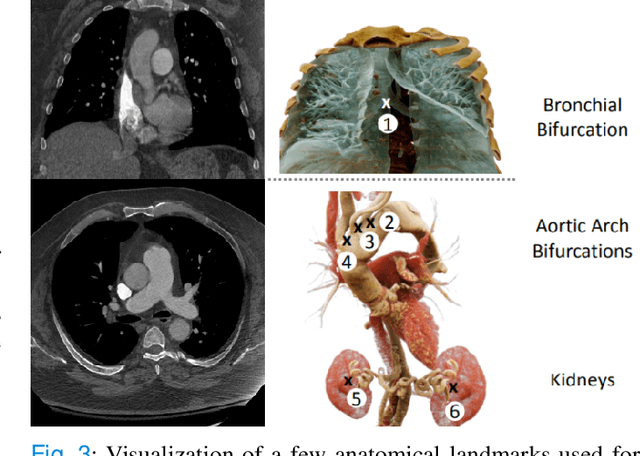
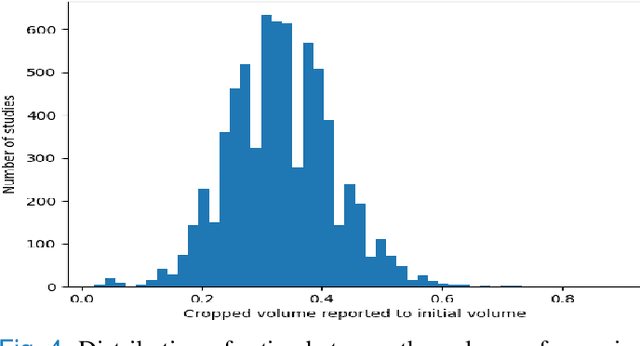
Pulmonary Embolisms (PE) represent a leading cause of cardiovascular death. While medical imaging, through computed tomographic pulmonary angiography (CTPA), represents the gold standard for PE diagnosis, it is still susceptible to misdiagnosis or significant diagnosis delays, which may be fatal for critical cases. Despite the recently demonstrated power of deep learning to bring a significant boost in performance in a wide range of medical imaging tasks, there are still very few published researches on automatic pulmonary embolism detection. Herein we introduce a deep learning based approach, which efficiently combines computer vision and deep neural networks for pulmonary embolism detection in CTPA. Our method features novel improvements along three orthogonal axes: 1) automatic detection of anatomical structures; 2) anatomical aware pretraining, and 3) a dual-hop deep neural net for PE detection. We obtain state-of-the-art results on the publicly available multicenter large-scale RSNA dataset.
In Search of Life: Learning from Synthetic Data to Detect Vital Signs in Videos
Apr 23, 2020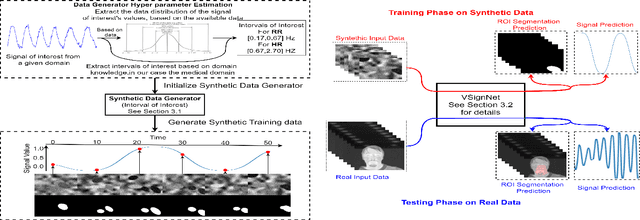
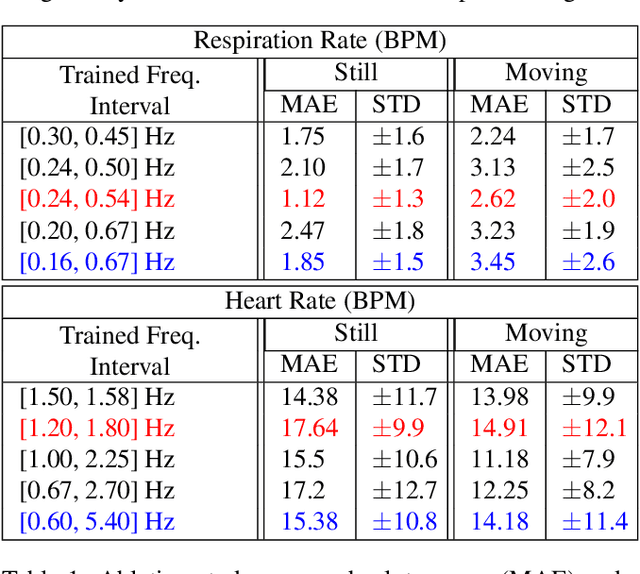
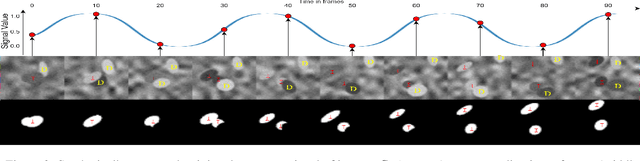
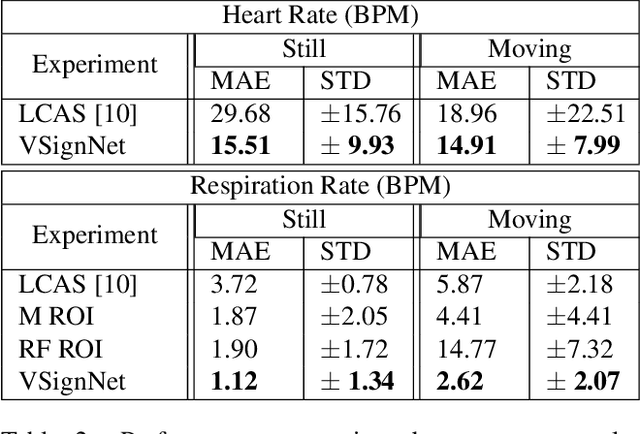
Automatically detecting vital signs in videos, such as the estimation of heart and respiration rates, is a challenging research problem in computer vision with important applications in the medical field. One of the key difficulties in tackling this task is the lack of sufficient supervised training data, which severely limits the use of powerful deep neural networks. In this paper we address this limitation through a novel deep learning approach, in which a recurrent deep neural network is trained to detect vital signs in the infrared thermal domain from purely synthetic data. What is most surprising is that our novel method for synthetic training data generation is general, relatively simple and uses almost no prior medical domain knowledge. Moreover, our system, which is trained in a purely automatic manner and needs no human annotation, also learns to predict the respiration or heart intensity signal for each moment in time and to detect the region of interest that is most relevant for the given task, e.g. the nose area in the case of respiration. We test the effectiveness of our proposed system on the recent LCAS dataset and obtain state-of-the-art results.