 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTmiX: Vision Transformer Explainability Augmented by Mixed Visualization Methods
Dec 18, 2024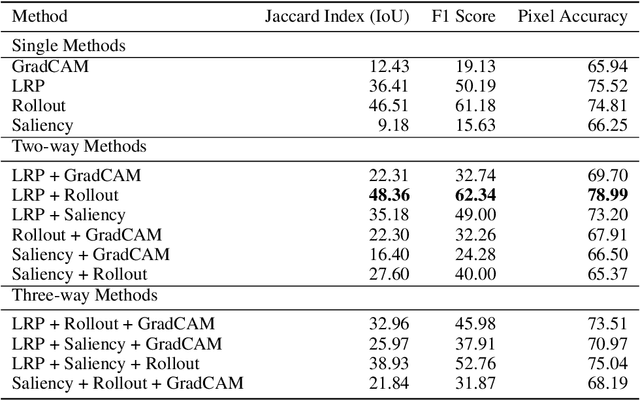
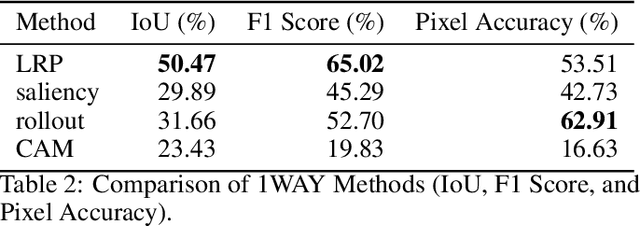

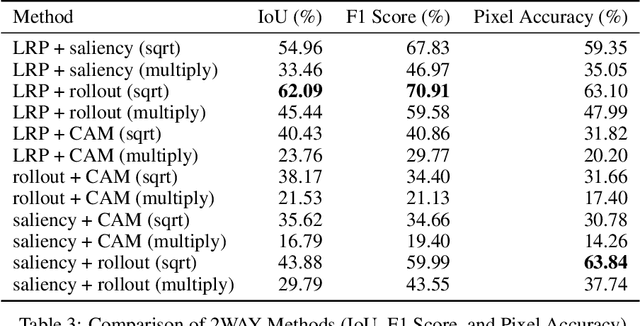
Recent advancements in Vision Transformers (ViT) have demonstrated exceptional results in various visual recognition tasks, owing to their ability to capture long-range dependencies in images through self-attention mechanisms. However, the complex nature of ViT models requires robust explainability methods to unveil their decision-making processes. Explainable Artificial Intelligence (XAI) plays a crucial role in improving model transparency and trustworthiness by providing insights into model predictions. Current approaches to ViT explainability, based on visualization techniques such as Layer-wise Relevance Propagation (LRP) and gradient-based methods, have shown promising but sometimes limited results. In this study, we explore a hybrid approach that mixes multiple explainability techniques to overcome these limitations and enhance the interpretability of ViT models. Our experiments reveal that this hybrid approach significantly improves the interpretability of ViT models compared to individual methods. We also introduce modifications to existing techniques, such as using geometric mean for mixing, which demonstrates notable results in object segmentation tasks. To quantify the explainability gain, we introduced a novel post-hoc explainability measure by applying the Pigeonhole principle. These findings underscore the importance of refining and optimizing explainability methods for ViT models, paving the way to reliable XAI-based segmentations.
Iterative Knowledge Exchange Between Deep Learning and Space-Time Spectral Clustering for Unsupervised Segmentation in Videos
Dec 13, 2020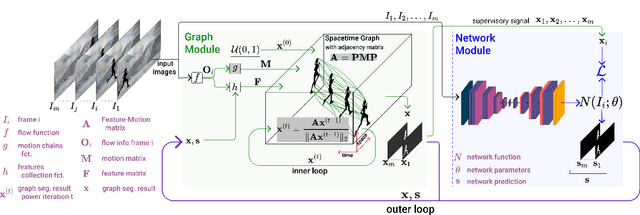
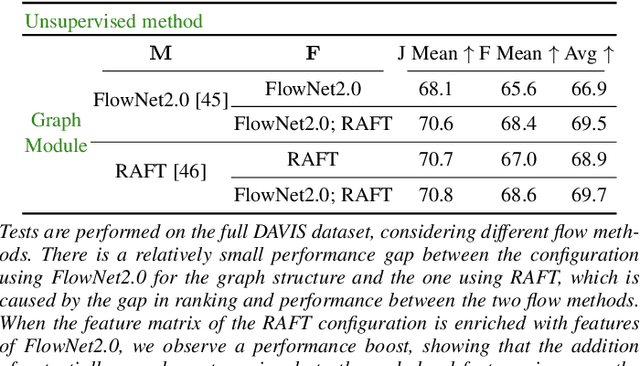
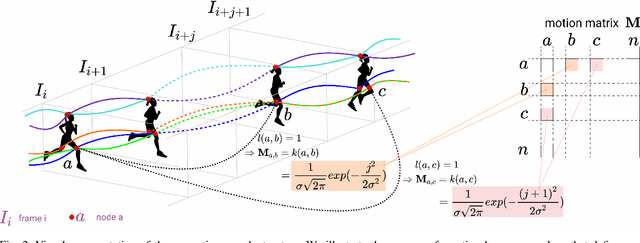
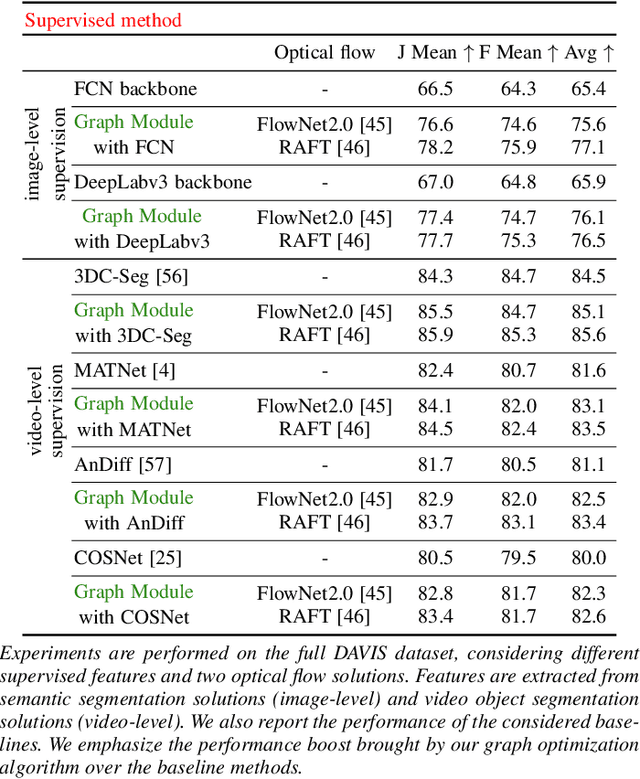
We propose a dual system for unsupervised object segmentation in video, which brings together two modules with complementary properties: a space-time graph that discovers objects in videos and a deep network that learns powerful object features. The system uses an iterative knowledge exchange policy. A novel spectral space-time clustering process on the graph produces unsupervised segmentation masks passed to the network as pseudo-labels. The net learns to segment in single frames what the graph discovers in video and passes back to the graph strong image-level features that improve its node-level features in the next iteration. Knowledge is exchanged for several cycles until convergence. The graph has one node per each video pixel, but the object discovery is fast. It uses a novel power iteration algorithm computing the main space-time cluster as the principal eigenvector of a special Feature-Motion matrix without actually computing the matrix. The thorough experimental analysis validates our theoretical claims and proves the effectiveness of the cyclical knowledge exchange. We also perform experiments on the supervised scenario, incorporating features pretrained with human supervision. We achieve state-of-the-art level on unsupervised and supervised scenarios on four challenging datasets: DAVIS, SegTrack, YouTube-Objects, and DAVSOD.
Spacetime Graph Optimization for Video Object Segmentation
Aug 03, 2019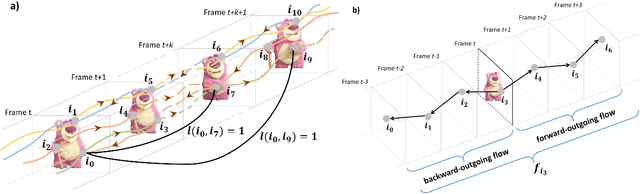

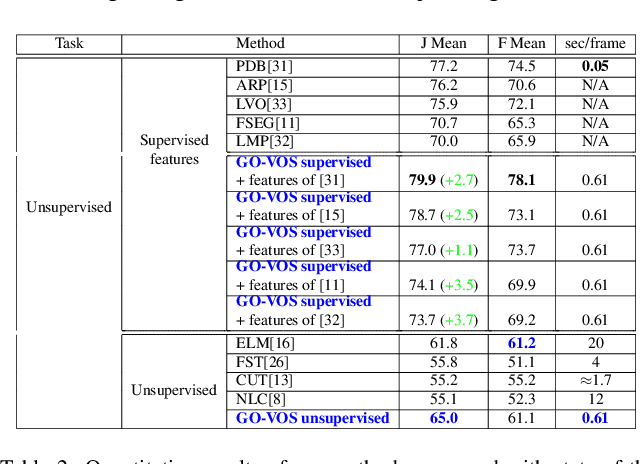
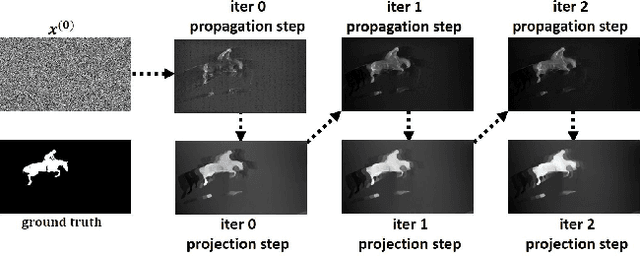
We address the challenging task of foreground object discovery and segmentation in video. We introduce an efficient solution, suitable for both unsupervised and supervised scenarios, based on a spacetime graph representation of the video sequence. We ensure a fine grained representation with one-to-one correspondences between graph nodes and video pixels. We formulate the task as a spectral clustering problem by exploiting the spatio-temporal consistency between the scene elements in terms of motion and appearance. Graph nodes that belong to the main object of interest should form a strong cluster, as they are linked through long range optical flow chains and have similar motion and appearance features along those chains. On one hand, the optimization problem aims to maximize the segmentation clustering score based on the motion structure through space and time. On the other hand, the segmentation should be consistent with respect to node features. Our approach leads to a graph formulation in which the segmentation solution becomes the principal eigenvector of a novel Feature-Motion matrix. While the actual matrix is not computed explicitly, the proposed algorithm efficiently computes, in a few iteration steps, the principal eigenvector that captures the segmentation of the main object in the video. The proposed algorithm, GO-VOS, produces a global optimum solution and, consequently, it does not depend on initialization. In practice, GO-VOS achieves state of the art results on three challenging datasets used in current literature: DAVIS, SegTrack and YouTube-Objects.