 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTmiX: Vision Transformer Explainability Augmented by Mixed Visualization Methods
Dec 18, 2024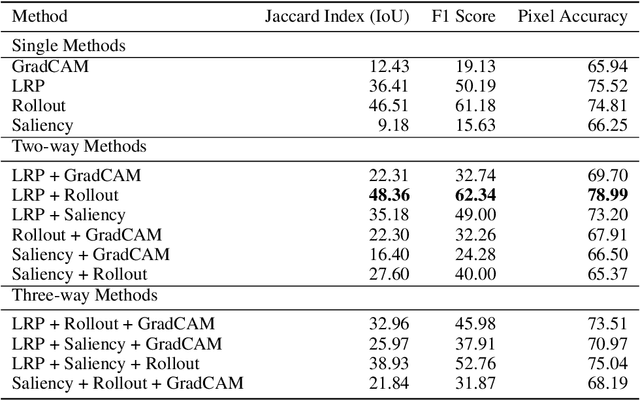
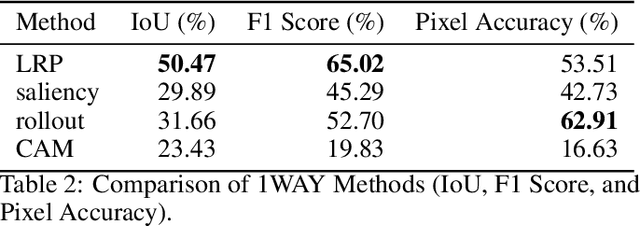

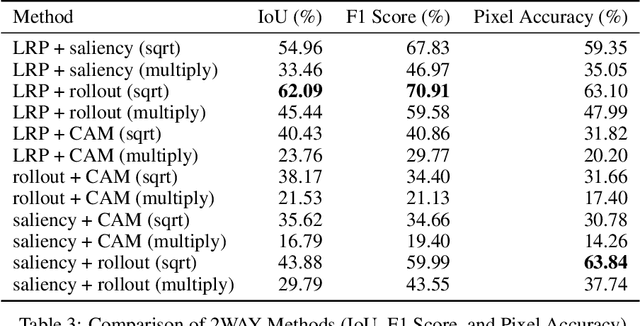
Recent advancements in Vision Transformers (ViT) have demonstrated exceptional results in various visual recognition tasks, owing to their ability to capture long-range dependencies in images through self-attention mechanisms. However, the complex nature of ViT models requires robust explainability methods to unveil their decision-making processes. Explainable Artificial Intelligence (XAI) plays a crucial role in improving model transparency and trustworthiness by providing insights into model predictions. Current approaches to ViT explainability, based on visualization techniques such as Layer-wise Relevance Propagation (LRP) and gradient-based methods, have shown promising but sometimes limited results. In this study, we explore a hybrid approach that mixes multiple explainability techniques to overcome these limitations and enhance the interpretability of ViT models. Our experiments reveal that this hybrid approach significantly improves the interpretability of ViT models compared to individual methods. We also introduce modifications to existing techniques, such as using geometric mean for mixing, which demonstrates notable results in object segmentation tasks. To quantify the explainability gain, we introduced a novel post-hoc explainability measure by applying the Pigeonhole principle. These findings underscore the importance of refining and optimizing explainability methods for ViT models, paving the way to reliable XAI-based segmentations.