 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-ing Clearly: Enhanced Binary Code Explanations using C code
Dec 16, 2025Large Language Models (LLMs) typically excel at coding tasks involving high-level programming languages, as opposed to lower-level programming languages, such as assembly. We propose a synthetic data generation method named C-ing Clearly, which leverages the corresponding C code to enhance an LLM's understanding of assembly. By fine-tuning on data generated through our method, we demonstrate improved LLM performance for binary code summarization and vulnerability detection. Our approach demonstrates consistent gains across different LLM families and model sizes.
MolMix: A Simple Yet Effective Baseline for Multimodal Molecular Representation Learning
Oct 10, 2024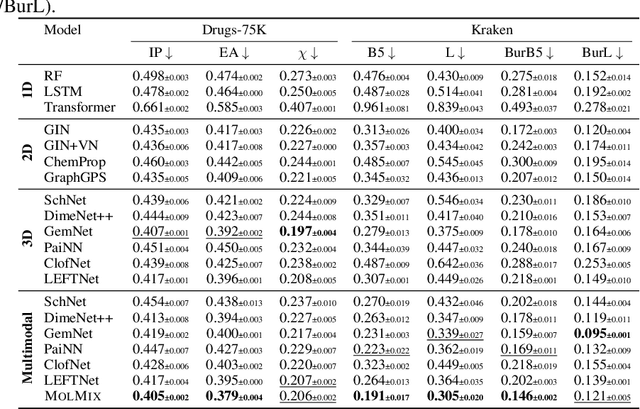
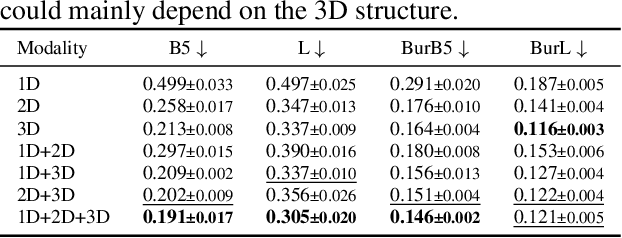
In this work, we propose a simple transformer-based baseline for multimodal molecular representation learning, integrating three distinct modalities: SMILES strings, 2D graph representations, and 3D conformers of molecules. A key aspect of our approach is the aggregation of 3D conformers, allowing the model to account for the fact that molecules can adopt multiple conformations-an important factor for accurate molecular representation. The tokens for each modality are extracted using modality-specific encoders: a transformer for SMILES strings, a message-passing neural network for 2D graphs, and an equivariant neural network for 3D conformers. The flexibility and modularity of this framework enable easy adaptation and replacement of these encoders, making the model highly versatile for different molecular tasks. The extracted tokens are then combined into a unified multimodal sequence, which is processed by a downstream transformer for prediction tasks. To efficiently scale our model for large multimodal datasets, we utilize Flash Attention 2 and bfloat16 precision. Despite its simplicity, our approach achieves state-of-the-art results across multiple datasets, demonstrating its effectiveness as a strong baseline for multimodal molecular representation learning.
Weakly-supervised deepfake localization in diffusion-generated images
Nov 13, 2023
The remarkable generative capabilities of denoising diffusion models have raised new concerns regarding the authenticity of the images we see every day on the Internet. However, the vast majority of existing deepfake detection models are tested against previous generative approaches (e.g. GAN) and usually provide only a "fake" or "real" label per image. We believe a more informative output would be to augment the per-image label with a localization map indicating which regions of the input have been manipulated. To this end, we frame this task as a weakly-supervised localization problem and identify three main categories of methods (based on either explanations, local scores or attention), which we compare on an equal footing by using the Xception network as the common backbone architecture. We provide a careful analysis of all the main factors that parameterize the design space: choice of method, type of supervision, dataset and generator used in the creation of manipulated images; our study is enabled by constructing datasets in which only one of the components is varied. Our results show that weakly-supervised localization is attainable, with the best performing detection method (based on local scores) being less sensitive to the looser supervision than to the mismatch in terms of dataset or generator.