 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbMoE: Differentiable Probabilistic Routing for Mixture-of-Experts
Jun 01, 2026Mixture-of-Experts (MoE) models scale by activating only a small subset of experts per token. However, training such models remains challenging because top-$k$ routing is discrete and non-differentiable, requiring gradient estimators for expert selection whose design remains a central open problem. We introduce ProbMoE, a probabilistic routing framework that models expert selection as a distribution over cardinality-constrained expert subsets and formulates routing as probabilistic inference in this discrete subset space. We first propose ProbMoE Exact-$k$ routing, which samples $k$-expert subsets in the forward pass, and the backward pass uses gradients through each expert's exact marginal probability as a tractable surrogate for the true gradient. ProbMoE naturally generalizes to a dynamic-$k$ routing setting, where both training and inference constrain the routing cardinality to the same predefined range, allowing adaptive expert allocation per token. Across benchmarks and model backbones, ProbMoE Exact-$k$ achieves strong performance compared to competitive baselines, with improved expert utilization and routing diversity; ProbMoE Dynamic-$k$ achieves comparable performance with fewer activated experts.
Automatic Layer Selection for Hallucination Detection
May 27, 2026Recent studies on hallucination detection have shown that hallucination-related signals are more strongly encoded in intermediate layers than in the final layer of large language models (LLMs). Although a growing body of work has sought to exploit this property for hallucination detection, how to automate the selection of high-performing layers remains underexplored, and principled methods for this purpose are still lacking. To address this gap, we first propose several hypotheses for why such signals emerge in intermediate layers and evaluate corresponding criteria for automatic layer selection across diverse LLM architectures, scales, and tasks, covering both question answering and summarization hallucination detection benchmarks. However, we find that none of these criteria consistently delivers satisfactory performance. We therefore propose a new selection criterion, First Effective Peak of Intrinsic Dimension (FEPoID), which consistently identify optimal or near-optimal layers and outperforms both the aforementioned criteria and existing hallucination detection baselines. FEPoID is training-free and incurs negligible computational overhead. In addition, we study the generation behaviors of LLMs and introduce a simple yet effective truncation strategy, which further amplifies hallucination-related signals and substantially improves overall detection performance. Code is publicly available at https://github.com/DesoloYw/Automatic-Layer-Selection-for-Hallucination-Detection.git
Deep Generative Models with Hard Linear Equality Constraints
Feb 08, 2025While deep generative models~(DGMs) have demonstrated remarkable success in capturing complex data distributions, they consistently fail to learn constraints that encode domain knowledge and thus require constraint integration. Existing solutions to this challenge have primarily relied on heuristic methods and often ignore the underlying data distribution, harming the generative performance. In this work, we propose a probabilistically sound approach for enforcing the hard constraints into DGMs to generate constraint-compliant and realistic data. This is achieved by our proposed gradient estimators that allow the constrained distribution, the data distribution conditioned on constraints, to be differentiably learned. We carry out extensive experiments with various DGM model architectures over five image datasets and three scientific applications in which domain knowledge is governed by linear equality constraints. We validate that the standard DGMs almost surely generate data violating the constraints. Among all the constraint integration strategies, ours not only guarantees the satisfaction of constraints in generation but also archives superior generative performance than the other methods across every benchmark.
A Unified Approach to Count-Based Weakly-Supervised Learning
Nov 22, 2023High-quality labels are often very scarce, whereas unlabeled data with inferred weak labels occurs more naturally. In many cases, these weak labels dictate the frequency of each respective class over a set of instances. In this paper, we develop a unified approach to learning from such weakly-labeled data, which we call count-based weakly-supervised learning. At the heart of our approach is the ability to compute the probability of exactly k out of n outputs being set to true. This computation is differentiable, exact, and efficient. Building upon the previous computation, we derive a count loss penalizing the model for deviations in its distribution from an arithmetic constraint defined over label counts. We evaluate our approach on three common weakly-supervised learning paradigms and observe that our proposed approach achieves state-of-the-art or highly competitive results across all three of the paradigms.
Probabilistically Rewired Message-Passing Neural Networks
Oct 15, 2023



Message-passing graph neural networks (MPNNs) emerged as powerful tools for processing graph-structured input. However, they operate on a fixed input graph structure, ignoring potential noise and missing information. Furthermore, their local aggregation mechanism can lead to problems such as over-squashing and limited expressive power in capturing relevant graph structures. Existing solutions to these challenges have primarily relied on heuristic methods, often disregarding the underlying data distribution. Hence, devising principled approaches for learning to infer graph structures relevant to the given prediction task remains an open challenge. In this work, leveraging recent progress in exact and differentiable $k$-subset sampling, we devise probabilistically rewired MPNNs (PR-MPNNs), which learn to add relevant edges while omitting less beneficial ones. For the first time, our theoretical analysis explores how PR-MPNNs enhance expressive power, and we identify precise conditions under which they outperform purely randomized approaches. Empirically, we demonstrate that our approach effectively mitigates issues like over-squashing and under-reaching. In addition, on established real-world datasets, our method exhibits competitive or superior predictive performance compared to traditional MPNN models and recent graph transformer architectures.
Collapsed Inference for Bayesian Deep Learning
Jun 16, 2023



Bayesian neural networks (BNNs) provide a formalism to quantify and calibrate uncertainty in deep learning. Current inference approaches for BNNs often resort to few-sample estimation for scalability, which can harm predictive performance, while its alternatives tend to be computationally prohibitively expensive. We tackle this challenge by revealing a previously unseen connection between inference on BNNs and volume computation problems. With this observation, we introduce a novel collapsed inference scheme that performs Bayesian model averaging using collapsed samples. It improves over a Monte-Carlo sample by limiting sampling to a subset of the network weights while pairing it with some closed-form conditional distribution over the rest. A collapsed sample represents uncountably many models drawn from the approximate posterior and thus yields higher sample efficiency. Further, we show that the marginalization of a collapsed sample can be solved analytically and efficiently despite the non-linearity of neural networks by leveraging existing volume computation solvers. Our proposed use of collapsed samples achieves a balance between scalability and accuracy. On various regression and classification tasks, our collapsed Bayesian deep learning approach demonstrates significant improvements over existing methods and sets a new state of the art in terms of uncertainty estimation as well as predictive performance.
SIMPLE: A Gradient Estimator for $k$-Subset Sampling
Oct 04, 2022
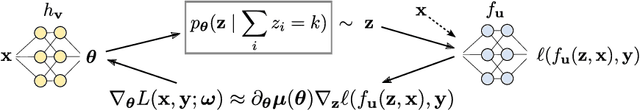
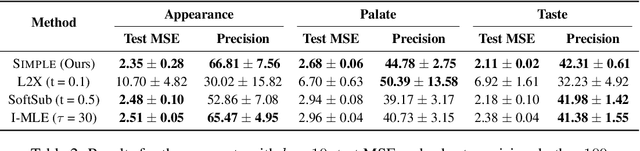
$k$-subset sampling is ubiquitous in machine learning, enabling regularization and interpretability through sparsity. The challenge lies in rendering $k$-subset sampling amenable to end-to-end learning. This has typically involved relaxing the reparameterized samples to allow for backpropagation, with the risk of introducing high bias and high variance. In this work, we fall back to discrete $k$-subset sampling on the forward pass. This is coupled with using the gradient with respect to the exact marginals, computed efficiently, as a proxy for the true gradient. We show that our gradient estimator, SIMPLE, exhibits lower bias and variance compared to state-of-the-art estimators, including the straight-through Gumbel estimator when $k = 1$. Empirical results show improved performance on learning to explain and sparse linear regression. We provide an algorithm for computing the exact ELBO for the $k$-subset distribution, obtaining significantly lower loss compared to SOTA.
Tractable Computation of Expected Kernels by Circuits
Feb 21, 2021


Computing the expectation of some kernel function is ubiquitous in machine learning, from the classical theory of support vector machines, to exploiting kernel embeddings of distributions in applications ranging from probabilistic modeling, statistical inference, casual discovery, and deep learning. In all these scenarios, we tend to resort to Monte Carlo estimates as expectations of kernels are intractable in general. In this work, we characterize the conditions under which we can compute expected kernels exactly and efficiently, by leveraging recent advances in probabilistic circuit representations. We first construct a circuit representation for kernels and propose an approach to such tractable computation. We then demonstrate possible advancements for kernel embedding frameworks by exploiting tractable expected kernels to derive new algorithms for two challenging scenarios: 1) reasoning under missing data with kernel support vector regressors; 2) devising a collapsed black-box importance sampling scheme. Finally, we empirically evaluate both algorithms and show that they outperform standard baselines on a variety of datasets.
Scaling up Hybrid Probabilistic Inference with Logical and Arithmetic Constraints via Message Passing
Feb 28, 2020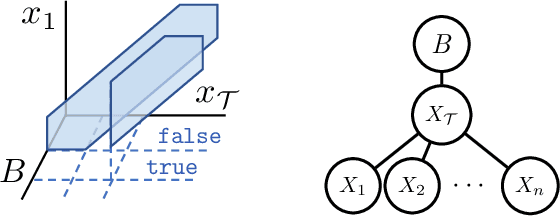
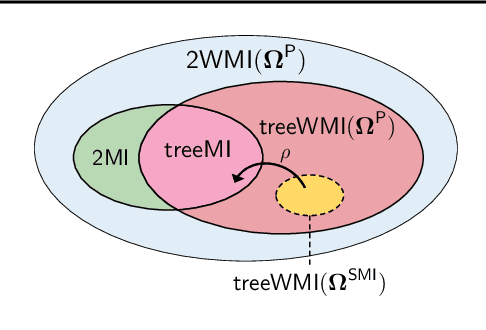
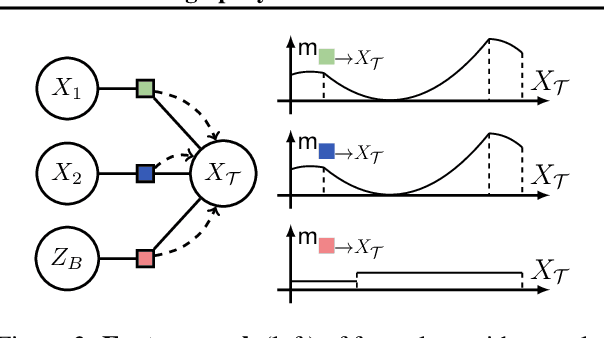
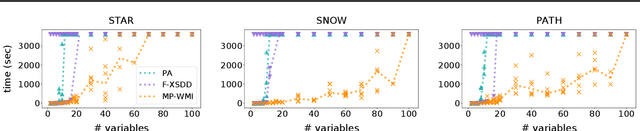
Weighted model integration (WMI) is a very appealing framework for probabilistic inference: it allows to express the complex dependencies of real-world problems where variables are both continuous and discrete, via the language of Satisfiability Modulo Theories (SMT), as well as to compute probabilistic queries with complex logical and arithmetic constraints. Yet, existing WMI solvers are not ready to scale to these problems. They either ignore the intrinsic dependency structure of the problem at all, or they are limited to too restrictive structures. To narrow this gap, we derive a factorized formalism of WMI enabling us to devise a scalable WMI solver based on message passing, MP-WMI. Namely, MP-WMI is the first WMI solver which allows to: 1) perform exact inference on the full class of tree-structured WMI problems; 2) compute all marginal densities in linear time; 3) amortize inference inter query. Experimental results show that our solver dramatically outperforms the existing WMI solvers on a large set of benchmarks.
Hybrid Probabilistic Inference with Logical Constraints: Tractability and Message Passing
Sep 30, 2019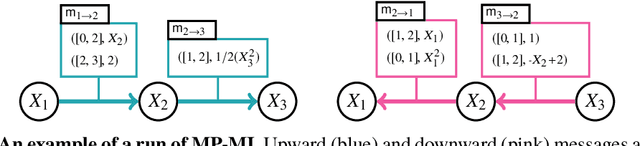

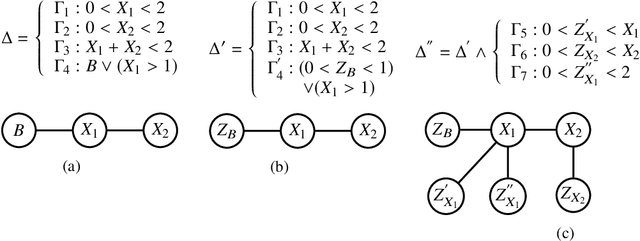
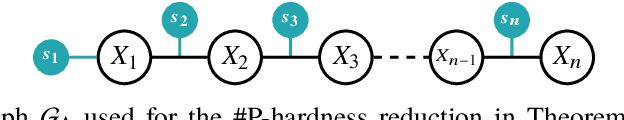
Weighted model integration (WMI) is a very appealing framework for probabilistic inference: it allows to express the complex dependencies of real-world hybrid scenarios where variables are heterogeneous in nature (both continuous and discrete) via the language of Satisfiability Modulo Theories (SMT); as well as computing probabilistic queries with arbitrarily complex logical constraints. Recent work has shown WMI inference to be reducible to a model integration (MI) problem, under some assumptions, thus effectively allowing hybrid probabilistic reasoning by volume computations. In this paper, we introduce a novel formulation of MI via a message passing scheme that allows to efficiently compute the marginal densities and statistical moments of all the variables in linear time. As such, we are able to amortize inference for arbitrarily rich MI queries when they conform to the problem structure, here represented as the primal graph associated to the SMT formula. Furthermore, we theoretically trace the tractability boundaries of exact MI. Indeed, we prove that in terms of the structural requirements on the primal graph that make our MI algorithm tractable - bounding its diameter and treewidth - the bounds are not only sufficient, but necessary for tractable inference via MI.