 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrables: Tabular Learning Beyond Independent Rows
Feb 03, 2026Tabular learning is still dominated by row-wise predictors that score each row independently, which fits i.i.d. benchmarks but fails on transactional, temporal, and relational tables where labels depend on other rows. We show that row-wise prediction rules out natural targets driven by global counts, overlaps, and relational patterns. To make "using structure" precise across architectures, we introduce grables: a modular interface that separates how a table is lifted to a graph (constructor) from how predictions are computed on that graph (node predictor), pinpointing where expressive power comes from. Experiments on synthetic tasks, transaction data, and a RelBench clinical-trials dataset confirm the predicted separations: message passing captures inter-row dependencies that row-local models miss, and hybrid approaches that explicitly extract inter-row structure and feed it to strong tabular learners yield consistent gains.
A Logical View of GNN-Style Computation and the Role of Activation Functions
Dec 22, 2025We study the numerical and Boolean expressiveness of MPLang, a declarative language that captures the computation of graph neural networks (GNNs) through linear message passing and activation functions. We begin with A-MPLang, the fragment without activation functions, and give a characterization of its expressive power in terms of walk-summed features. For bounded activation functions, we show that (under mild conditions) all eventually constant activations yield the same expressive power - numerical and Boolean - and that it subsumes previously established logics for GNNs with eventually constant activation functions but without linear layers. Finally, we prove the first expressive separation between unbounded and bounded activations in the presence of linear layers: MPLang with ReLU is strictly more powerful for numerical queries than MPLang with eventually constant activation functions, e.g., truncated ReLU. This hinges on subtle interactions between linear aggregation and eventually constant non-linearities, and it establishes that GNNs using ReLU are more expressive than those restricted to eventually constant activations and linear layers.
DeepGraphLog for Layered Neurosymbolic AI
Sep 09, 2025Neurosymbolic AI (NeSy) aims to integrate the statistical strengths of neural networks with the interpretability and structure of symbolic reasoning. However, current NeSy frameworks like DeepProbLog enforce a fixed flow where symbolic reasoning always follows neural processing. This restricts their ability to model complex dependencies, especially in irregular data structures such as graphs. In this work, we introduce DeepGraphLog, a novel NeSy framework that extends ProbLog with Graph Neural Predicates. DeepGraphLog enables multi-layer neural-symbolic reasoning, allowing neural and symbolic components to be layered in arbitrary order. In contrast to DeepProbLog, which cannot handle symbolic reasoning via neural methods, DeepGraphLog treats symbolic representations as graphs, enabling them to be processed by Graph Neural Networks (GNNs). We showcase the capabilities of DeepGraphLog on tasks in planning, knowledge graph completion with distant supervision, and GNN expressivity. Our results demonstrate that DeepGraphLog effectively captures complex relational dependencies, overcoming key limitations of existing NeSy systems. By broadening the applicability of neurosymbolic AI to graph-structured domains, DeepGraphLog offers a more expressive and flexible framework for neural-symbolic integration.
Covered Forest: Fine-grained generalization analysis of graph neural networks
Dec 10, 2024The expressive power of message-passing graph neural networks (MPNNs) is reasonably well understood, primarily through combinatorial techniques from graph isomorphism testing. However, MPNNs' generalization abilities -- making meaningful predictions beyond the training set -- remain less explored. Current generalization analyses often overlook graph structure, limit the focus to specific aggregation functions, and assume the impractical, hard-to-optimize $0$-$1$ loss function. Here, we extend recent advances in graph similarity theory to assess the influence of graph structure, aggregation, and loss functions on MPNNs' generalization abilities. Our empirical study supports our theoretical insights, improving our understanding of MPNNs' generalization properties.
Towards Bridging Generalization and Expressivity of Graph Neural Networks
Oct 14, 2024Expressivity and generalization are two critical aspects of graph neural networks (GNNs). While significant progress has been made in studying the expressivity of GNNs, much less is known about their generalization capabilities, particularly when dealing with the inherent complexity of graph-structured data. In this work, we address the intricate relationship between expressivity and generalization in GNNs. Theoretical studies conjecture a trade-off between the two: highly expressive models risk overfitting, while those focused on generalization may sacrifice expressivity. However, empirical evidence often contradicts this assumption, with expressive GNNs frequently demonstrating strong generalization. We explore this contradiction by introducing a novel framework that connects GNN generalization to the variance in graph structures they can capture. This leads us to propose a $k$-variance margin-based generalization bound that characterizes the structural properties of graph embeddings in terms of their upper-bounded expressive power. Our analysis does not rely on specific GNN architectures, making it broadly applicable across GNN models. We further uncover a trade-off between intra-class concentration and inter-class separation, both of which are crucial for effective generalization. Through case studies and experiments on real-world datasets, we demonstrate that our theoretical findings align with empirical results, offering a deeper understanding of how expressivity can enhance GNN generalization.
A note on the VC dimension of 1-dimensional GNNs
Oct 10, 2024
Graph Neural Networks (GNNs) have become an essential tool for analyzing graph-structured data, leveraging their ability to capture complex relational information. While the expressivity of GNNs, particularly their equivalence to the Weisfeiler-Leman (1-WL) isomorphism test, has been well-documented, understanding their generalization capabilities remains critical. This paper focuses on the generalization of GNNs by investigating their Vapnik-Chervonenkis (VC) dimension. We extend previous results to demonstrate that 1-dimensional GNNs with a single parameter have an infinite VC dimension for unbounded graphs. Furthermore, we show that this also holds for GNNs using analytic non-polynomial activation functions, including the 1-dimensional GNNs that were recently shown to be as expressive as the 1-WL test. These results suggest inherent limitations in the generalization ability of even the most simple GNNs, when viewed from the VC dimension perspective.
Weisfeiler-Leman at the margin: When more expressivity matters
Feb 12, 2024



The Weisfeiler-Leman algorithm ($1$-WL) is a well-studied heuristic for the graph isomorphism problem. Recently, the algorithm has played a prominent role in understanding the expressive power of message-passing graph neural networks (MPNNs) and being effective as a graph kernel. Despite its success, $1$-WL faces challenges in distinguishing non-isomorphic graphs, leading to the development of more expressive MPNN and kernel architectures. However, the relationship between enhanced expressivity and improved generalization performance remains unclear. Here, we show that an architecture's expressivity offers limited insights into its generalization performance when viewed through graph isomorphism. Moreover, we focus on augmenting $1$-WL and MPNNs with subgraph information and employ classical margin theory to investigate the conditions under which an architecture's increased expressivity aligns with improved generalization performance. In addition, we show that gradient flow pushes the MPNN's weights toward the maximum margin solution. Further, we introduce variations of expressive $1$-WL-based kernel and MPNN architectures with provable generalization properties. Our empirical study confirms the validity of our theoretical findings.
A neuro-symbolic framework for answering conjunctive queries
Oct 06, 2023The problem of answering logical queries over incomplete knowledge graphs is receiving significant attention in the machine learning community. Neuro-symbolic models are a promising recent approach, showing good performance and allowing for good interpretability properties. These models rely on trained architectures to execute atomic queries, combining them with modules that simulate the symbolic operators in queries. Unfortunately, most neuro-symbolic query processors are limited to the so-called tree-like logical queries that admit a bottom-up execution, where the leaves are constant values or anchors, and the root is the target variable. Tree-like queries, while expressive, fail short to express properties in knowledge graphs that are important in practice, such as the existence of multiple edges between entities or the presence of triangles. We propose a framework for answering arbitrary conjunctive queries over incomplete knowledge graphs. The main idea of our method is to approximate a cyclic query by an infinite family of tree-like queries, and then leverage existing models for the latter. Our approximations achieve strong guarantees: they are complete, i.e. there are no false negatives, and optimal, i.e. they provide the best possible approximation using tree-like queries. Our method requires the approximations to be tree-like queries where the leaves are anchors or existentially quantified variables. Hence, we also show how some of the existing neuro-symbolic models can handle these queries, which is of independent interest. Experiments show that our approximation strategy achieves competitive results, and that including queries with existentially quantified variables tends to improve the general performance of these models, both on tree-like queries and on our approximation strategy.
WL meet VC
Jan 26, 2023Recently, many works studied the expressive power of graph neural networks (GNNs) by linking it to the $1$-dimensional Weisfeiler--Leman algorithm ($1\text{-}\mathsf{WL}$). Here, the $1\text{-}\mathsf{WL}$ is a well-studied heuristic for the graph isomorphism problem, which iteratively colors or partitions a graph's vertex set. While this connection has led to significant advances in understanding and enhancing GNNs' expressive power, it does not provide insights into their generalization performance, i.e., their ability to make meaningful predictions beyond the training set. In this paper, we study GNNs' generalization ability through the lens of Vapnik--Chervonenkis (VC) dimension theory in two settings, focusing on graph-level predictions. First, when no upper bound on the graphs' order is known, we show that the bitlength of GNNs' weights tightly bounds their VC dimension. Further, we derive an upper bound for GNNs' VC dimension using the number of colors produced by the $1\text{-}\mathsf{WL}$. Secondly, when an upper bound on the graphs' order is known, we show a tight connection between the number of graphs distinguishable by the $1\text{-}\mathsf{WL}$ and GNNs' VC dimension. Our empirical study confirms the validity of our theoretical findings.
Ordered Subgraph Aggregation Networks
Jun 28, 2022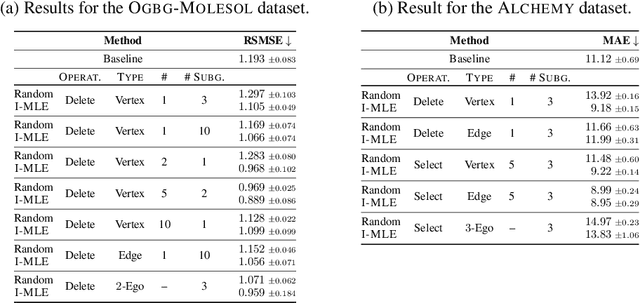
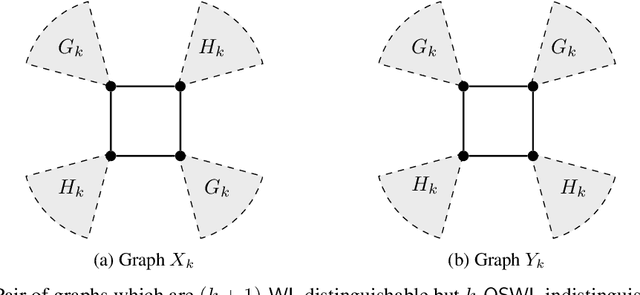
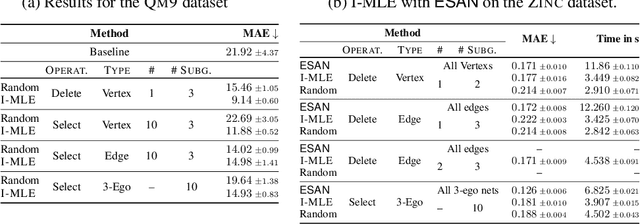

Numerous subgraph-enhanced graph neural networks (GNNs) have emerged recently, provably boosting the expressive power of standard (message-passing) GNNs. However, there is a limited understanding of how these approaches relate to each other and to the Weisfeiler--Leman hierarchy. Moreover, current approaches either use all subgraphs of a given size, sample them uniformly at random, or use hand-crafted heuristics instead of learning to select subgraphs in a data-driven manner. Here, we offer a unified way to study such architectures by introducing a theoretical framework and extending the known expressivity results of subgraph-enhanced GNNs. Concretely, we show that increasing subgraph size always increases the expressive power and develop a better understanding of their limitations by relating them to the established $k\text{-}\mathsf{WL}$ hierarchy. In addition, we explore different approaches for learning to sample subgraphs using recent methods for backpropagating through complex discrete probability distributions. Empirically, we study the predictive performance of different subgraph-enhanced GNNs, showing that our data-driven architectures increase prediction accuracy on standard benchmark datasets compared to non-data-driven subgraph-enhanced graph neural networks while reducing computation time.