 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViSpeechFormer: A Phonemic Approach for Vietnamese Automatic Speech Recognition
Feb 10, 2026Vietnamese has a phonetic orthography, where each grapheme corresponds to at most one phoneme and vice versa. Exploiting this high grapheme-phoneme transparency, we propose ViSpeechFormer (\textbf{Vi}etnamese \textbf{Speech} Trans\textbf{Former}), a phoneme-based approach for Vietnamese Automatic Speech Recognition (ASR). To the best of our knowledge, this is the first Vietnamese ASR framework that explicitly models phonemic representations. Experiments on two publicly available Vietnamese ASR datasets show that ViSpeechFormer achieves strong performance, generalizes better to out-of-vocabulary words, and is less affected by training bias. This phoneme-based paradigm is also promising for other languages with phonetic orthographies. The code will be released upon acceptance of this paper.
Multi-Dialect Vietnamese: Task, Dataset, Baseline Models and Challenges
Oct 04, 2024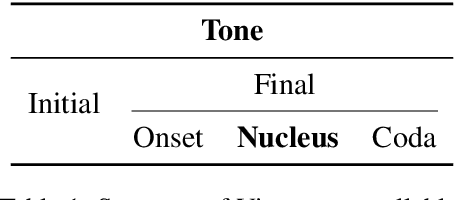
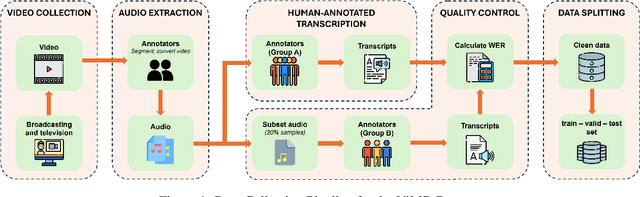
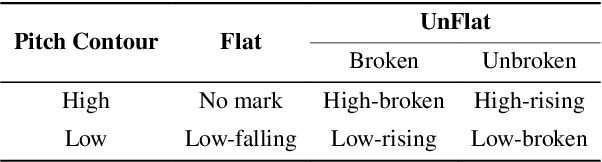
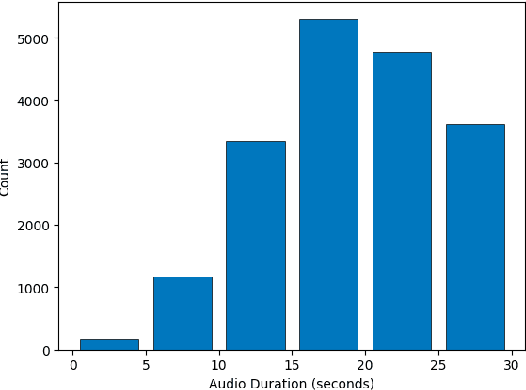
Vietnamese, a low-resource language, is typically categorized into three primary dialect groups that belong to Northern, Central, and Southern Vietnam. However, each province within these regions exhibits its own distinct pronunciation variations. Despite the existence of various speech recognition datasets, none of them has provided a fine-grained classification of the 63 dialects specific to individual provinces of Vietnam. To address this gap, we introduce Vietnamese Multi-Dialect (ViMD) dataset, a novel comprehensive dataset capturing the rich diversity of 63 provincial dialects spoken across Vietnam. Our dataset comprises 102.56 hours of audio, consisting of approximately 19,000 utterances, and the associated transcripts contain over 1.2 million words. To provide benchmarks and simultaneously demonstrate the challenges of our dataset, we fine-tune state-of-the-art pre-trained models for two downstream tasks: (1) Dialect identification and (2) Speech recognition. The empirical results suggest two implications including the influence of geographical factors on dialects, and the constraints of current approaches in speech recognition tasks involving multi-dialect speech data. Our dataset is available for research purposes.
ViHateT5: Enhancing Hate Speech Detection in Vietnamese With A Unified Text-to-Text Transformer Model
May 23, 2024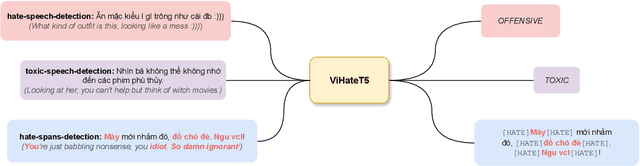
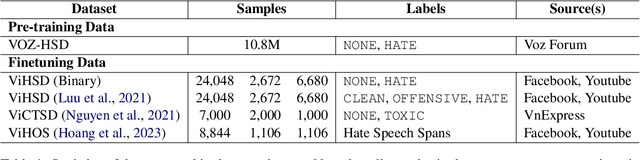
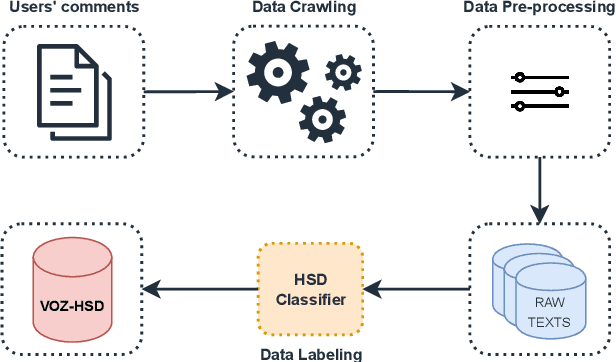
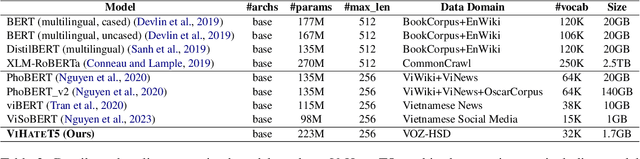
Recent advancements in hate speech detection (HSD) in Vietnamese have made significant progress, primarily attributed to the emergence of transformer-based pre-trained language models, particularly those built on the BERT architecture. However, the necessity for specialized fine-tuned models has resulted in the complexity and fragmentation of developing a multitasking HSD system. Moreover, most current methodologies focus on fine-tuning general pre-trained models, primarily trained on formal textual datasets like Wikipedia, which may not accurately capture human behavior on online platforms. In this research, we introduce ViHateT5, a T5-based model pre-trained on our proposed large-scale domain-specific dataset named VOZ-HSD. By harnessing the power of a text-to-text architecture, ViHateT5 can tackle multiple tasks using a unified model and achieve state-of-the-art performance across all standard HSD benchmarks in Vietnamese. Our experiments also underscore the significance of label distribution in pre-training data on model efficacy. We provide our experimental materials for research purposes, including the VOZ-HSD dataset, pre-trained checkpoint, the unified HSD-multitask ViHateT5 model, and related source code on GitHub publicly.
Gendec: A Machine Learning-based Framework for Gender Detection from Japanese Names
Nov 18, 2023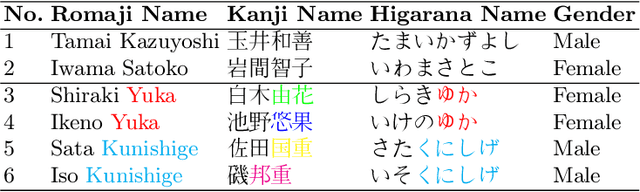
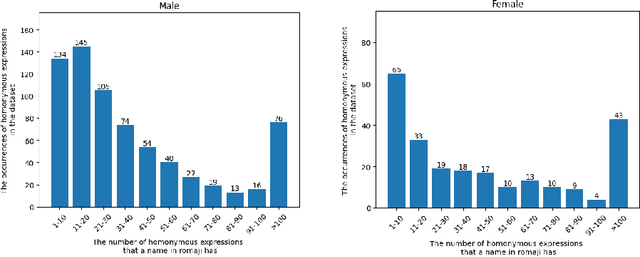

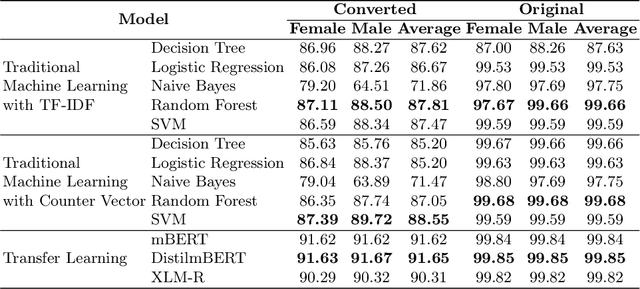
Every human has their own name, a fundamental aspect of their identity and cultural heritage. The name often conveys a wealth of information, including details about an individual's background, ethnicity, and, especially, their gender. By detecting gender through the analysis of names, researchers can unlock valuable insights into linguistic patterns and cultural norms, which can be applied to practical applications. Hence, this work presents a novel dataset for Japanese name gender detection comprising 64,139 full names in romaji, hiragana, and kanji forms, along with their biological genders. Moreover, we propose Gendec, a framework for gender detection from Japanese names that leverages diverse approaches, including traditional machine learning techniques or cutting-edge transfer learning models, to predict the gender associated with Japanese names accurately. Through a thorough investigation, the proposed framework is expected to be effective and serve potential applications in various domains.
SMTCE: A Social Media Text Classification Evaluation Benchmark and BERTology Models for Vietnamese
Sep 21, 2022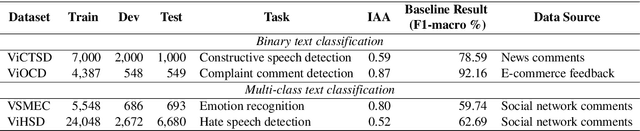
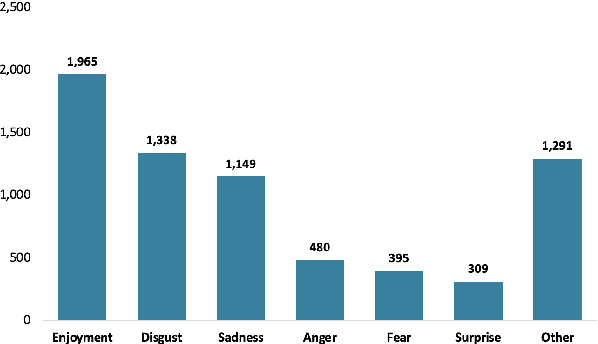
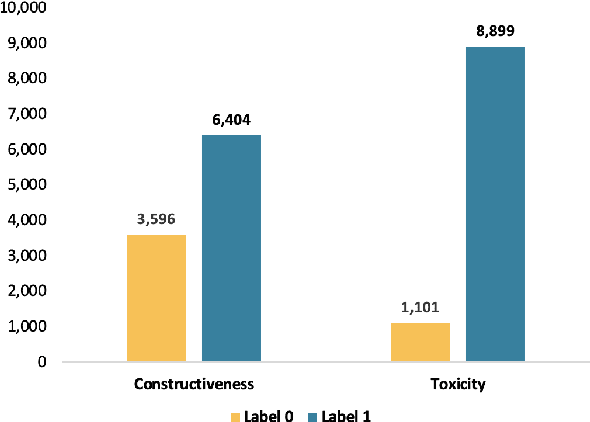
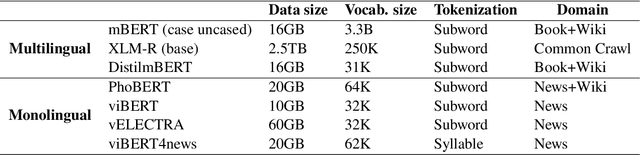
Text classification is a typical natural language processing or computational linguistics task with various interesting applications. As the number of users on social media platforms increases, data acceleration promotes emerging studies on Social Media Text Classification (SMTC) or social media text mining on these valuable resources. In contrast to English, Vietnamese, one of the low-resource languages, is still not concentrated on and exploited thoroughly. Inspired by the success of the GLUE, we introduce the Social Media Text Classification Evaluation (SMTCE) benchmark, as a collection of datasets and models across a diverse set of SMTC tasks. With the proposed benchmark, we implement and analyze the effectiveness of a variety of multilingual BERT-based models (mBERT, XLM-R, and DistilmBERT) and monolingual BERT-based models (PhoBERT, viBERT, vELECTRA, and viBERT4news) for tasks in the SMTCE benchmark. Monolingual models outperform multilingual models and achieve state-of-the-art results on all text classification tasks. It provides an objective assessment of multilingual and monolingual BERT-based models on the benchmark, which will benefit future studies about BERTology in the Vietnamese language.
SPBERTQA: A Two-Stage Question Answering System Based on Sentence Transformers for Medical Texts
Jun 20, 2022

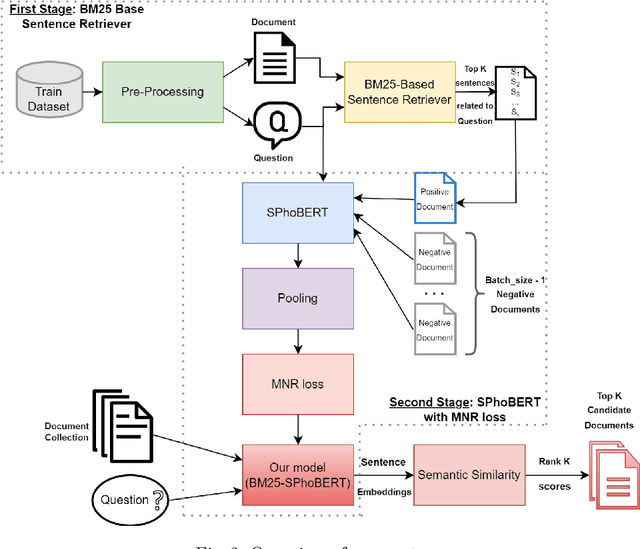
Question answering (QA) systems have gained explosive attention in recent years. However, QA tasks in Vietnamese do not have many datasets. Significantly, there is mostly no dataset in the medical domain. Therefore, we built a Vietnamese Healthcare Question Answering dataset (ViHealthQA), including 10,015 question-answer passage pairs for this task, in which questions from health-interested users were asked on prestigious health websites and answers from highly qualified experts. This paper proposes a two-stage QA system based on Sentence-BERT (SBERT) using multiple negatives ranking (MNR) loss combined with BM25. Then, we conduct diverse experiments with many bag-of-words models to assess our system's performance. With the obtained results, this system achieves better performance than traditional methods.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022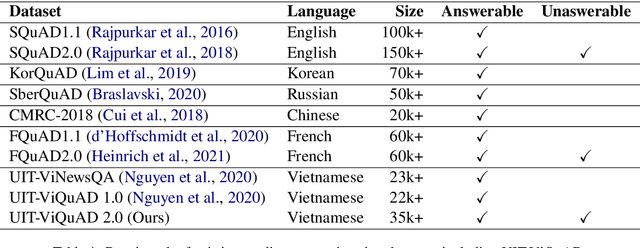
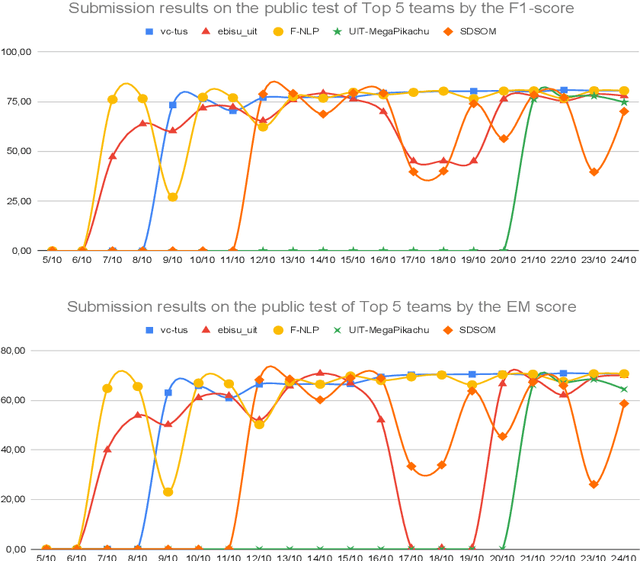

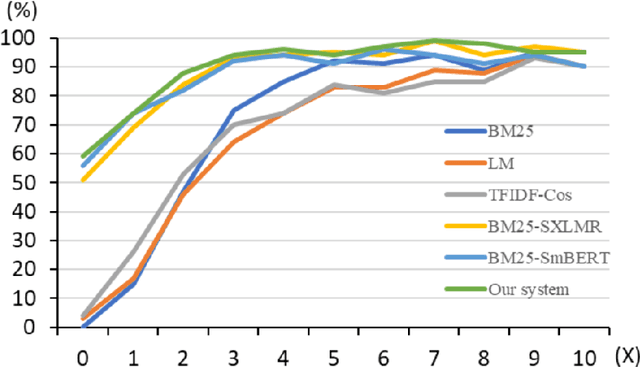
One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
SA2SL: From Aspect-Based Sentiment Analysis to Social Listening System for Business Intelligence
Jun 10, 2021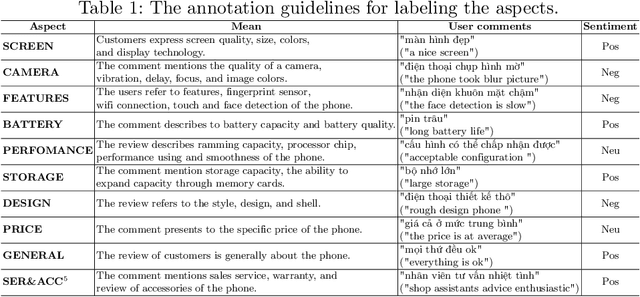
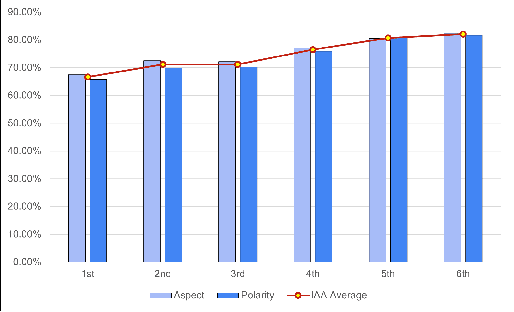
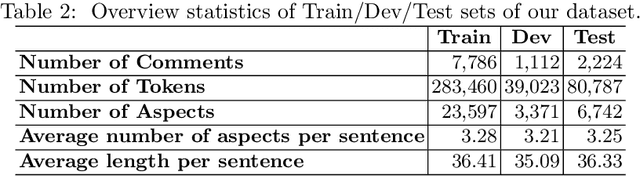
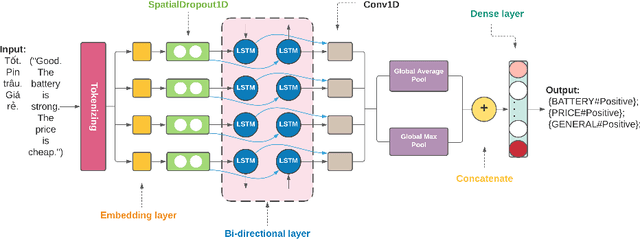
In this paper, we present a process of building a social listening system based on aspect-based sentiment analysis in Vietnamese from creating a dataset to building a real application. Firstly, we create UIT-ViSFD, a Vietnamese Smartphone Feedback Dataset as a new benchmark corpus built based on a strict annotation schemes for evaluating aspect-based sentiment analysis, consisting of 11,122 human-annotated comments for mobile e-commerce, which is freely available for research purposes. We also present a proposed approach based on the Bi-LSTM architecture with the fastText word embeddings for the Vietnamese aspect based sentiment task. Our experiments show that our approach achieves the best performances with the F1-score of 84.48% for the aspect task and 63.06% for the sentiment task, which performs several conventional machine learning and deep learning systems. Last but not least, we build SA2SL, a social listening system based on the best performance model on our dataset, which will inspire more social listening systems in future.
Vietnamese Open-domain Complaint Detection in E-Commerce Websites
May 10, 2021
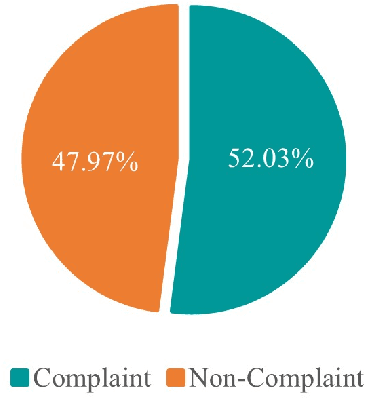
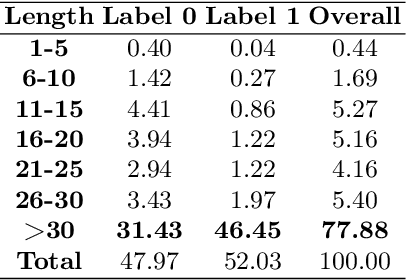
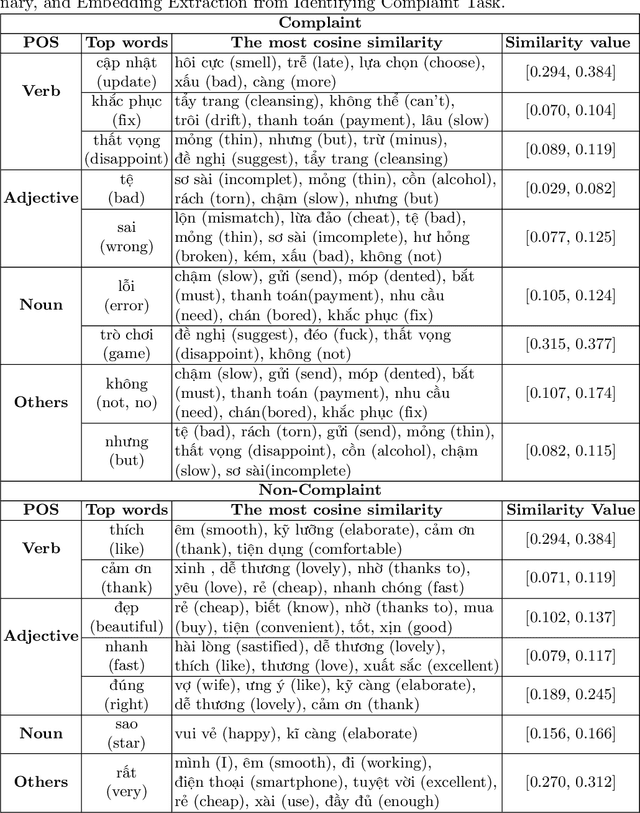
Customer product reviews play a role in improving the quality of products and services for business organizations or their brands. Complaining is an attitude that expresses dissatisfaction with an event or a product not meeting customer expectations. In this paper, we build a Open-domain Complaint Detection dataset (UIT-ViOCD), including 5,485 human-annotated reviews on four categories about product reviews on e-commerce sites. After the data collection phase, we proceed to the annotation task and achieve the inter-annotator agreement Am of 87%. Then, we present an extensive methodology for the research purposes and achieve 92.16% by F1-score for identifying complaints. With the results, in the future, we aim to build a system for open-domain complaint detection in E-commerce websites.
UIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Apr 15, 2021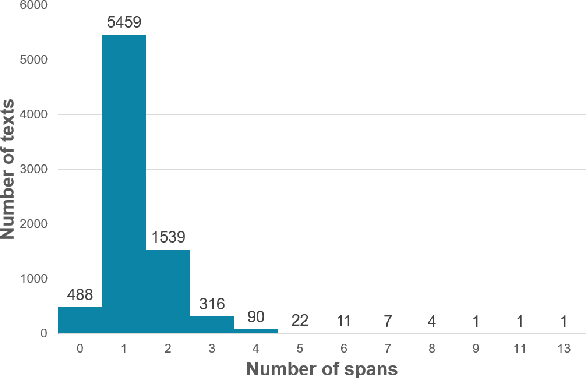

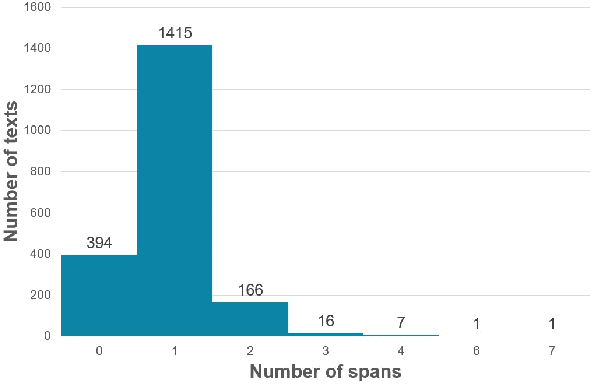

The increment of toxic comments on online space is causing tremendous effects on other vulnerable users. For this reason, considerable efforts are made to deal with this, and SemEval-2021 Task 5: Toxic Spans Detection is one of those. This task asks competitors to extract spans that have toxicity from the given texts, and we have done several analyses to understand its structure before doing experiments. We solve this task by two approaches, Named Entity Recognition with spaCy library and Question-Answering with RoBERTa combining with ToxicBERT, and the former gains the highest F1-score of 66.99%.