Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIT-E10dot3 at SemEval-2021 Task 5: Toxic Spans Detection with Named Entity Recognition and Question-Answering Approaches
Paper and Code
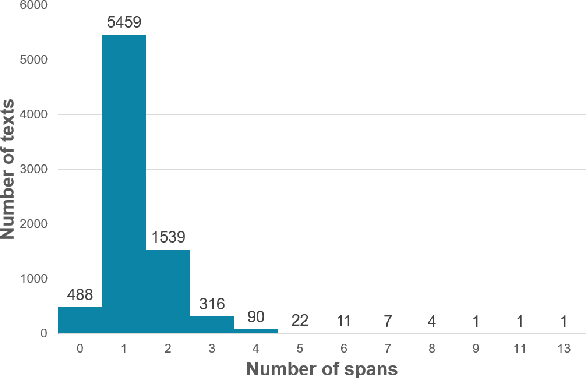

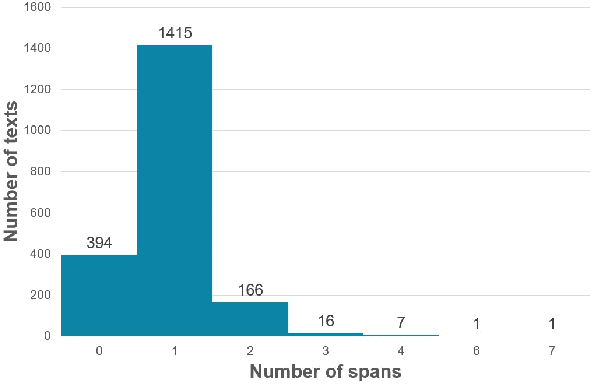

The increment of toxic comments on online space is causing tremendous effects on other vulnerable users. For this reason, considerable efforts are made to deal with this, and SemEval-2021 Task 5: Toxic Spans Detection is one of those. This task asks competitors to extract spans that have toxicity from the given texts, and we have done several analyses to understand its structure before doing experiments. We solve this task by two approaches, Named Entity Recognition with spaCy library and Question-Answering with RoBERTa combining with ToxicBERT, and the former gains the highest F1-score of 66.99%.
* Accepted at SemEval-2021 Task 5: Toxic Spans Detection, ACL-IJCNLP
2021
View paper on