 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpan Detection for Aspect-Based Sentiment Analysis in Vietnamese
Oct 15, 2021



Aspect-based sentiment analysis plays an essential role in natural language processing and artificial intelligence. Recently, researchers only focused on aspect detection and sentiment classification but ignoring the sub-task of detecting user opinion span, which has enormous potential in practical applications. In this paper, we present a new Vietnamese dataset (UIT-ViSD4SA) consisting of 35,396 human-annotated spans on 11,122 feedback comments for evaluating the span detection in aspect-based sentiment analysis. Besides, we also propose a novel system using Bidirectional Long Short-Term Memory (BiLSTM) with a Conditional Random Field (CRF) layer (BiLSTM-CRF) for the span detection task in Vietnamese aspect-based sentiment analysis. The best result is a 62.76% F1 score (macro) for span detection using BiLSTM-CRF with embedding fusion of syllable embedding, character embedding, and contextual embedding from XLM-RoBERTa. In future work, span detection will be extended in many NLP tasks such as constructive detection, emotion recognition, complaint analysis, and opinion mining. Our dataset is freely available at https://github.com/kimkim00/UIT-ViSD4SA for research purposes.
SA2SL: From Aspect-Based Sentiment Analysis to Social Listening System for Business Intelligence
Jun 10, 2021
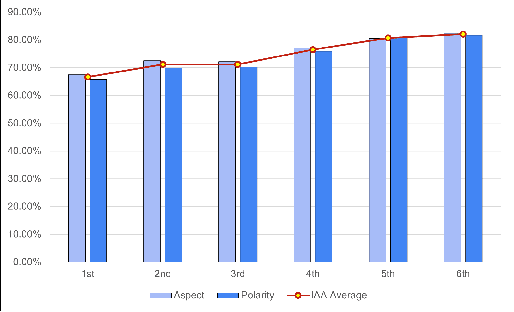
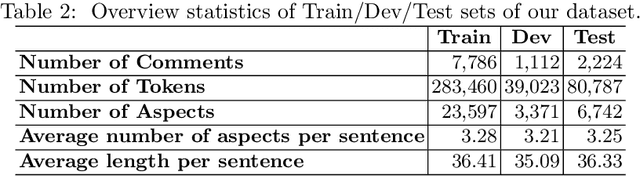
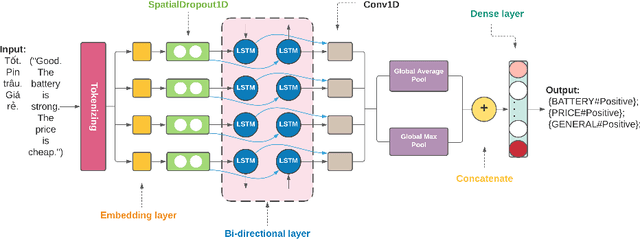
In this paper, we present a process of building a social listening system based on aspect-based sentiment analysis in Vietnamese from creating a dataset to building a real application. Firstly, we create UIT-ViSFD, a Vietnamese Smartphone Feedback Dataset as a new benchmark corpus built based on a strict annotation schemes for evaluating aspect-based sentiment analysis, consisting of 11,122 human-annotated comments for mobile e-commerce, which is freely available for research purposes. We also present a proposed approach based on the Bi-LSTM architecture with the fastText word embeddings for the Vietnamese aspect based sentiment task. Our experiments show that our approach achieves the best performances with the F1-score of 84.48% for the aspect task and 63.06% for the sentiment task, which performs several conventional machine learning and deep learning systems. Last but not least, we build SA2SL, a social listening system based on the best performance model on our dataset, which will inspire more social listening systems in future.
ReINTEL Challenge 2020: Exploiting Transfer Learning Models for Reliable Intelligence Identification on Vietnamese Social Network Sites
Feb 24, 2021



This paper presents the system that we propose for the Reliable Intelligence Indentification on Vietnamese Social Network Sites (ReINTEL) task of the Vietnamese Language and Speech Processing 2020 (VLSP 2020) Shared Task. In this task, the VLSP 2020 provides a dataset with approximately 6,000 trainning news/posts annotated with reliable or unreliable labels, and a test set consists of 2,000 examples without labels. In this paper, we conduct experiments on different transfer learning models, which are bert4news and PhoBERT fine-tuned to predict whether the news is reliable or not. In our experiments, we achieve the AUC score of 94.52% on the private test set from ReINTEL's organizers.