 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiGT: Layout-infused Generative Transformer for Visual Question Answering on Vietnamese Receipts
Feb 26, 2025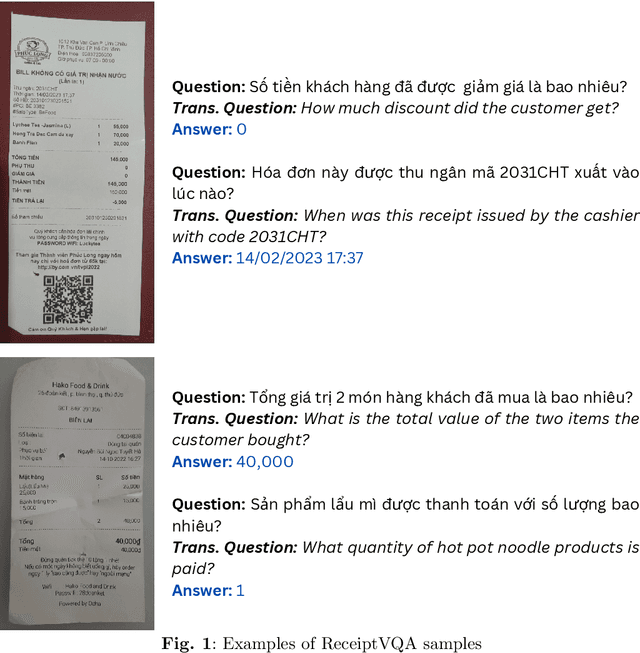
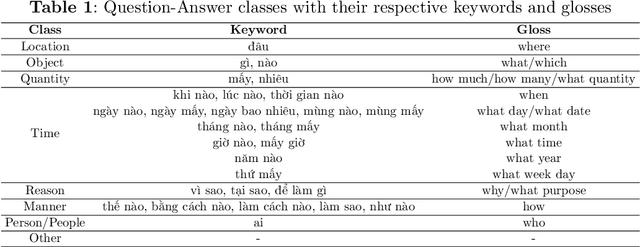
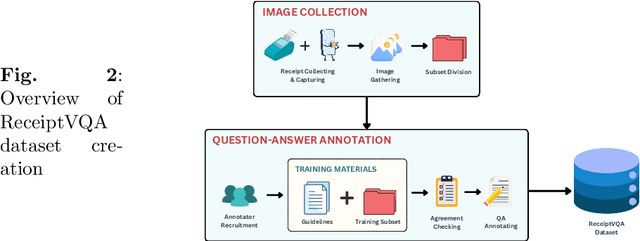

\textbf{Purpose:} Document Visual Question Answering (document VQA) challenges multimodal systems to holistically handle textual, layout, and visual modalities to provide appropriate answers. Document VQA has gained popularity in recent years due to the increasing amount of documents and the high demand for digitization. Nonetheless, most of document VQA datasets are developed in high-resource languages such as English. \textbf{Methods:} In this paper, we present ReceiptVQA (\textbf{Receipt} \textbf{V}isual \textbf{Q}uestion \textbf{A}nswering), the initial large-scale document VQA dataset in Vietnamese dedicated to receipts, a document kind with high commercial potentials. The dataset encompasses \textbf{9,000+} receipt images and \textbf{60,000+} manually annotated question-answer pairs. In addition to our study, we introduce LiGT (\textbf{L}ayout-\textbf{i}nfused \textbf{G}enerative \textbf{T}ransformer), a layout-aware encoder-decoder architecture designed to leverage embedding layers of language models to operate layout embeddings, minimizing the use of additional neural modules. \textbf{Results:} Experiments on ReceiptVQA show that our architecture yielded promising performance, achieving competitive results compared with outstanding baselines. Furthermore, throughout analyzing experimental results, we found evident patterns that employing encoder-only model architectures has considerable disadvantages in comparison to architectures that can generate answers. We also observed that it is necessary to combine multiple modalities to tackle our dataset, despite the critical role of semantic understanding from language models. \textbf{Conclusion:} We hope that our work will encourage and facilitate future development in Vietnamese document VQA, contributing to a diverse multimodal research community in the Vietnamese language.
ViConsFormer: Constituting Meaningful Phrases of Scene Texts using Transformer-based Method in Vietnamese Text-based Visual Question Answering
Oct 24, 2024
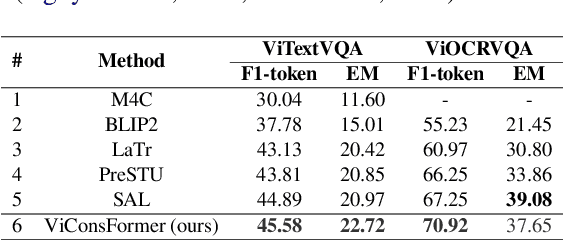
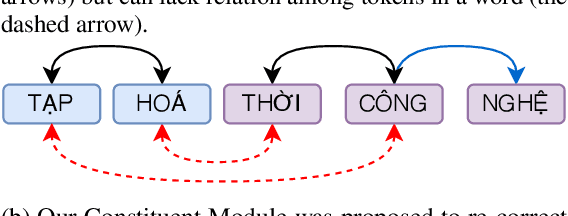
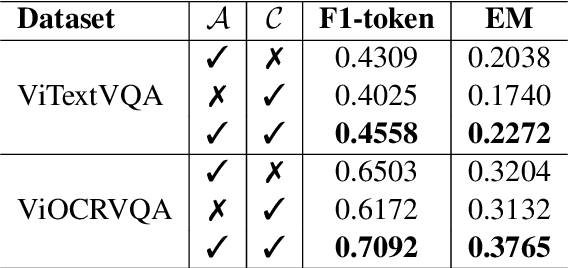
Text-based VQA is a challenging task that requires machines to use scene texts in given images to yield the most appropriate answer for the given question. The main challenge of text-based VQA is exploiting the meaning and information from scene texts. Recent studies tackled this challenge by considering the spatial information of scene texts in images via embedding 2D coordinates of their bounding boxes. In this study, we follow the definition of meaning from linguistics to introduce a novel method that effectively exploits the information from scene texts written in Vietnamese. Experimental results show that our proposed method obtains state-of-the-art results on two large-scale Vietnamese Text-based VQA datasets. The implementation can be found at this link.
ViOCRVQA: Novel Benchmark Dataset and Vision Reader for Visual Question Answering by Understanding Vietnamese Text in Images
Apr 29, 2024



Optical Character Recognition - Visual Question Answering (OCR-VQA) is the task of answering text information contained in images that have just been significantly developed in the English language in recent years. However, there are limited studies of this task in low-resource languages such as Vietnamese. To this end, we introduce a novel dataset, ViOCRVQA (Vietnamese Optical Character Recognition - Visual Question Answering dataset), consisting of 28,000+ images and 120,000+ question-answer pairs. In this dataset, all the images contain text and questions about the information relevant to the text in the images. We deploy ideas from state-of-the-art methods proposed for English to conduct experiments on our dataset, revealing the challenges and difficulties inherent in a Vietnamese dataset. Furthermore, we introduce a novel approach, called VisionReader, which achieved 0.4116 in EM and 0.6990 in the F1-score on the test set. Through the results, we found that the OCR system plays a very important role in VQA models on the ViOCRVQA dataset. In addition, the objects in the image also play a role in improving model performance. We open access to our dataset at link (https://github.com/qhnhynmm/ViOCRVQA.git) for further research in OCR-VQA task in Vietnamese.
ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images
Apr 16, 2024



Visual Question Answering (VQA) is a complicated task that requires the capability of simultaneously processing natural language and images. Initially, this task was researched, focusing on methods to help machines understand objects and scene contexts in images. However, some text appearing in the image that carries explicit information about the full content of the image is not mentioned. Along with the continuous development of the AI era, there have been many studies on the reading comprehension ability of VQA models in the world. As a developing country, conditions are still limited, and this task is still open in Vietnam. Therefore, we introduce the first large-scale dataset in Vietnamese specializing in the ability to understand text appearing in images, we call it ViTextVQA (\textbf{Vi}etnamese \textbf{Text}-based \textbf{V}isual \textbf{Q}uestion \textbf{A}nswering dataset) which contains \textbf{over 16,000} images and \textbf{over 50,000} questions with answers. Through meticulous experiments with various state-of-the-art models, we uncover the significance of the order in which tokens in OCR text are processed and selected to formulate answers. This finding helped us significantly improve the performance of the baseline models on the ViTextVQA dataset. Our dataset is available at this \href{https://github.com/minhquan6203/ViTextVQA-Dataset}{link} for research purposes.
PAT: Parallel Attention Transformer for Visual Question Answering in Vietnamese
Jul 17, 2023
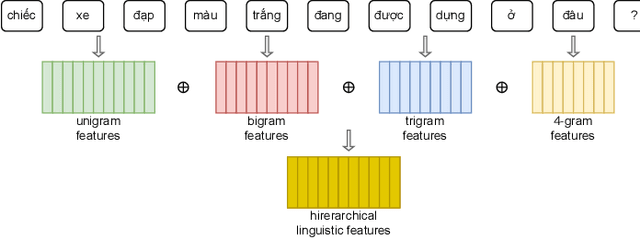


We present in this paper a novel scheme for multimodal learning named the Parallel Attention mechanism. In addition, to take into account the advantages of grammar and context in Vietnamese, we propose the Hierarchical Linguistic Features Extractor instead of using an LSTM network to extract linguistic features. Based on these two novel modules, we introduce the Parallel Attention Transformer (PAT), achieving the best accuracy compared to all baselines on the benchmark ViVQA dataset and other SOTA methods including SAAA and MCAN.
UIT-OpenViIC: A Novel Benchmark for Evaluating Image Captioning in Vietnamese
May 09, 2023
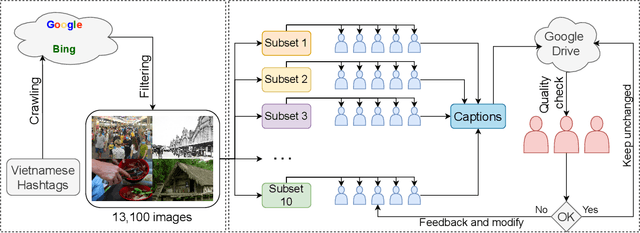
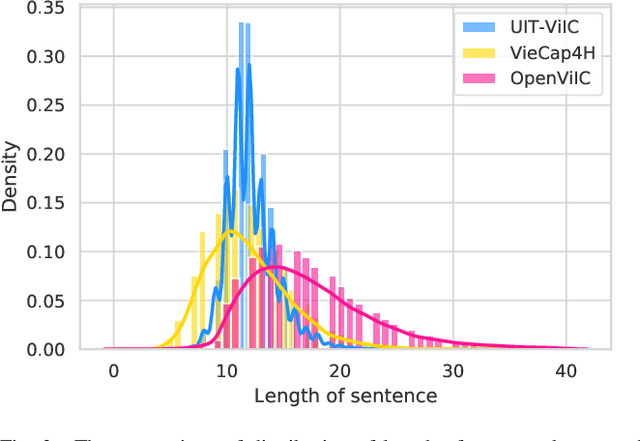
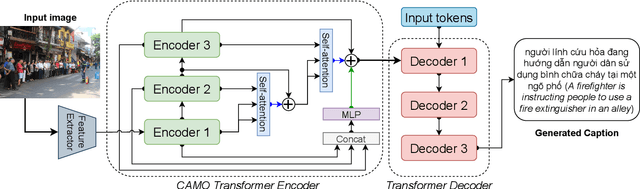
Image Captioning is one of the vision-language tasks that still interest the research community worldwide in the 2020s. MS-COCO Caption benchmark is commonly used to evaluate the performance of advanced captioning models, although it was published in 2015. Recent captioning models trained on the MS-COCO Caption dataset only have good performance in language patterns of English; they do not have such good performance in contexts captured in Vietnam or fluently caption images using Vietnamese. To contribute to the low-resources research community as in Vietnam, we introduce a novel image captioning dataset in Vietnamese, the Open-domain Vietnamese Image Captioning dataset (UIT-OpenViIC). The introduced dataset includes complex scenes captured in Vietnam and manually annotated by Vietnamese under strict rules and supervision. In this paper, we present in more detail the dataset creation process. From preliminary analysis, we show that our dataset is challenging to recent state-of-the-art (SOTA) Transformer-based baselines, which performed well on the MS COCO dataset. Then, the modest results prove that UIT-OpenViIC has room to grow, which can be one of the standard benchmarks in Vietnamese for the research community to evaluate their captioning models. Furthermore, we present a CAMO approach that effectively enhances the image representation ability by a multi-level encoder output fusion mechanism, which helps improve the quality of generated captions compared to previous captioning models.
OpenViVQA: Task, Dataset, and Multimodal Fusion Models for Visual Question Answering in Vietnamese
May 07, 2023



In recent years, visual question answering (VQA) has attracted attention from the research community because of its highly potential applications (such as virtual assistance on intelligent cars, assistant devices for blind people, or information retrieval from document images using natural language as queries) and challenge. The VQA task requires methods that have the ability to fuse the information from questions and images to produce appropriate answers. Neural visual question answering models have achieved tremendous growth on large-scale datasets which are mostly for resource-rich languages such as English. However, available datasets narrow the VQA task as the answers selection task or answer classification task. We argue that this form of VQA is far from human ability and eliminates the challenge of the answering aspect in the VQA task by just selecting answers rather than generating them. In this paper, we introduce the OpenViVQA (Open-domain Vietnamese Visual Question Answering) dataset, the first large-scale dataset for VQA with open-ended answers in Vietnamese, consists of 11,000+ images associated with 37,000+ question-answer pairs (QAs). Moreover, we proposed FST, QuMLAG, and MLPAG which fuse information from images and answers, then use these fused features to construct answers as humans iteratively. Our proposed methods achieve results that are competitive with SOTA models such as SAAA, MCAN, LORA, and M4C. The dataset is available to encourage the research community to develop more generalized algorithms including transformers for low-resource languages such as Vietnamese.
VLSP2022-EVJVQA Challenge: Multilingual Visual Question Answering
Feb 28, 2023Visual Question Answering (VQA) is a challenging task of natural language processing (NLP) and computer vision (CV), attracting significant attention from researchers. English is a resource-rich language that has witnessed various developments in datasets and models for visual question answering. Visual question answering in other languages also would be developed for resources and models. In addition, there is no multilingual dataset targeting the visual content of a particular country with its own objects and cultural characteristics. To address the weakness, we provide the research community with a benchmark dataset named EVJVQA, including 33,000+ pairs of question-answer over three languages: Vietnamese, English, and Japanese, on approximately 5,000 images taken from Vietnam for evaluating multilingual VQA systems or models. EVJVQA is used as a benchmark dataset for the challenge of multilingual visual question answering at the 9th Workshop on Vietnamese Language and Speech Processing (VLSP 2022). This task attracted 62 participant teams from various universities and organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 0.4392 in F1-score and 0.4009 in BLUE on the private test set. The multilingual QA systems proposed by the top 2 teams use ViT for the pre-trained vision model and mT5 for the pre-trained language model, a powerful pre-trained language model based on the transformer architecture. EVJVQA is a challenging dataset that motivates NLP and CV researchers to further explore the multilingual models or systems for visual question answering systems.
VieCap4H-VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 12, 2022



Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
UIT-HWDB: Using Transferring Method to Construct A Novel Benchmark for Evaluating Unconstrained Handwriting Image Recognition in Vietnamese
Nov 10, 2022


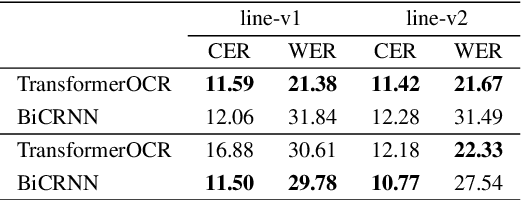
Recognizing handwriting images is challenging due to the vast variation in writing style across many people and distinct linguistic aspects of writing languages. In Vietnamese, besides the modern Latin characters, there are accent and letter marks together with characters that draw confusion to state-of-the-art handwriting recognition methods. Moreover, as a low-resource language, there are not many datasets for researching handwriting recognition in Vietnamese, which makes handwriting recognition in this language have a barrier for researchers to approach. Recent works evaluated offline handwriting recognition methods in Vietnamese using images from an online handwriting dataset constructed by connecting pen stroke coordinates without further processing. This approach obviously can not measure the ability of recognition methods effectively, as it is trivial and may be lack of features that are essential in offline handwriting images. Therefore, in this paper, we propose the Transferring method to construct a handwriting image dataset that associates crucial natural attributes required for offline handwriting images. Using our method, we provide a first high-quality synthetic dataset which is complex and natural for efficiently evaluating handwriting recognition methods. In addition, we conduct experiments with various state-of-the-art methods to figure out the challenge to reach the solution for handwriting recognition in Vietnamese.