 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenViVQA: Task, Dataset, and Multimodal Fusion Models for Visual Question Answering in Vietnamese
May 07, 2023



In recent years, visual question answering (VQA) has attracted attention from the research community because of its highly potential applications (such as virtual assistance on intelligent cars, assistant devices for blind people, or information retrieval from document images using natural language as queries) and challenge. The VQA task requires methods that have the ability to fuse the information from questions and images to produce appropriate answers. Neural visual question answering models have achieved tremendous growth on large-scale datasets which are mostly for resource-rich languages such as English. However, available datasets narrow the VQA task as the answers selection task or answer classification task. We argue that this form of VQA is far from human ability and eliminates the challenge of the answering aspect in the VQA task by just selecting answers rather than generating them. In this paper, we introduce the OpenViVQA (Open-domain Vietnamese Visual Question Answering) dataset, the first large-scale dataset for VQA with open-ended answers in Vietnamese, consists of 11,000+ images associated with 37,000+ question-answer pairs (QAs). Moreover, we proposed FST, QuMLAG, and MLPAG which fuse information from images and answers, then use these fused features to construct answers as humans iteratively. Our proposed methods achieve results that are competitive with SOTA models such as SAAA, MCAN, LORA, and M4C. The dataset is available to encourage the research community to develop more generalized algorithms including transformers for low-resource languages such as Vietnamese.
VieCap4H-VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 12, 2022



Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
UIT-HWDB: Using Transferring Method to Construct A Novel Benchmark for Evaluating Unconstrained Handwriting Image Recognition in Vietnamese
Nov 10, 2022


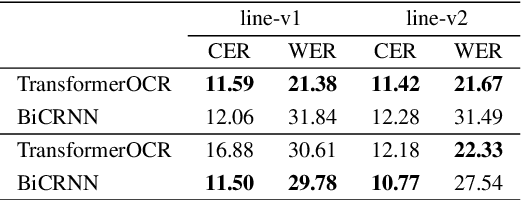
Recognizing handwriting images is challenging due to the vast variation in writing style across many people and distinct linguistic aspects of writing languages. In Vietnamese, besides the modern Latin characters, there are accent and letter marks together with characters that draw confusion to state-of-the-art handwriting recognition methods. Moreover, as a low-resource language, there are not many datasets for researching handwriting recognition in Vietnamese, which makes handwriting recognition in this language have a barrier for researchers to approach. Recent works evaluated offline handwriting recognition methods in Vietnamese using images from an online handwriting dataset constructed by connecting pen stroke coordinates without further processing. This approach obviously can not measure the ability of recognition methods effectively, as it is trivial and may be lack of features that are essential in offline handwriting images. Therefore, in this paper, we propose the Transferring method to construct a handwriting image dataset that associates crucial natural attributes required for offline handwriting images. Using our method, we provide a first high-quality synthetic dataset which is complex and natural for efficiently evaluating handwriting recognition methods. In addition, we conduct experiments with various state-of-the-art methods to figure out the challenge to reach the solution for handwriting recognition in Vietnamese.