 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSC2025 -- ViHallu Challenge: Detecting Hallucination in Vietnamese LLMs
Jan 08, 2026The reliability of large language models (LLMs) in production environments remains significantly constrained by their propensity to generate hallucinations--fluent, plausible-sounding outputs that contradict or fabricate information. While hallucination detection has recently emerged as a priority in English-centric benchmarks, low-to-medium resource languages such as Vietnamese remain inadequately covered by standardized evaluation frameworks. This paper introduces the DSC2025 ViHallu Challenge, the first large-scale shared task for detecting hallucinations in Vietnamese LLMs. We present the ViHallu dataset, comprising 10,000 annotated triplets of (context, prompt, response) samples systematically partitioned into three hallucination categories: no hallucination, intrinsic, and extrinsic hallucinations. The dataset incorporates three prompt types--factual, noisy, and adversarial--to stress-test model robustness. A total of 111 teams participated, with the best-performing system achieving a macro-F1 score of 84.80\%, compared to a baseline encoder-only score of 32.83\%, demonstrating that instruction-tuned LLMs with structured prompting and ensemble strategies substantially outperform generic architectures. However, the gap to perfect performance indicates that hallucination detection remains a challenging problem, particularly for intrinsic (contradiction-based) hallucinations. This work establishes a rigorous benchmark and explores a diverse range of detection methodologies, providing a foundation for future research into the trustworthiness and reliability of Vietnamese language AI systems.
VLSP 2025 MLQA-TSR Challenge: Vietnamese Multimodal Legal Question Answering on Traffic Sign Regulation
Oct 23, 2025This paper presents the VLSP 2025 MLQA-TSR - the multimodal legal question answering on traffic sign regulation shared task at VLSP 2025. VLSP 2025 MLQA-TSR comprises two subtasks: multimodal legal retrieval and multimodal question answering. The goal is to advance research on Vietnamese multimodal legal text processing and to provide a benchmark dataset for building and evaluating intelligent systems in multimodal legal domains, with a focus on traffic sign regulation in Vietnam. The best-reported results on VLSP 2025 MLQA-TSR are an F2 score of 64.55% for multimodal legal retrieval and an accuracy of 86.30% for multimodal question answering.
ViFactCheck: A New Benchmark Dataset and Methods for Multi-domain News Fact-Checking in Vietnamese
Dec 19, 2024
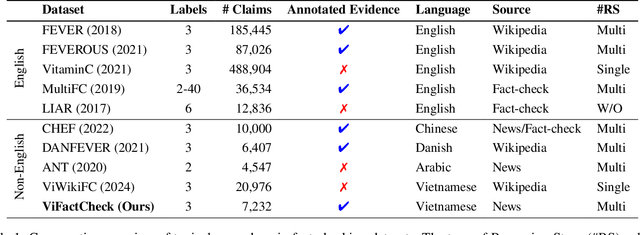
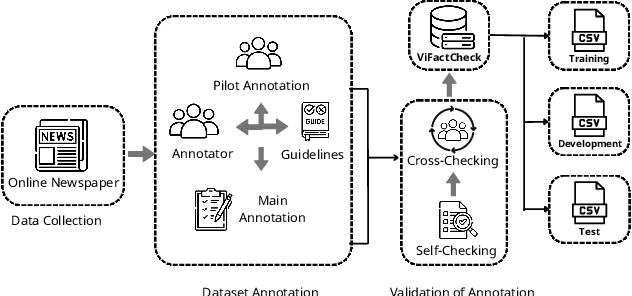
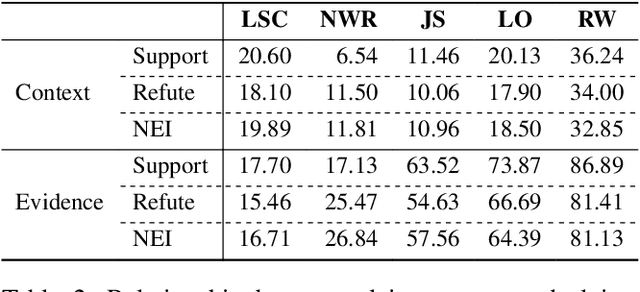
The rapid spread of information in the digital age highlights the critical need for effective fact-checking tools, particularly for languages with limited resources, such as Vietnamese. In response to this challenge, we introduce ViFactCheck, the first publicly available benchmark dataset designed specifically for Vietnamese fact-checking across multiple online news domains. This dataset contains 7,232 human-annotated pairs of claim-evidence combinations sourced from reputable Vietnamese online news, covering 12 diverse topics. It has been subjected to a meticulous annotation process to ensure high quality and reliability, achieving a Fleiss Kappa inter-annotator agreement score of 0.83. Our evaluation leverages state-of-the-art pre-trained and large language models, employing fine-tuning and prompting techniques to assess performance. Notably, the Gemma model demonstrated superior effectiveness, with an impressive macro F1 score of 89.90%, thereby establishing a new standard for fact-checking benchmarks. This result highlights the robust capabilities of Gemma in accurately identifying and verifying facts in Vietnamese. To further promote advances in fact-checking technology and improve the reliability of digital media, we have made the ViFactCheck dataset, model checkpoints, fact-checking pipelines, and source code freely available on GitHub. This initiative aims to inspire further research and enhance the accuracy of information in low-resource languages.
R2GQA: Retriever-Reader-Generator Question Answering System to Support Students Understanding Legal Regulations in Higher Education
Sep 04, 2024
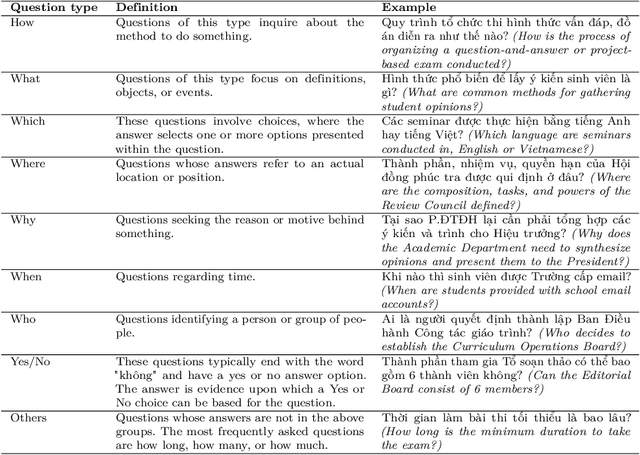


In this article, we propose the R2GQA system, a Retriever-Reader-Generator Question Answering system, consisting of three main components: Document Retriever, Machine Reader, and Answer Generator. The Retriever module employs advanced information retrieval techniques to extract the context of articles from a dataset of legal regulation documents. The Machine Reader module utilizes state-of-the-art natural language understanding algorithms to comprehend the retrieved documents and extract answers. Finally, the Generator module synthesizes the extracted answers into concise and informative responses to questions of students regarding legal regulations. Furthermore, we built the ViRHE4QA dataset in the domain of university training regulations, comprising 9,758 question-answer pairs with a rigorous construction process. This is the first Vietnamese dataset in the higher regulations domain with various types of answers, both extractive and abstractive. In addition, the R2GQA system is the first system to offer abstractive answers in Vietnamese. This paper discusses the design and implementation of each module within the R2GQA system on the ViRHE4QA dataset, highlighting their functionalities and interactions. Furthermore, we present experimental results demonstrating the effectiveness and utility of the proposed system in supporting the comprehension of students of legal regulations in higher education settings. In general, the R2GQA system and the ViRHE4QA dataset promise to contribute significantly to related research and help students navigate complex legal documents and regulations, empowering them to make informed decisions and adhere to institutional policies effectively. Our dataset is available for research purposes.
VLSP2022-EVJVQA Challenge: Multilingual Visual Question Answering
Feb 28, 2023Visual Question Answering (VQA) is a challenging task of natural language processing (NLP) and computer vision (CV), attracting significant attention from researchers. English is a resource-rich language that has witnessed various developments in datasets and models for visual question answering. Visual question answering in other languages also would be developed for resources and models. In addition, there is no multilingual dataset targeting the visual content of a particular country with its own objects and cultural characteristics. To address the weakness, we provide the research community with a benchmark dataset named EVJVQA, including 33,000+ pairs of question-answer over three languages: Vietnamese, English, and Japanese, on approximately 5,000 images taken from Vietnam for evaluating multilingual VQA systems or models. EVJVQA is used as a benchmark dataset for the challenge of multilingual visual question answering at the 9th Workshop on Vietnamese Language and Speech Processing (VLSP 2022). This task attracted 62 participant teams from various universities and organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 0.4392 in F1-score and 0.4009 in BLUE on the private test set. The multilingual QA systems proposed by the top 2 teams use ViT for the pre-trained vision model and mT5 for the pre-trained language model, a powerful pre-trained language model based on the transformer architecture. EVJVQA is a challenging dataset that motivates NLP and CV researchers to further explore the multilingual models or systems for visual question answering systems.
ViHOS: Hate Speech Spans Detection for Vietnamese
Jan 26, 2023The rise in hateful and offensive language directed at other users is one of the adverse side effects of the increased use of social networking platforms. This could make it difficult for human moderators to review tagged comments filtered by classification systems. To help address this issue, we present the ViHOS (Vietnamese Hate and Offensive Spans) dataset, the first human-annotated corpus containing 26k spans on 11k comments. We also provide definitions of hateful and offensive spans in Vietnamese comments as well as detailed annotation guidelines. Besides, we conduct experiments with various state-of-the-art models. Specifically, XLM-R$_{Large}$ achieved the best F1-scores in Single span detection and All spans detection, while PhoBERT$_{Large}$ obtained the highest in Multiple spans detection. Finally, our error analysis demonstrates the difficulties in detecting specific types of spans in our data for future research. Disclaimer: This paper contains real comments that could be considered profane, offensive, or abusive.