 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViHOS: Hate Speech Spans Detection for Vietnamese
Jan 26, 2023The rise in hateful and offensive language directed at other users is one of the adverse side effects of the increased use of social networking platforms. This could make it difficult for human moderators to review tagged comments filtered by classification systems. To help address this issue, we present the ViHOS (Vietnamese Hate and Offensive Spans) dataset, the first human-annotated corpus containing 26k spans on 11k comments. We also provide definitions of hateful and offensive spans in Vietnamese comments as well as detailed annotation guidelines. Besides, we conduct experiments with various state-of-the-art models. Specifically, XLM-R$_{Large}$ achieved the best F1-scores in Single span detection and All spans detection, while PhoBERT$_{Large}$ obtained the highest in Multiple spans detection. Finally, our error analysis demonstrates the difficulties in detecting specific types of spans in our data for future research. Disclaimer: This paper contains real comments that could be considered profane, offensive, or abusive.
Vietnamese Hate and Offensive Detection using PhoBERT-CNN and Social Media Streaming Data
Jun 01, 2022

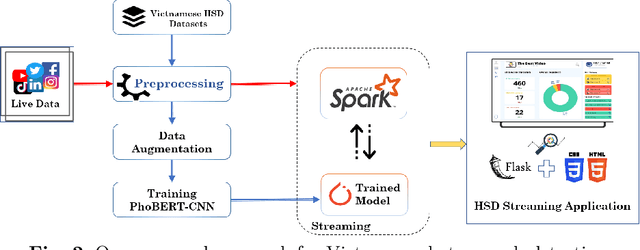

Society needs to develop a system to detect hate and offense to build a healthy and safe environment. However, current research in this field still faces four major shortcomings, including deficient pre-processing techniques, indifference to data imbalance issues, modest performance models, and lacking practical applications. This paper focused on developing an intelligent system capable of addressing these shortcomings. Firstly, we proposed an efficient pre-processing technique to clean comments collected from Vietnamese social media. Secondly, a novel hate speech detection (HSD) model, which is the combination of a pre-trained PhoBERT model and a Text-CNN model, was proposed for solving tasks in Vietnamese. Thirdly, EDA techniques are applied to deal with imbalanced data to improve the performance of classification models. Besides, various experiments were conducted as baselines to compare and investigate the proposed model's performance against state-of-the-art methods. The experiment results show that the proposed PhoBERT-CNN model outperforms SOTA methods and achieves an F1-score of 67,46% and 98,45% on two benchmark datasets, ViHSD and HSD-VLSP, respectively. Finally, we also built a streaming HSD application to demonstrate the practicality of our proposed system.